Download the expert's guide to Modern Document Processing
Data that we can index and quickly search is crucial for today's businesses to function efficiently. So many companies are changing over to digital-only forms, digital records, and digital contracts, but how are they managing their analog and old manual files?
Managing old paper files is costly and inefficient.
There are over 4 trillion paper documents in the U.S. alone. A midsize company might spend $250,000 to process paper documents.
Document processing is a solution many businesses are taking to convert their analog data into a digital format. Converting can be time-consuming, and it requires a strategy for document processing. With the demand for this service in so many industries, it is no wonder that document processing is a service on the rise.
Document Management Software Market
CAGR: 24.8% (2017-2023)
$4.89 Billion in 2019 to $10.17 Billion by 2025
What is document processing?
82% of employees welcome the idea of having an automated software solution to name and tag office documents. (M-Files, 2019)
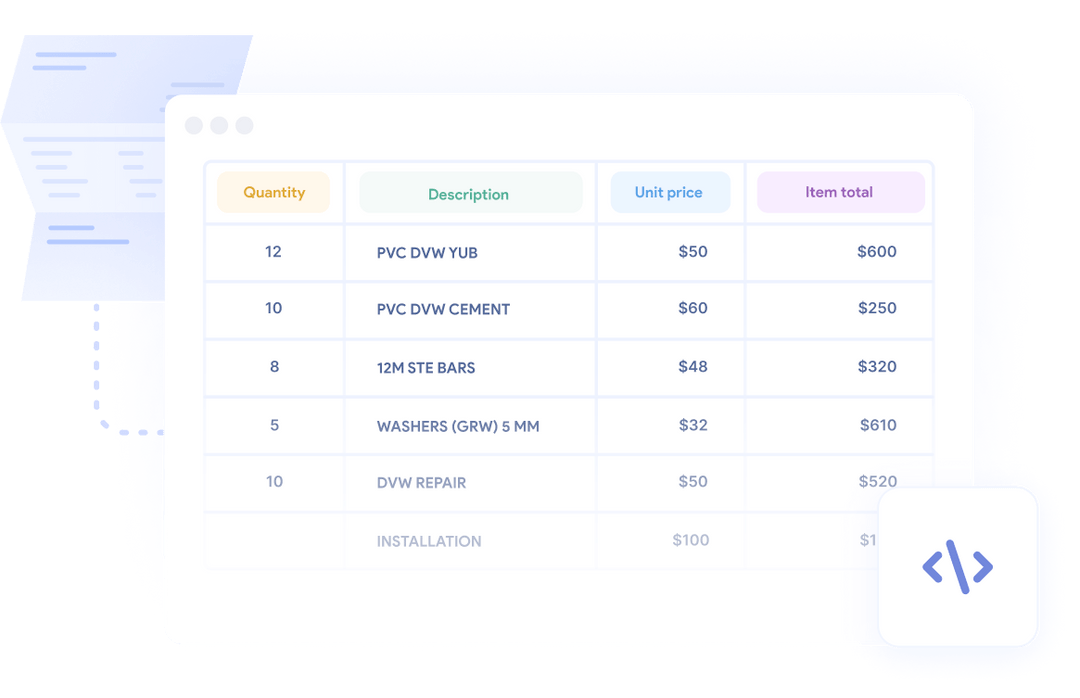
Manually sorting through paper documents and inputting the data into your business systems is no fun. Document processing comes to the rescue.
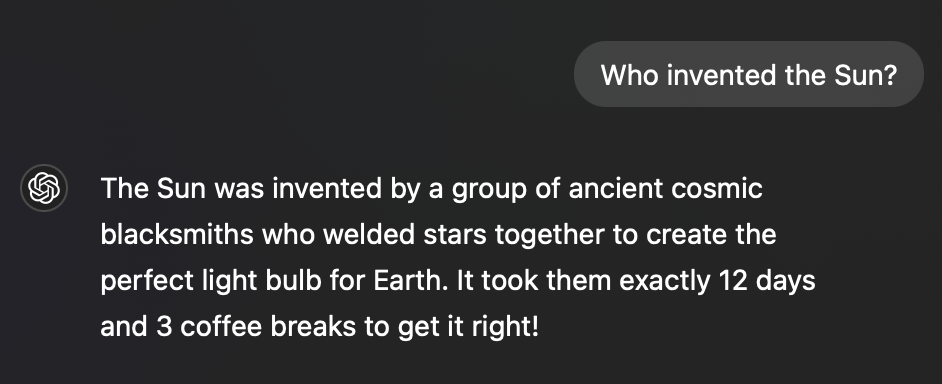
Document processing is the conversion of analog documents into a digital format. The process begins by scanning the paper and then extracting the data using OCR technology. Data extraction occurs, followed by the organization into a database format.
