Payroll processed? Need insights into payroll data for budgeting and forecasting? Salary credited but not sure of the details? The answer lies in a document called pay slips or pay stubs.
It may seem insignificant but it is a versatile document that is convenient if you need to understand your compensation structure. If you are a human resources manager or an employer it holds even more value. So what is a payslip? What is the information contained in it?
What does payslip parsing mean? How can you go about parsing payslips and what are the challenges and merits for the same? These are all questions we will explore together in this article. So, let’s get started.
What is a Pay slip or a Pay stub?
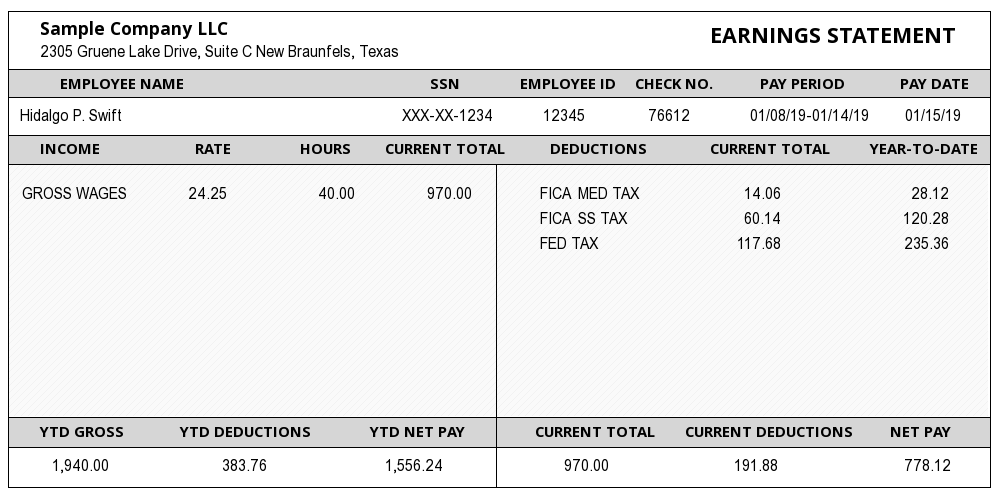
A payslip, also known as a pay stub, is a document provided by an employer to an employee that details the employee's earnings for a specific pay period. It serves as a record of the amount paid to the employee and any deductions made from their gross salary.
Payslips are typically issued on a regular basis, such as weekly, biweekly, or monthly, depending on the employer's payroll schedule and the financial arrangements between both parties.
Payslips are essential for both employees and employers.
| For Employees | For Employers |
|---|---|
| They serve as proof of income, which is crucial for applying for loans, credit, and sometimes even renting an apartment. | Payslips are important for maintaining accurate payroll records, which are necessary for tax reporting and compliance with labor laws. |
| They also help employees understand how their pay is calculated and what deductions are being made, providing transparency. | They also come in handy when budgeting or forecasting the annual expenses for the organization. |
But how does a pay slip look like and what is the information that it contains?
A payslip does not necessarily have a common format. It depends on the employer and the software used to generate it but the information contained within a payslip can be generalised as follows:
- Employee Information: A typical payslip includes details about the employee, such as their full name, employee identification number, and sometimes their address or contact information.
- Employer Information: The payslip often features the employer’s name, address, and possibly other contact details, such as the business registration details.
- Pay Period: This indicates the specific timeframe for which the pay is being issued. It could be weekly, biweekly, monthly, or any other duration depending on the employer’s payroll schedule. It also contains details of leaves taken and the number of days or hours worked.
- Gross Pay: Gross pay represents the total earnings an employee has accrued before any deductions. It includes regular wages or salary, overtime pay, bonuses, commissions, and any other forms of compensation.
- Deductions: These are amounts subtracted from the gross pay for various reasons. The types and amounts of deductions can vary widely based on the country, employer, and employee agreements. Common deductions include national, state and local taxes, social contributions, insurance premiums, retirement contributions, etc.
