Have you ever faced the challenge of extracting tables from a mountain of documents? Whether it’s scanning through PDF files, forms, or images, copying data manually is not only tedious but also prone to errors. I’ve been there – spending hours struggling with formatting issues and double-checking my work.
Thankfully, technology has come a long way, and with the right tools, we can now automate the process of table extraction. With table OCR software, you can detect and extract tabular data from documents seamlessly in just one go, saving you time and reducing manual rework.
In this article, I’ll show you how Nanonets makes this process easy and efficient. I’ll also explore some of the most popular deep learning techniques used for detecting and extracting tables from various document types.
Table Extraction is the task of detecting and decomposing table information in a document.

Want to extract tabular data from images, invoices, receipts or any other type of document? Check out Nanonets' PDF table extractor to extract tabular data. Schedule a demo to learn more about automating table extraction.
Who will find Table Extraction Useful
As discussed in the previous section, tables are used frequently to represent data in a clean format. We can see them so often across several areas, from organizing our work by structuring data across tables to storing huge assets of companies. There are a lot of organizations that have to deal with millions of tables every day. To facilitate such laborious tasks of doing everything manually, we need to resort to faster techniques. Let’s discuss a few use cases where extracting tables can be essential:

Personal use cases
The table extraction process can be helpful for small personal use cases as well. Sometimes we capture documents on the mobile phone and later copy them to our computers. Instead of using this process, we can directly capture the documents and save them as editable formats in our custom templates. Below are a few use cases about how we can fit table extraction into our personal routine:
Scanning Documents to Phone: We often capture images of important tables on the phone and save them, but with the table extraction technique, we can capture the images of the tables and store them directly in a tabular format, either in Excel or Google Sheets. With this, we need not search for images or copy the table content to any new files, instead, we can directly use the imported tables and start working on the extracted information.
Documents to HTML: In web pages, we find loads of information presented using tables. They help us in comparison with the data and give us a quick note on the numbers in an organized way. By using the table extraction process, we can scan PDF and text documents or JPG/PNG images, and load the information directly into a custom self-designed table format. We can further write scripts to add additional tables based on the existing tables, and thereby digitalize the information. This helps us in editing the content and quickens the storage process.
Industrial use cases
There are several industries across the globe that run hugely on paperwork and documentation, especially in the Banking and Insurance sectors. From storing customers’ details to tending to the customers’ needs, tables are widely used. This information again is passed in as a document (hard copy) to different branches for approvals, wherein sometimes, miscommunication can lead to errors while grabbing information from tables. Instead, using intelligent automation here, makes our lives much easier. Once the initial data is captured and approved, we can directly scan those documents into tables and further work on the digitized data. Let alone the reduction of time consumption and faults, we can notify the customers about the time and location where the information is processed. This, therefore, ensures reliability of data, and simplifies our way of tackling operations. Let’s now look at the other possible use cases:
Quality Control: Quality control is one of the core services that top industries provide. It is usually done in-house and for the stakeholders. As part of this, there are a lot of feedback forms that are collected from consumers to extract feedback about the service provided. In industrial sectors, they use tables to jot down daily checklists and notes to see how the production lines are working. All these can be documented at a single place using table extraction with ease.
Track Of Assets: In Manufacturing industries, people use hardcoded tables to keep track of manufactured entities like Steel, Iron, Plastic, etc. Every manufactured item is labeled with a unique number wherein they use tables to keep track of items manufactured and delivered every day. Automation can help save a lot of time and assets in terms of misplacements or data inconsistency.
Business use cases
There are several business industries that run on Excel sheets and offline forms. But at one point in time, it’s difficult to search through these sheets and forms. If we are manually entering these tables, it’s time-consuming, and the chance of data being entered incorrectly will be high. Hence table extraction is a better alternative to solve business use cases as such below are few.
Invoice Automation: There are many small-scale and large-scale industries whose invoices are still generated in tabular formats. These do not provide properly secured tax statements. To overcome such hurdles, we can use table extraction to convert all invoices into an editable format and thereby, upgrade them to a newer version.
Form Automation: Online forms are disrupting this tried-and-true method by helping businesses collect the information they need and simultaneously connecting it to other software platforms built into their workflow. Besides reducing the need for manual data entry (with automated data entry) and follow-up emails, table extraction can eliminate the cost of printing, mailing, storing, organizing, and destroying the traditional paper alternatives.