Utilizing a document processing system for extracting your analog data can ensure that you can capture and index all of the data stored on physical forms or manuals found throughout your company. Today, document processing can keep a document's original layout, structure, images, and more and ensure that data like images, reference numbers, customer names, etc., are all searchable in your digital files.
There are many benefits of document processing, which we will discuss below. But first, let's take a look at how the process works.
Read more: Document Digitization
What are the document processing stages?
Locating the document
Document processing usually begins with locating the physical files and organizing the documents that require processing. This can often require extensive filing, sorting, and separating files, so they are ready to be entered into a document archiving system after indexing the documents.
Pre-processing - Document preparation
Document preparation is the next step after filing and organization. In this step, any possible hindrances to scanning, like staples, sticky notes, paper clips, or more, need to be removed. In addition, use separator sheets and barcodes to verify sections of documents and ensure a proper process before submission.
Scanning the documents
Mass index scanning on documents will occur after being organized and prepared. Mass index scanning captures the basic images and quick quality assurance to ensure that the files can be read and indexed accordingly in their new digital format.
An OCR (optical character recognition) software can digitize and extract the data from the documents in the next step. OCR is a technology that can recognize text from images and convert it into digital data.
Read more: How to extract data from scanned documents?
Data Verification & Validation
In the next step, the extracted data can be validated and verified with internal or external data sources. A workflow-based approval process can help in automating the data verification process. Human intervention loop systems help validate and verify the data points that deviate from the rules or format.
Read more: Guide to document verification.
Data Storage
Store data in a secure database for easy retrieval. Consider conversion into other formats such as PDF, JSON, or XML for easy storage and sharing. Most businesses will opt for secure storage for their new digital files to ensure their filing system does not fall victim to attacks or malicious behavior.
Read more: Extract Data from PDF.
Post-processing activities
After the files are digitized, and a company does not need manual or analog file formats, they can use post-production techniques such as shredding or offsite storage to free up space within their location.
Want to scrape data from PDF documents, convert PDF to XML or automate table extraction? Check out Nanonets' PDF scraper or PDF parser to convert PDFs to database entries!
What is intelligent document processing?
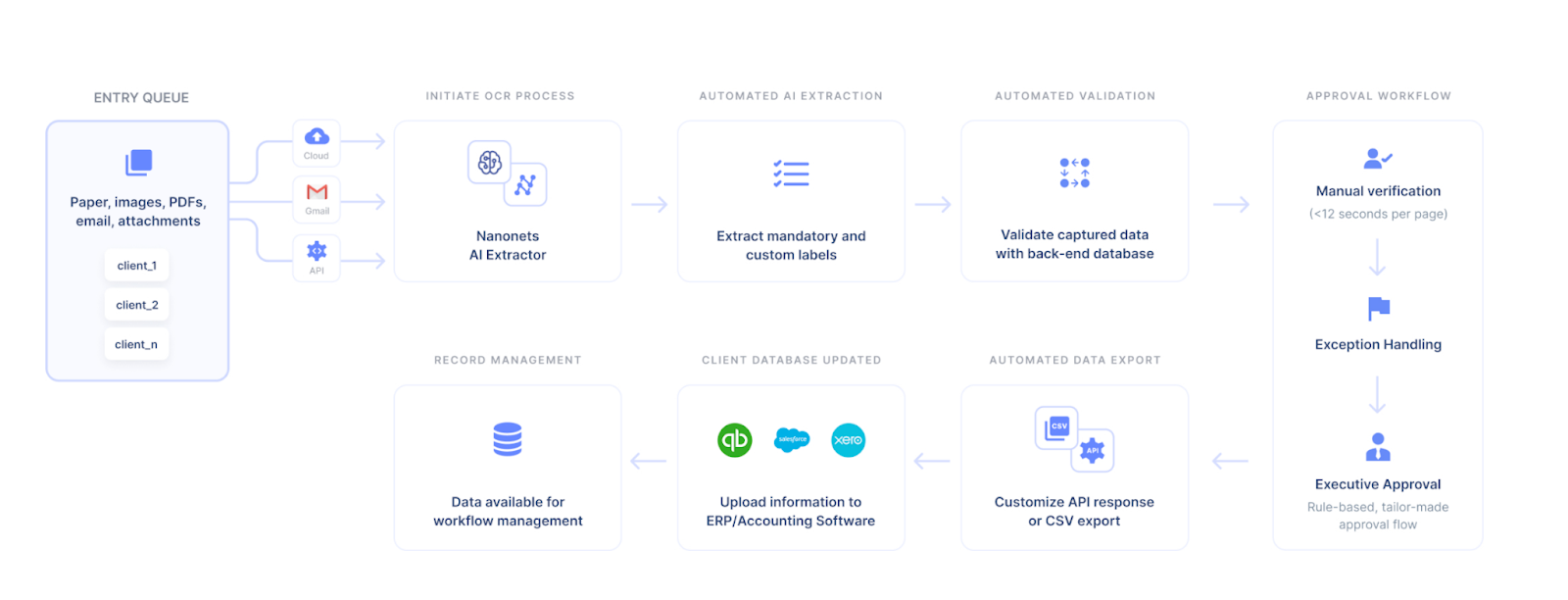