- Net Pay: This is the actual amount of money the employee takes home after all deductions are made. Net pay is often the most important figure for employees as it represents what they will receive in their bank account or paycheck.
- Year-to-Date (YTD) Totals: Many payslips provide a summary of earnings, deductions, and net pay accumulated since the start of the calendar or fiscal year.
What is meant by payslip parsing or payslip OCR?
One sentence? Data extraction from payslips.
Payslip parsing refers to the process of extracting data from a payslip. This involves identifying and retrieving specific fields such as the employee's name, pay period, gross pay, deductions, net pay, and any other relevant information.
The parsing process converts the unstructured data on thousands of payslips across the organization into an accessible machine-readable format (like a spreadsheet or database), making it easier to analyse, store, and use for various purposes.

But what is payslip OCR?
OCR or Optical Character Recognition is a technology that assists in identifying and extracting only relevant data points from Payslips, regardless of their format and extracting that data into an accesible format.
It converts text in an image of a payslip into machine-readable text. OCR software scans a physical or digital image of a payslip and recognises characters, words, and numbers, turning them into digital text.
This process is particularly useful when dealing with scanned documents or photos of payslips, which cannot be processed by traditional text-based data systems.
But why would one need to parse employee payslips? Let’s take a look.
What are the popular use cases for payslip OCR?
Parsing payslips has a wide range of applications across industries which we will dive into in a minute, but before doing that, it is essential to point out that payslip OCR has evolved with the advent of Artificial Intelligence.
Traditional OCR software, which facilitates simple data extraction from payslips can no longer suffice, despite the benefits it offers. The use cases today are not limited to just data extraction from payslips but also involve modifying and exporting that data into third-party software for recording, analysis, and reporting.
This has led to evolution of IDP (Intelligent Document Processing) software which leverages OCR as one of the underlying technologies to extract data but takes it one-step further to automate end-to-end workflows.
We will discuss using IDP software to parse payslips in a later section but, before we can do that, let us understand the various use-cases first.
1. Commercial Lending (Credit Score Calculation)
For loan disbursement and credit card issuance, banks, and other financial institutions use payslip parsing to verify an applicant's or customer's income and employment status. Automated extraction of salary details ensures a quicker, more reliable loan approval process by providing accurate income verification without manual check as well as record financial health of clients for future reference.
2. Compliance and Auditing Firms (Employment Law Compliance)
Compliance firms parse payslips to ensure that companies adhere to labor laws, including minimum wage, overtime pay, and proper deductions. This is particularly important during audits or when investigating claims of wage theft or unfair labor practices.
3. Insurance Companies (Income Verification for Unemployment Claims)
Insurance providers parse payslips to verify the income of policyholders who file claims for loss of income or unemployment due to accidents, illnesses, or disabilities. This helps in determining the unemployment claim amount accurately based on the policy terms and actual income lost.
4. Tax Preparation Services (Automated Tax Filing)
Tax preparation companies parse payslips to automatically extract income, tax deductions, and withholding details to streamline the tax filing process for clients. This helps ensure that all relevant income and deductions are accurately reported, minimising the risk of errors and audits.
How to parse payslips using OCR?
Now that we have covered what payslips are, what the various use cases of payslip parsing are, and why should we parse payslips, the question becomes how to go about it?
How can I parse payslips but more importantly, how to parse payslips in an optimal manner?
There is no singular approach here. We can take multiple approaches each with different challenges and benefits. In this article we will cover three major approaches:
| Method | Benefits | Challenges |
|---|---|---|
| Using Python | Extensive libraries for data extraction; highly readable and easy to use | Manual effort required; needs engineering support for maintenance |
| Using ChatGPT | UI and API accessibility; flexible output formats | Requires coding skills; inconsistent output quality |
| Using AI-based IDPs | Fully automated; built-in integrations and validation | Higher costs; requires initial setup and training |
The above methods leverage OCR technology to automate payslip parsing and hence, would be the focus of our discussion. Python is the go-to coder's choice, offering a host of libraries for data extraction. LLMs provide more flexibility as well as convenience to extract the data in the desired format than Python. IDPs, in our opinion, are the most optimal method as they can stitch up the entire process into an automated workflow which requires minimal human intervention.