Have an OCR problem in mind? Want to digitize invoices, PDFs or number plates? Head over to Nanonets and build OCR models for free!
Deep Learning in Action
Deep learning is a part of the broader family of machine learning methods based on artificial neural networks.
Neural Network is a framework that recognizes the underlying relationships in the given data through a process that mimics the way the human brain operates. They have different artificial layers through which the data passes, where they learn about features. There are different architectures like Convolution NNs, Recurrent NNs, Autoencoders, Generative Adversarial NNs to process different kinds of data. These are complex yet depict high performance to tackle problems in real-time. Let’s now look into the research that has been carried out in the table extraction field using Neural Networks and also, let’s review them in brief.
TableNet
Introduction: TableNet is a modern deep learning architecture that was proposed by a team from TCS Research year in the year 2019. The main motivation was to extract information from scanned tables through mobile phones or cameras.
They proposed a solution that includes accurate detection of the tabular region within an image and subsequently detecting and extracting information from the rows and columns of the detected table.
Dataset: The dataset used was Marmot. It has 2000 pages in PDF format which were collected with the corresponding ground-truths. This includes Chinese pages as well. Link - http://www.icst.pku.edu.cn/cpdp/sjzy/index.htm
Architecture: The architecture is based out of Long et al., an encoder-decoder model for semantic segmentation. The same encoder/decoder network is used as the FCN architecture for table extraction. The images are preprocessed and modified using the Tesseract OCR.
The model is derived in two phases by subjecting the input to deep learning techniques. In the first phase, they’ve used the weights of a pretrained VGG-19 Network. They’ve replaced the fully connected layers of the used VGG network by 1x1 Convolutional layers. All the convolutional layers are followed by the ReLU activation and a dropout layer of probability 0.8. They call the second phase as the decoded network which consists of two branches. This is according to the intuition that the column region is a subset of the table region. Thus, the single encoding network can filter out the active regions with better accuracy using features of both table and column regions. The output from the first network is distributed to the two branches. In the first branch, two convolution