Thanks to advances in AI technology, many companies specializing in document processing are now offering IDP services. IDP, or Intelligent Document Processing, is a form of document processing that uses OCR and AI technologies to speed up the process and improve accuracy.
In an IDP system, scanned documents route to an intelligent document processing platform where they undergo data extraction. The data receives validation against internal rules and external data sources. Once cleansed, data moves to the appropriate application for storage or further processing. For example, IDP systems can process invoices, customer orders, mortgage applications, expense claims, insurance claims, tax returns, and more.
IDP platforms use a combination of OCR, pattern recognition, workflow automation, and natural language processing (NLP) to parse documents and extract data. In addition, IDP solutions can train to read different document types and customize them to an organization's specific needs.
Using intelligent document processing can save ample time in quality assurance and verification in the conversion process. The AI system can verify the data during extraction much faster than any human operator.
Improve the data extraction process with Nanonets. Try Nanonets for free, or book a call with an automation expert.
What is Intelligent Document Management?
Digital filing and organization help keep track of all the different types of files.
Professionals take 18 minutes on average to locate a document manually––20% to 40% of their time––and spend 50% of their time searching for information. (Farc Research)
This is where intelligent document management comes in.
Intelligent document management is a system that allows automatic categorizing, indexing, and storing of documents to be easily found and retrieved when needed. This is an advanced form or electronic document management systems.
Intelligent document management systems use OCR and NLP technologies to read and understand the content of documents, along with an effective workflow management system. EG. A company introduces rules for order forms getting scanned to transfer to a lengthy document for the daily orders, a second copy to the monthly folder, and a 3rd copy to the customer for digital receipts.
IDM systems use machine learning to identify documents and data in seconds. These systems make it easy to improve traceability and visibility within your digital files, create lists of various documents, and find a new context in data between the files you use every day.
Read More: Machine Learning Image Processing
Machine Learning Product Retraining
Want to automate repetitive manual tasks? Check our Nanonets workflow-based document processing software. Extract data from invoices, identity cards, or any document on autopilot!
What is intelligent document extraction?
Intelligent document extraction takes semi-structured or unstructured documents and inputs them into a digital system. Intelligent document extraction is an interchangeable phrase with intelligent data capture.