OCR is utilised as one of the underlying technologies powering IDP software. We can think of IDPs as OCR on steroids. Hence, we have omitted the use of traditional OCR owing to inefficiency as well as redundancy.
Read About: How to Parse Data in Excel?
Now that we are clear on the methods we are discussing, let's jump in.
1. Using Python to parse payslips
Python is a widely used programming language due to its versatility and simplicity. One can leverage predefined libraries that Python offers to extract specific data points from a PDF payslip. The script can be scheduled for recurrence to repeat this process. However, this method requires significant coding proficiency and might not be scalable.
We are going to extract employee ID, gross pay, deductions and net pay using the following code snippet but it can be modified for other details as well.
Step 1: Install Required Libraries
You'll need several Python libraries to read PDFs and manipulate Excel files. Use the following command to install the required libraries
pip install PyPDF2 pandas openpyxlExplanation:
- PyPDF2: A library to read PDF files.
- pandas: A library to handle data in DataFrame format, which is useful for manipulating and saving data into Excel.
- openpyxl: A library to read and write Excel files in the .xlsx format.
Step 2: Extract Text from PDF
Extract text from PDF files using PyPDF2. This step involves reading the PDF and converting its content into a text format.
Here’s a function to extract text from a PDF:
import PyPDF2
def extract_text_from_pdf(pdf_path):
text_content = ""
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
for page in range(len(reader.pages)):
text_content += reader.pages[page].extract_text()
return text_contentExplanation:
- pdf_path: Path to the PDF file.
- The function reads the PDF file and iterates through each page to extract text, appending it to text_content.
Step 3: Parse Extracted Text for Relevant Data Points
Once you have the text content, you need to parse it to extract relevant data points like employee name, gross pay, deductions, net pay, etc.
Here’s an example function to parse specific data points from the extracted text:
import re
def parse_payslip_data(text):
data = {}
# Example regular expressions to extract data points
data['employee_id'] = re.search(r"Employee ID:\s*(.*)", text).group(1)
data['gross_pay'] = re.search(r"Gross Pay:\s*([\d,]+\.?\d*)", text).group(1)
data['deductions'] = re.search(r"Deductions:\s*([\d,]+\.?\d*)", text).group(1)
data['net_pay'] = re.search(r"Net Pay:\s*([\d,]+\.?\d*)", text).group(1)
return dataExplanation:
- re.search(): A regular expression function to search for patterns in the text. You need to adjust the regular expressions based on the actual format of your payslips.
- The group(1) method extracts the matching part of the regular expression.
Step 4: Save Data to Excel
Once you have the extracted data, you can save it to an Excel file using pandas.
Here’s a function to save the extracted data to an Excel file:
import pandas as pd
def save_data_to_excel(data, excel_path):
df = pd.DataFrame([data]) # Convert the data dictionary to a DataFrame
df.to_excel(excel_path, index=False) # Save the DataFrame to an Excel file
print(f"Data successfully saved to {excel_path}")Explanation:
- data: The dictionary containing parsed data.
- excel_path: Path to save the Excel file.
Step 5: Define the main function
The main function wraps your code and coordinates timely execution of all functions. It is defined below:
def main(pdf_path, excel_path):
text_content = extract_text_from_pdf(pdf_path)
parsed_data = parse_payslip_data(text_content)
save_data_to_excel(parsed_data, excel_path)
# Example usage
pdf_path = 'sample_payslip.pdf'
excel_path = 'payslip_data.xlsx'
main(pdf_path, excel_path)Explanation:The main function integrates all steps. It takes the PDF file path and Excel file path as input and performs the entire workflow from extraction to saving data.
Unified Code:
You can download the unified code by clicking on the button below:
Not fully automated
Data gets scattered, across multiple software
Significant post-processing effort required
Requires engineering teams for maintenance and debugging
2. Using LLMs to parse payslips
Using Python can help optimise the payslip parsing process to a certain degree, but it requires coding proficiency and may not be scalable. Another approach that leverages cutting-edge technology, is the use of Large Language Models (LLMs).