operations are applied and the final feature map is upscaled to meet the original image dimensions. In the other branch for detecting columns, there is an additional convolution layer with a ReLU activation function and a dropout layer with the same dropout probability as mentioned before. The feature maps are up-sampled using fractionally strided convolutions after a (1x1) convolution layer. Below is an image of the architecture:
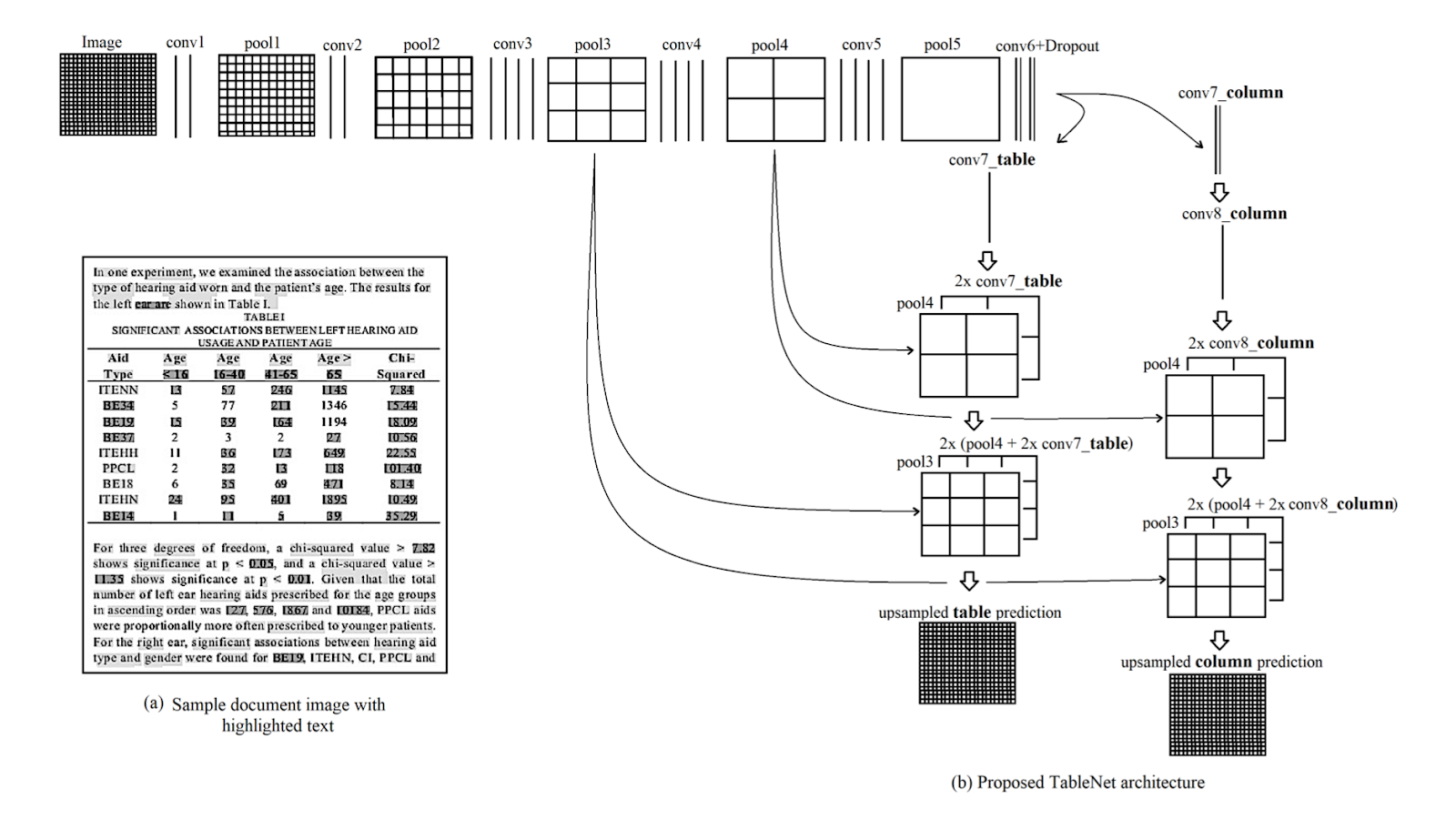
Outputs: After the documents are processed using the model, the masks of tables and columns are generated. These masks are used to filter out the table and its column regions from the image. Now using the Tesseract OCR, the information is extracted from the segmented regions. Below is an image showing the masks that are generated and later extracted from the tables:

They also proposed the same model that is fine-tuned with ICDAR which performed better than the original model. The Recall, Precision, and F1-Score of the fine-tuned model are 0.9628, 0.9697, 0.9662 respectively. The original model has the recorded metrics of 0.9621, 0.9547, 0.9583 in the same order. Let’s now dive into one more architecture.
DeepDeSRT
Paper: DeepDeSRT: Deep Learning for Detection and Structure Recognition of Tables in Document Images
Introduction: DeepDeSRT is a Neural Network framework that is used to detect and understand the tables in the documents or images. It has two solutions as mentioned in the title:
- It presents a deep learning-based solution for table detection in document images.
- It proposes a novel deep learning-based approach for table structure recognition, i.e. identifying rows, columns, and cell positions in the detected tables.
The proposed model is completely data-based, it does not require heuristics or metadata of the documents or images. One main advantage with respect to the training is they did not use large training datasets, instead they used the concept of transfer learning and domain adaptation for both table detection and table structure recognition.
Dataset: The dataset used is an ICDAR 2013 table competition dataset containing 67 documents with 238 pages overall.
Architecture:
- Table Detection The proposed model used Fast RCNN as the basic framework for detecting the tables. The architecture is broken down into two different parts. In the first part, they generated region proposals based on the input image by a so-called region proposal network (RPN). In the second part, they classified the regions using Fast-RCNN. To back this architecture, they used ZFNet and the weights of VGG-16.