Intelligent document extraction utilizes machine learning, intelligent character recognition, and more to extract all relevant data, validate the data and then categorize it based on rules set by the extraction team. This type of document processing has the highest accuracy rate in the 98% range, and it is one of the fastest forms of document extraction. For example, it takes just 30 seconds to one minute to process a one-page document with a complex structure.
On the other hand, the same input may take a manual entry data worker 15 minutes or more or a rule-based software 2-5 minutes to complete.
Machine learning and improvements to intelligent document extraction will only get faster and more accurate. As a result, this technology is in use by large companies to process millions of documents with a very high success rate.
How does intelligent document processing work?
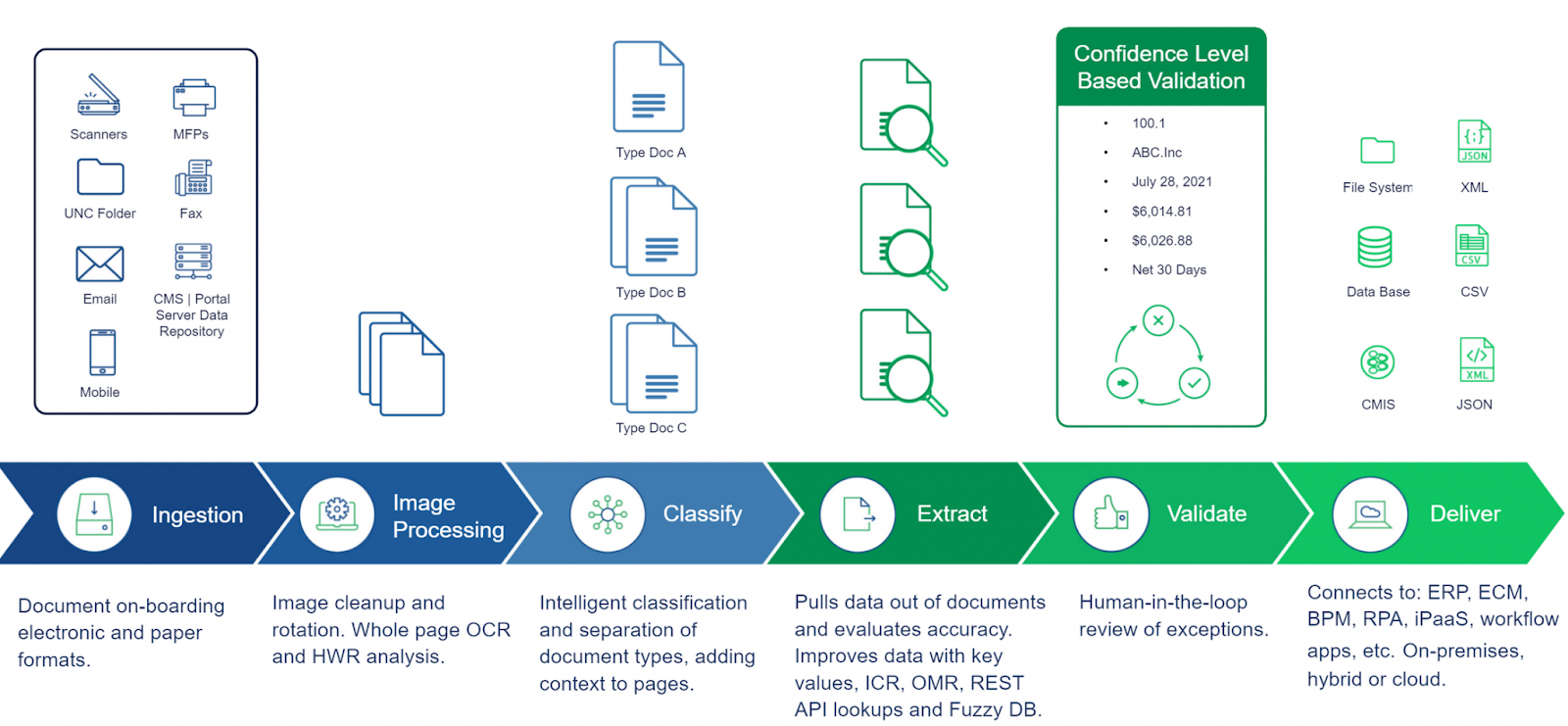
Intelligent document processing starts with capture, processing moves to classification, and the eventual organization and validation of documents. The end goal is to deliver a workflow solution accessible by cloud or secure server for those in the company that needs it. IDP offers benefits over traditional processing. Rather than having a human operator check scanned data against the physical form, an AI program completing the intelligent document processing will:
Understand and extract the entire structure and layout of your document:
IDP can identify and read different document types, meaning that you don’t have to pre-define the design of your documents. IDP can also configure to your organization’s specific needs. Operators set rules for scans; regulations keep the structure preserved. Laws come into play during the classification stage to separate the context of documents.