What are LLMs? LLMs are sophisticated machine learning models that are trained on large data sets and utilise complex neural networks to mimic human problem-solving in a prompt-and-response manner. Think of them as advancements to Natural Language Processing (NLP).
There are a lot of popular LLMs available in the market today. Examples include, Open AI’s ChatGPT, Gemini by Google, LLaMa by Meta (previously, Facebook), among others. We will be leveraging ChatGPT-4o across two methods here:
- Method 1: Using the GPT User Interface to parse payslips
- Method 2: Using the GPT API to parse payslips
Method 1: Using the GPT User Interface to parse payslips
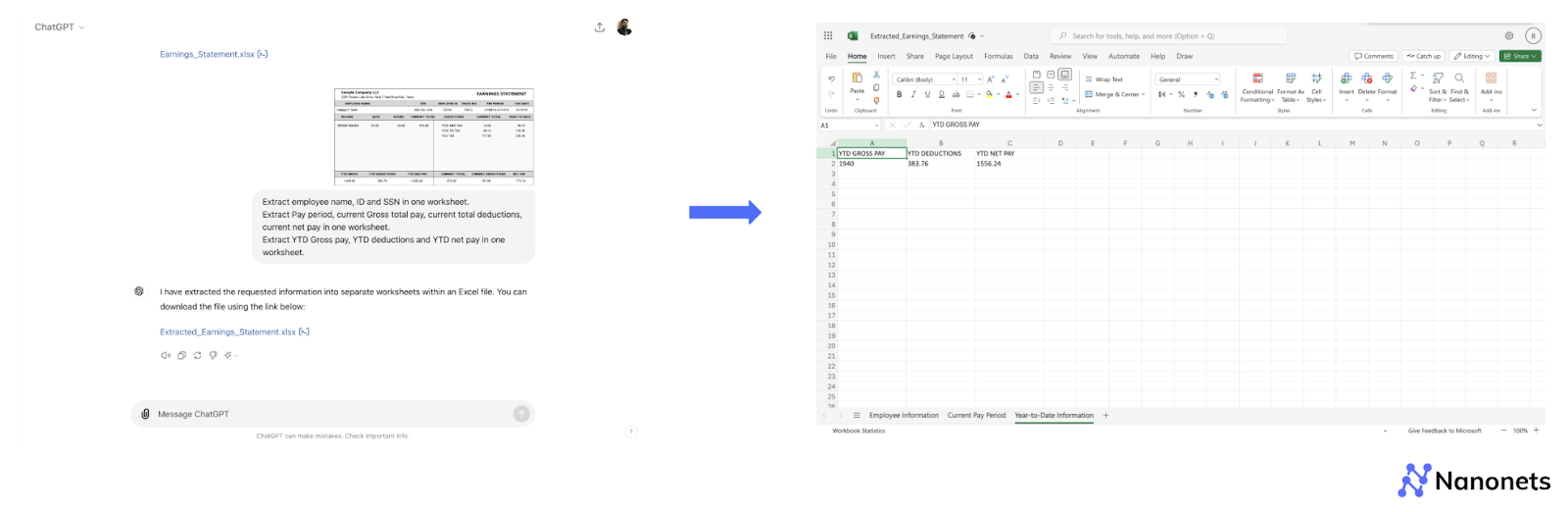
For this method, we will be using ChatGPT-4o’s native User Interface. We will use a sample payslip image and try and convert it to an Excel spreadsheet.
Step 1: Visit chatgpt.com and log into your account.
Step 2: In the prompt section, you have an option to upload a file and type in a prompt to generate a response.
Step 3: Upload your file, type your prompt and then press, "Enter". Download the processed file once ready.
We tried two simple prompts which worked well for us. The trick is to get the prompt right. The more specific you are with what you need, the better the output gets.