- Structure Recognition After a table has successfully been detected and its location is known to the system, the next challenge in understanding its contents is to recognize and locate the rows and columns which make up the physical structure of the table. Hence they’ve used a fully connected network with the weights of VGG-16 that extracts information from the rows and columns. Below are the outputs of DeepDeSRT:
Outputs:
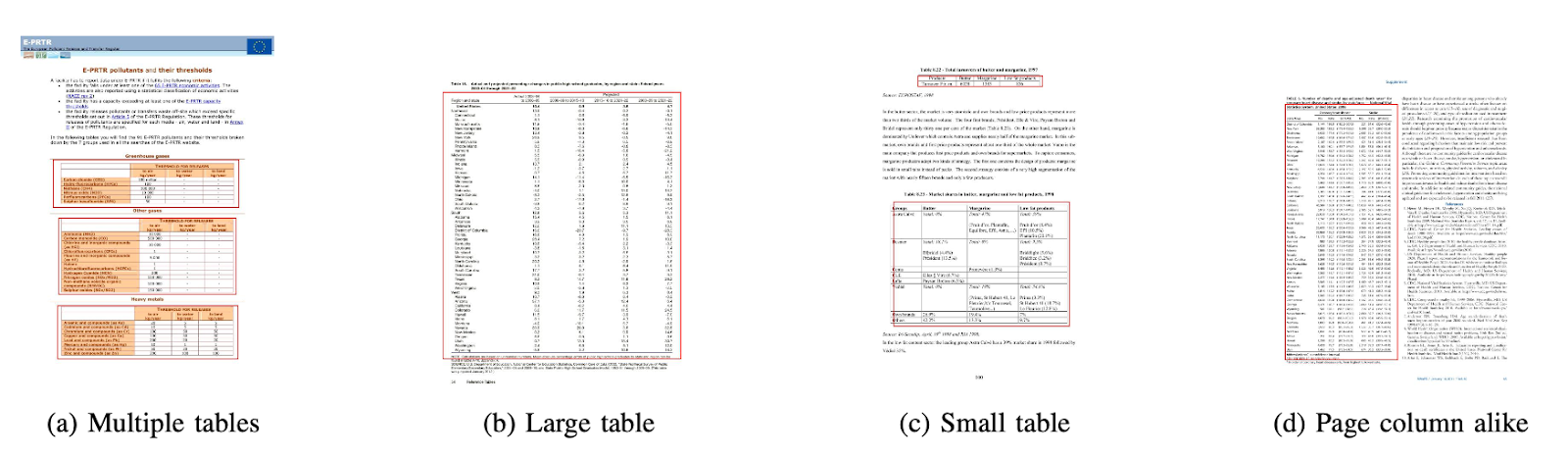
Evaluation results reveal that DeepDeSRT outperforms state-of-the-art methods for table detection and structure recognition and achieves F1-measures of 96.77% and 91.44% for table detection and structure recognition, respectively until 2015.
Graph Neural Networks
Paper: Rethinking Table Recognition using Graph Neural Networks
Introduction: In this research, the authors from Deep Learning Laboratory, National Center of Artificial Intelligence (NCAI) proposed Graph Neural Networks for extracting information from tables. They argued that graph networks are a more natural choice for these problems and further explored two gradient-based graph neural networks.
This proposed model combines the benefits of both, convolutional neural networks for visual feature extraction and graph networks for dealing with the problem structure.
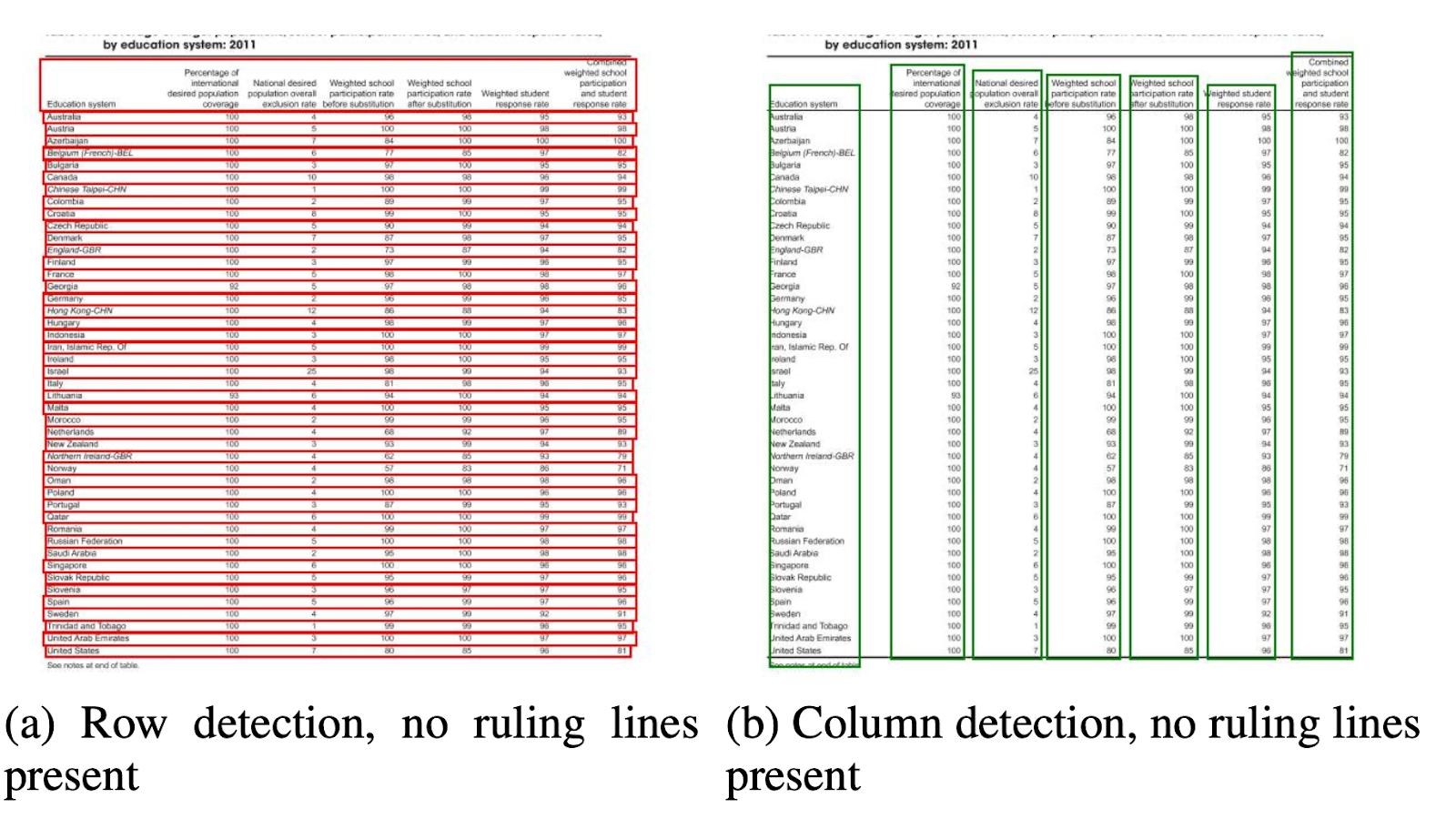
Dataset: The authors proposed a new large synthetically generated dataset of 0.5 Million tables divided into four categories.
- Images are plain images with no merging and with ruling lines
- Images have different border types including the occasional absence of ruling lines