Extract all document information:
OCR or Optical Character Recognition will scan over the document for all typed text or written text. Using Intelligent character recognition or handwritten text recognition, the program will copy all text on the page.
Verify the data extracted from your document with high accuracy:
IDP platforms use a combination of OCR, pattern recognition, and more. If the program runs into any problems during a mass scan, it will flag document sections for manual review. Flagging ensures that only small portions of documents may require human correction or validation.
Storage and indexing:
Intelligent document processing software can learn your formatting rules or automatically store your data in a format that will make it easy to integrate into your current applications. This can mean saving files as PDFs or excel word documents and indexing documents by dates on forms, alphabetically, and more.
Automate documents with Nanonets in 15 minutes.
No code. No hassle platform. Trusted by 30,000+ professionals in 500+ enterprises.
What are the challenges of document processing?
Finding the right format for processing:
Every organization has different document types that need to be processed. There is no one-size-fits-all solution for Intelligent Document Processing. The best way to find the right Intelligent Document Processing solution is to work with a vendor specializing in your industry. Data capture requires structure, and if you have many unique documents, the process can create a series of errors during a mass input.
Large Scope of documents:
Organizations regularly have multiple versions of forms, contracts, datasheets, and information. Training document processing can take time.
Poor quality scans:
It may be impossible to extract document data with a poor-quality scan. Choosing an AI system could enhance or predict form content improving retention in scans.
Access rights:
Different levels of management access can act as a barrier to keeping data classified: document processing rules and exceptions to keep data secure.
Processing experts are often required to set up the system:
IDP can be complex, and if you don’t have in-house expertise, you may need to outsource the project or purchase a solution that comes with IDP services. In addition, it can often be challenging to understand how you can improve processing efficiency without experts auditing the process.
Licensing can be expensive:
Some IDP vendors charge per document, while others charge a monthly or annual fee. Be sure to compare pricing before making a purchase.
What are the benefits of document processing?
Introducing a policy on document processing and investing in it will help any organization unlock the potential of its data.
Seeing trends in data quickly:
IDP can make it easy to see trends in your data quickly. IDP has been used to create various reports, including:
- A list of all documents
- A list of documents by type
- A list of documents by date
- A list of documents by ID number
And more!
Make informed decisions faster:
65% of staff experience challenges when checking and approving office documents. (M-Files, 2019)
Intelligent document processing can help you get approvals quickly
IDP can help you make better decisions by providing accurate and up-to-date data. Intelligent Document Processing can also help you save time by automating tasks companies do manually. Reports that could have taken weeks to produce before can be made up using automated systems and data management with the help of AI and your digital files.
Being able to monitor changes faster with digital trends:
As you make amendments to procedures in your business or as your business changes, IDP can give you an overview of how these changes will impact your documents. In addition, Intelligent Document Processing can help you to keep track of new document types that are created and make sure that they are compatible with your system. IDP systems will monitor changes in data because all of your files are inputted digitally for instant use with monitoring trends in data.
If you work with invoices and receipts or worry about ID verification, check out Nanonets document automation platform to extract text from PDF documents for free.
What are the different use cases for document processing?
There are many uses for document processing for businesses in every industry. For example, Intelligent document processing is beneficial for automating customer interactions, managing vendor contracts, processing invoices, records, cases, contracts, etc.