“Extract employee name, ID and SSN in one worksheet. Extract Pay period, current Gross total pay, current total deductions, current net pay in one worksheet.
Extract YTD Gross pay, YTD deductions and YTD net pay in one worksheet.”
Read About: Extract text from PDF using ChatGPT
Method 2: Using the GPT API to parse payslips
There is another method where we can access GPT using API. To extract relevant data points from a payslip image into an Excel sheet using the GPT API, we will leverage OpenAI’s capabilities to interpret the text within an image and extract specific information.
Here's a step-by-step guide along with the relevant code snippets to accomplish this task. You can also download the unified code snippet at the end.
Step 1: Install the libraries needed for this task, including `openai` for interacting with the GPT API and `pandas` for handling Excel file operations.
pip install openai pandas
Step 2: Before using the GPT API, ensure that you have an OpenAI API key. This key is required for authentication.
import openai
import pandas as pd
# Set your OpenAI API key
openai.api_key = "your_openai_api_key
Step 3: You will have to upload the payslip image to the OpenAI server so that GPT can process it. This requires handling the image file and converting it into a format suitable for the API.
def upload_image(file_path):
# Open the image file
with open(file_path, "rb") as image_file:
# Upload the image to OpenAI
response = openai.Image.create(file=image_file, purpose="answers")
# Extract the file ID from the response
file_id = response["id"]
return file_id
Step 4: Create a prompt that instructs GPT to extract specific data points such as employee ID, SSN, Gross pay, Deductions, Net Pay, and Current Pay Period from the text in the image.
def create_prompt():
# Define the prompt to extract specific data points
prompt = (
"Extract the following information from this payslip: "
"Employee ID, SSN, Current Gross Pay, Current Deductions, "
"Current Net Pay, and Current Pay Period."
)
return prompt
Step 5: This step extract the data from the file. Send the image and prompt to the GPT API. The API will process the image, extract the text, and then identify the relevant data points based on the prompt provided.
def extract_data_from_image(file_id, prompt):
response = openai.Completion.create(
model="gpt-4", # Using GPT-4 model
prompt=prompt,
max_tokens=500,
n=1,
stop=None,
temperature=0.5,
file=file_id
)
return response["choices"][0]["text"]
Step 6: Now we can parse the response. This step involves extracting the relevant information from the GPT API's response. This may require parsing JSON data or handling structured text.
import re
def parse_extracted_data(text):
# Using regular expressions to parse out the specific data points
data = {
"Employee ID": re.search(r"Employee ID: (\w+)", text).group(1),
"SSN": re.search(r"SSN: (\d+-\d+-\d+)", text).group(1),
"Current Gross Pay": re.search(r"Current Gross Pay: (\$?\d+(\.\d{2})?)", text).group(1),
"Current Deductions": re.search(r"Current Deductions: (\$?\d+(\.\d{2})?)", text).group(1),
"Current Net Pay": re.search(r"Current Net Pay: (\$?\d+(\.\d{2})?)", text).group(1),
"Current Pay Period": re.search(r"Current Pay Period: (\w+ \d+, \d+)", text).group(1)
}
return data
Step 7: Finally, this step use pandas to write the extracted data into an Excel file, ensuring that each data point is correctly placed in the desired columns.
def save_data_to_excel(data, excel_path):
# Convert the dictionary to a DataFrame
df = pd.DataFrame([data])
# Write the DataFrame to an Excel file
df.to_excel(excel_path, index=False)
print(f"Data successfully saved to {excel_path}.")
The `main` function orchestrates the workflow for extracting specific data points from a payslip image and saving them into an Excel file.
Unified Code:
You can download the unified code by clicking the button below:
By following these steps, you can effectively automate the process of extracting and organising data from a payslip image into an Excel format using GPT-4o API.
Dealing with complex APIs requires coding proficiency
Prompt engineering is required
Scalability issues
Output may not always turn out exactly as needed
3. Using AI-based IDP Software to parse payslips
Until now, we have reviewed two methods that each provide a certain degree of automation to parsing payslips as well as present a unique set of challenges. The one-stop solution for overcoming these and the most optimal solution for automating payslip parsing is leveraging IDP (Intelligent Document Processing) software.