- Introduces cell and column merging
- The camera captured images with the linear perspective transformation
Architecture: They used a shallow convolutional network which generates the respective convolutional features. If the spatial dimensions of the output features are not the same as the input image, they collect positions that are linearly scaled down depending on the ratio between the input and output dimensions and send them to an interaction network that has two graph networks known as DGCNN and GravNet. The parameters of the graph network are the same as the original CNN. In the end, they’ve used a runtime pair sampling to classify the content that is extracted which internally used the Monte Carlo based algorithm. Below are the outputs:
Outputs:

Below is the tabulated accuracy numbers that are generated by the networks for four categories of the network as presented in the Dataset section:

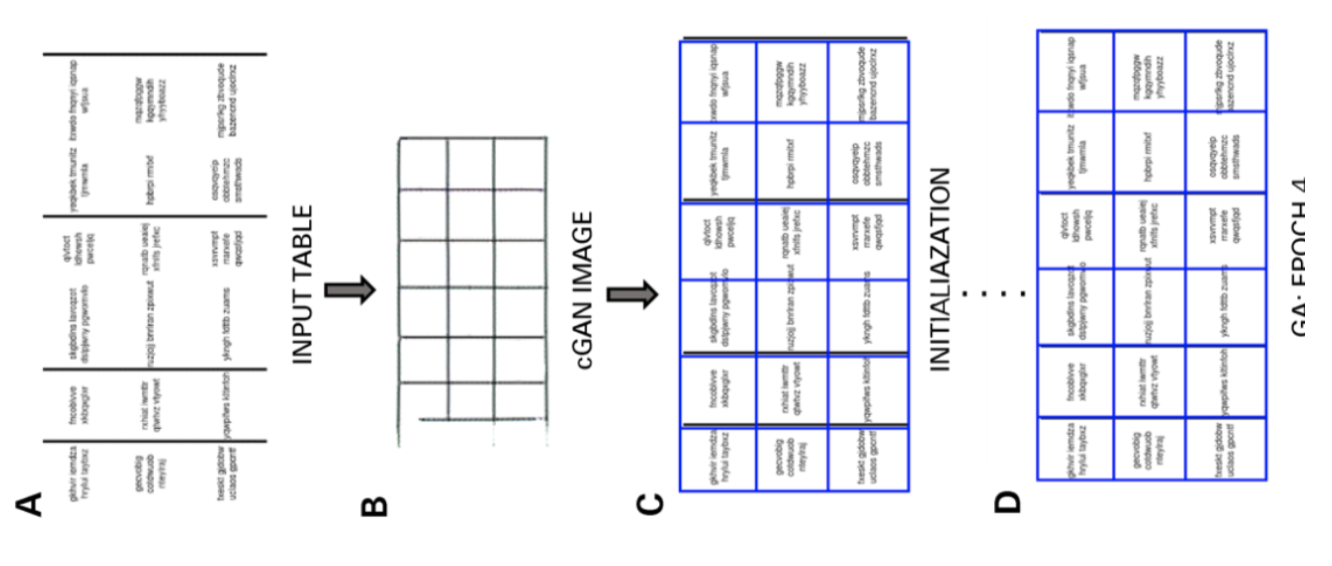
CGANs and Genetic Algorithms
Introduction: In this research, the authors used a top-down approach instead of using a bottom-up (integrating lines into cells, rows or columns) approach.
In this method, using a generative adversarial network, they mapped the table image into a standardized ‘skeleton’ table form. This skeleton table denotes the approximate row and column borders without the table content. Next, they fit the renderings of candidate latent table structures to the skeleton structure using a distance measure optimized by a genetic algorithm.
Dataset: The authors used their own dataset that has 4000 tables.