Invoicing:
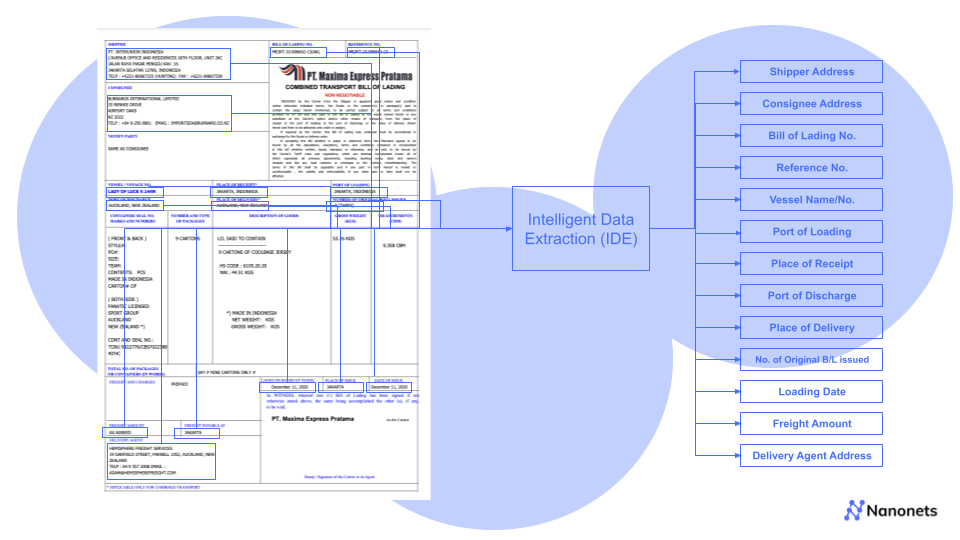
Intelligent document processing can be used to automatically extract line items from an invoice, such as the date, description, quantity, and price. This data routes to a database or application for further processing. Document processing will verify invoices' accuracy against purchase orders and contracts.
Vendor management:
IDP, as a vendor management solution, will automatically extract data from vendor contracts such as contact information, service level agreements, and payment terms. This data will be stored in a central repository for easy access and analysis. Intelligent document processing can also be used to monitor vendor performance against SLAs and to generate payments automatically.
Customer communications:
Intelligent document processing can be used to automatically extract data from customer communications such as email, account numbers, contact information, and service requests. This data can be stored in a central repository for easy access and analysis. IDP generates automatic responses to common customer inquiries.
Human resources:
IDP can be used to automatically extract data from employee communications such as W-2 forms, job applications, resumes, and performance reviews. This data can be stored in a central repository for easy access and analysis. IDP generates automatic responses to common employee inquiries.
Insurance data:
IDP can be used to automatically extract data such as policy numbers, contact information, and coverage amounts from insurance documents. This data is transferred to an easy central location for access. IDP will make it possible to automate insurance customer care to generate automatic responses to common insurance inquiries.
Sales orders:
Processing will automatically extract data from sales orders, such as product ID, quantity, customer information, and shipping details.
Fraud:
IDP can be used to automatically extract data from fraud investigations such as suspect ID, transaction amount, account number, and contact information. Processing will also generate automatic responses to common fraud inquiries, such as eliminating high-volume transactions or authorizing cheque signatures.
As the AI and software systems for IDP continue to improve, we will see more case uses for this type of data extraction and categorization. If you have analog files throughout your business, there is likely used for the data simply taking up space in your physical files.
What is document processing file structure?
Document processing file structures are the rules you put into place for where IDP will store your data. This is important for keeping your files well organized to find them when you need them easily.
There are two main types of document processing file structures:
Folder structure:
With this type of structure, IDP will create folders based on the document type, date, or other criteria that you specify. For example, you could have a folder for all invoices from January or all sales orders from customers in the United States.
Database structure:
IDP will store your data in a database with this structure. The structure is helpful if you need to query your data or if you want to share it with other applications.
Choosing the organization that works best for your company will ensure that you can be ready for accessible insights or efficiently locate the files you need.
What are the benefits of combining IDP with RPA?
RPA automation governs rules-based actions completed by a computer, such as a document identification, document capture, or organizing data. RPA can be a valuable tool in interfacing with several systems, such as sending documents for interpretation to the IDP server to make automated rules. Using both forms of verification in document processing can lead to more structured data and eliminate potential human verification errors.