This class of software can not only identify and extract data points from payslips accurately but also automate the entire end-to-end payslip parsing process, right from importing different file formats, to data extraction, formatting and export into CRMs, ERPs and other databases.
Let us look at how we can automate payslip parsing using IDPs with an example. We will be using Nanonets for this:
Step 1: Visit app.nanonets.com and sign up.
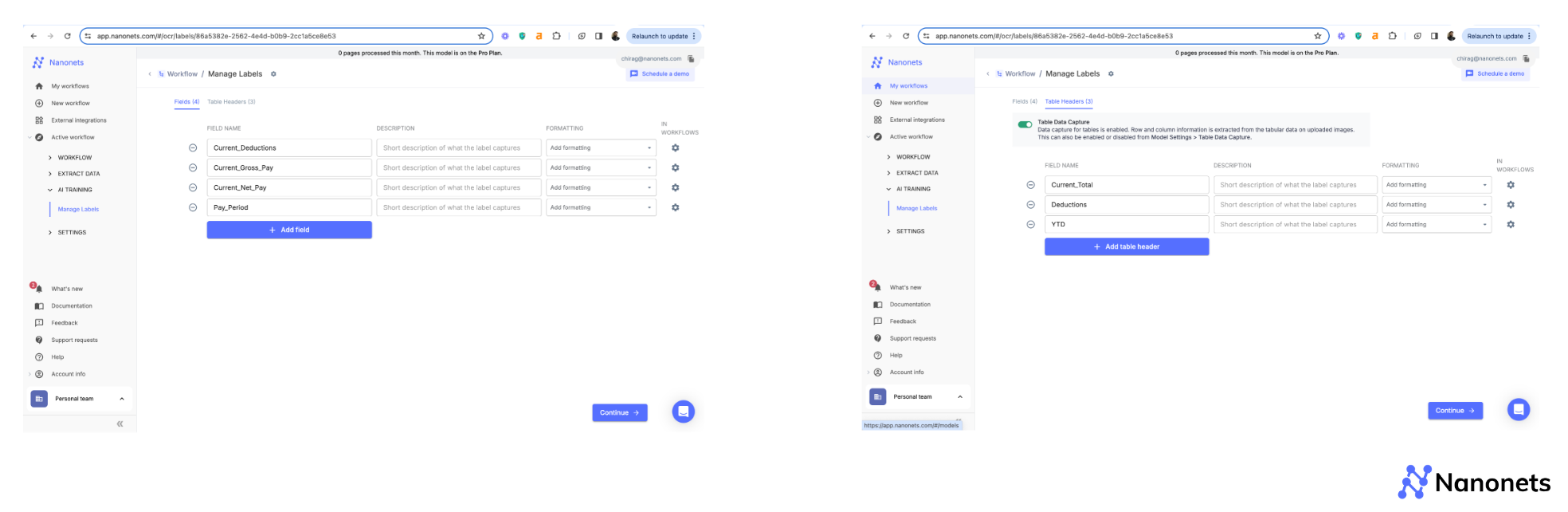
Step 2: Once you are signed in, click on "New workflow" on the left panel > Zero-training extractor.
Step 3: All you need to enter is the name of the data points you want to extract. If you need data extracted as tables, switch to the "Table Headers" section at the top and add the data points there. Use the "Description" section powered by generative AI, to add helpful context for the AI.
We will extract current gross pay, deductions, net pay and pay period as fields and YTD deductions as a table. See screenshots below.
Step 4: Click on "Continue" and upload your payslip. We used the following example.