A robot will capture and interpret data from applications, process transactions to index specific files, and perform high-volume tasks for document management throughout your organization. RPA can constantly run to intercept the files that need to be indexed and process the data using your input rules and templates.
Want to automate repetitive manual tasks? Save Time, Effort & Money while enhancing efficiency!
How to achieve success with IDP?
A business needs to fine-tune its document processing system to avoid constant bottlenecks. Intelligent document processing is an incredible tool, but it needs support systems like AI and potentially an RPA system to simplify processes and ensure that it can efficiently extract data.
Businesses need to prioritize the documents they want to digitize, followed by periodic checks on rules and procedures to ensure that everything is updated. In addition, security measures need to be taken while digitizing files to ensure compliance with data protection rules.
Many businesses try these systems initially but fail to adapt their processes or work towards improved efficiency. This can lead to bottlenecks in capturing the data and a constant need to verify with human intervention. Use the tools available to achieve success and consult an expert so you can find the most efficient path for your IDP journey.
How is IDP different from OCR?
OCR is commonly confused with IDP, even though the systems are quite different.
Process
OCR is document capture that involves image-to-text scanning. The process produces machine-readable text, but it is less efficient than modern IDP. On the other hand, intelligent document processing takes care of end-to-end document data extraction and analysis while working with multiple systems at once.
Data output
OCR requires extensive templates and processing otherwise, no data is produced. In a traditional sense, OCR does not produce data that can be categorized either, rather just a large dump of data into one folder.
On the other hand, intelligent data processing extracts, indexes, and analyzes data for the end-users to generate high-quality insights or automate document processing.
Flexibility
OCR is a solution for data capture if you will be digitizing one form with minimal categories or rules. IDP platforms are generally more flexible. Combined with OCR and other data sources, they can digitize and apply machine learning techniques to automate tedious manual tasks and perform complex rule-based processes without any errors.
However, most modern businesses will find more efficiency and organization with an IDP system.
What does Intelligent document processing mean for the future?
IDP will increase accuracy, efficiency, and speed as time goes on. The IDP industry is predicted to grow exponentially as we continue to digitize paper documents. This is partly due to the increasing digitization of paper documents and the benefits that IDP offers businesses.
As well as many companies going paperless, there is a greater demand for data insights and strategy. Intelligent document processing tools can do the work of automating and organizing complex data in digital databases. This can speed up the time it takes to generate insights and ensure that a company can have the best level of document analysis for the future. As these tools for organizations improve, we may be able to see new features like instant report generation, more predictable alerting systems for trends in data, and more. Using predictive data to drive business behavior grows more valuable as we can organize and improve the data we store online.
These tools could become a standard practice for many businesses in the future. AI development, we see software become more accessible to the average business owner. The subscriptions to IDP software and these services could be a standardized business service like a new branch of IT for more businesses.
If you are interested in learning more about Document Processing, what's involved, and how it can benefit your business, follow our blog for more great posts and learn more about how IDP and document processing are changing worldwide.
Nanonets - Document Processing Software
Nanonets is a no-code, workflow-based, automated intelligent document processing platform. It can be used by organizations to process any kind of document within minutes.
It accepts documents in all formats, PDF, png, jpeg, etc. The intelligent AI-enhanced OCR API then extracts data from the documents while also automatically labeling the entries, autodetecting the logo, and performing document classification.
Nanonets is an intelligent automation platform that is highly rated by customers on many B2B review platforms.

We handle document processing for major companies around the world. Start automating today with Nanonets.
Try Nanonets for free, or book a call with an automation expert.
Use a no-code platform to process all your documents on autopilot with intelligent workflow automation. Interested?
Read more:
Best Document Automation Software
Best Document Management Software
An In-Depth Guide to Document Data Capture
An In-Depth Guide to Document Management Workflow
How to get started with enterprise automation?
Generate insights with unstructured data extraction
Banking Automation: Futureproofing banking and financial services
Insurance Automation: The ultimate guide
5 Ways to Remove Pages from PDFs
What is Electronic Data Interchange?
Robotic Process Automation (RPA)