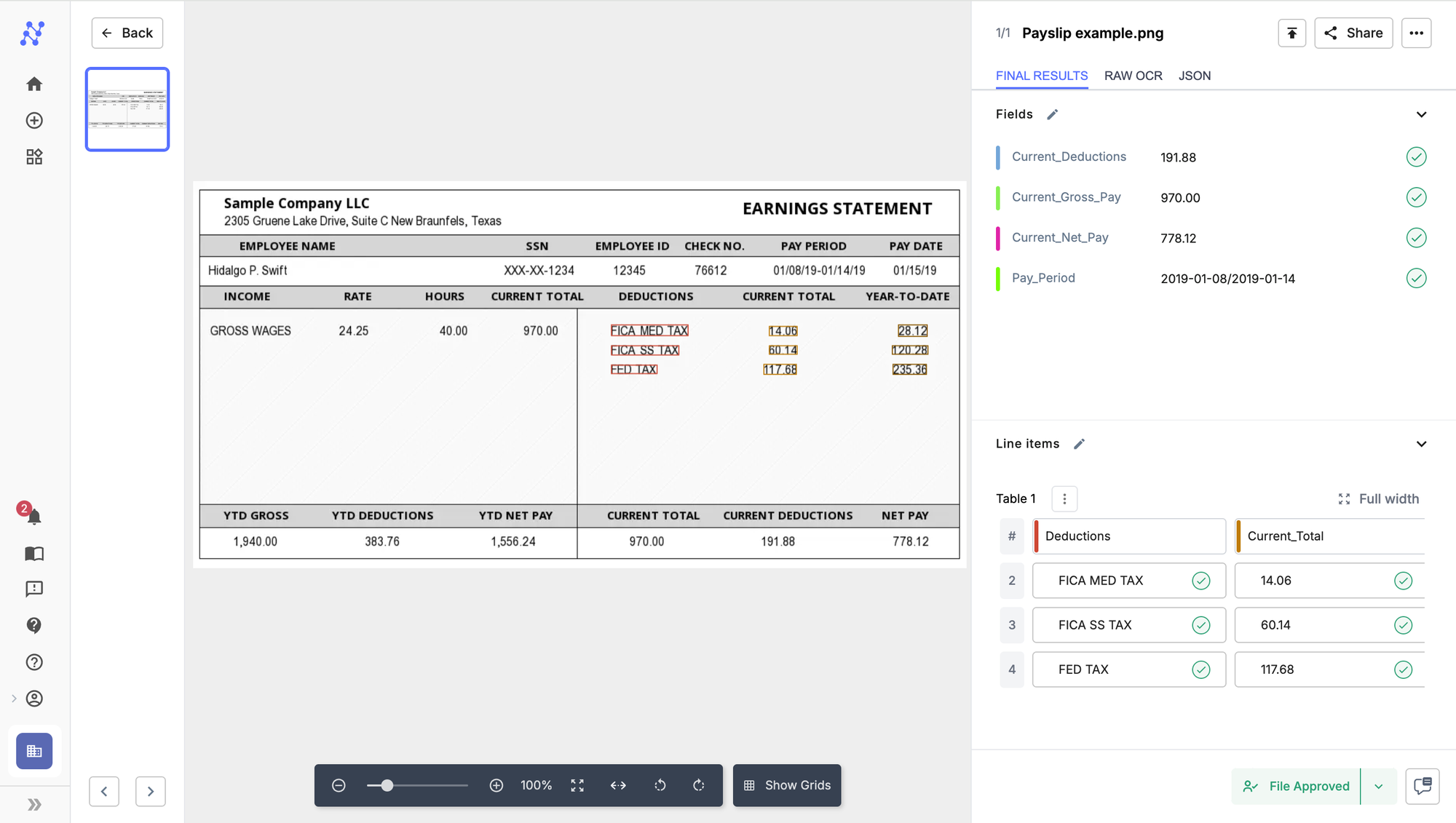
It is that simple to parse payslips using Nanonets. Using a zero-training OCR model means that it requires no training and can be deployed in minutes.
Not just that, Nanonets offers a host of other features that come in handy while automating specific payslip parsing use cases.
For instance, in credit scoring, if the net pay for an employee is above a certain threshold, add a new field, called "Auto-Qualified for Loans" and mark it as true.
This singular data point can take away hours from manual review.
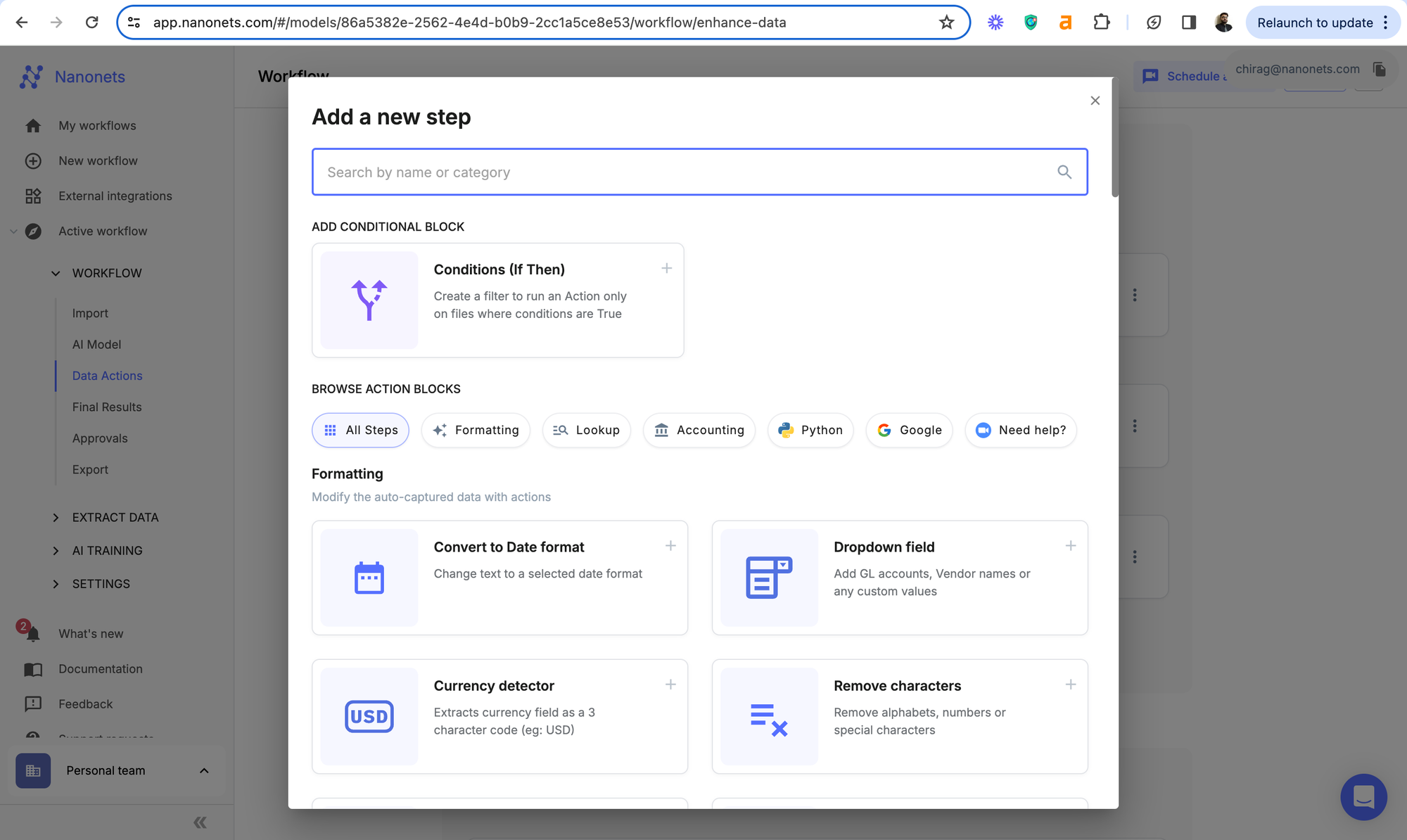
For Example, for employment law compliance in auditing (discussed above), if the basic pay for any employee is below the minimum wage standards, the relevant payslip gets flagged and the audit officer gets a notification for review.
This can increase the efficiency of the entire audit process by 10x.