Architecture: The model proposed consists of two parts. In the first part, the input images are abstracted into skeleton tables using a conditional generative adversarial neural network. A GAN has two networks again, the generator which generates random samples and discriminator which tells if the generated images are fake or original. Generator G is an encoder-decoder network where an input image is passed through a series of progressively downsampling layers until a bottleneck layer where the process is reversed. To pass sufficient information to the decoding layers, a U-Net architecture with skip connections is used and a skip connection is added between layers i and n − i via concatenation, where n is the total number of layers, and i is the layer number in the encoder. A PatchGAN architecture is used for the discriminator D. This penalizes the output image structure at the scale of patches. These produce the output as a skeleton table.
In the second part, they optimize the fit of candidate latent data structures to the generated skeleton image using a measure of the distance between each candidate and the skeleton. This is how the text inside the images is extracted. Below is an image depicting the architecture:
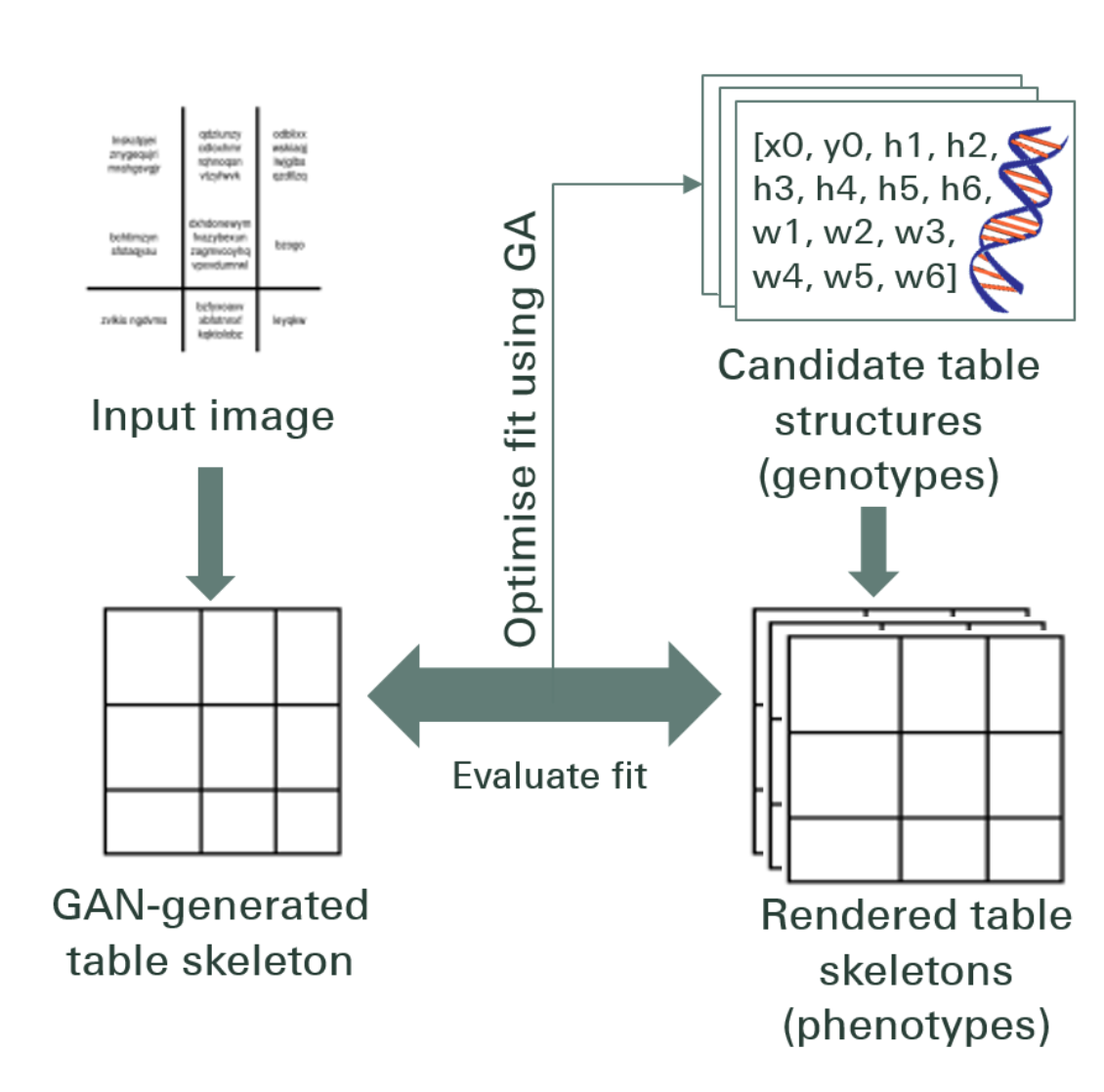
Output: The estimated table structures are evaluated by comparing - Row and column number , Upper left corner position, Row heights and column widths
The genetic algorithm gave 95.5% accuracy row-wise and 96.7% accuracy column-wise while extracting information from the tables.
Need to digitize documents, receipts or invoices but too lazy to code? Head over to Nanonets document automation software and build OCR models for free!
[Code] Traditional Approaches
In this section, we’ll learn the process of how to extract information from tables using Deep Learning and OpenCV. You can think of this explanation as an introduction, however, building state-of-the-art models will need a lot of experience and practice. This will help you understand the fundamentals of how we can train computers with various possible approaches and algorithms.
To understand the problem in a more precise way, we define some basic terms, which will be used throughout the article:
- Text: contains a string and five attributes (top, left, width, height, font)
- Line: contains text objects which are assumed to be on the same line in the original file
- Single-Line: line object with only one text object.
- Multi-Line: line object with more than one text object.
- Multi-Line Block: a set of continuous multi-line objects.
- Row: Horizontal blocks in the table
- Column: Vertical Blocks in the table
- Cell: the intersection of a row and column
- Cell - Padding: the internal padding or space inside the cell.
Table Detection with OpenCV
We’ll use traditional computer vision techniques to extract information from the scanned tables. Here’s our pipeline; we initially capture the data (the tables from where we need to extract the information) using normal cameras, and then using computer vision, we’ll try finding the borders, edges, and cells. We’ll use different filters and contours, and we shall highlight the core features of the tables.
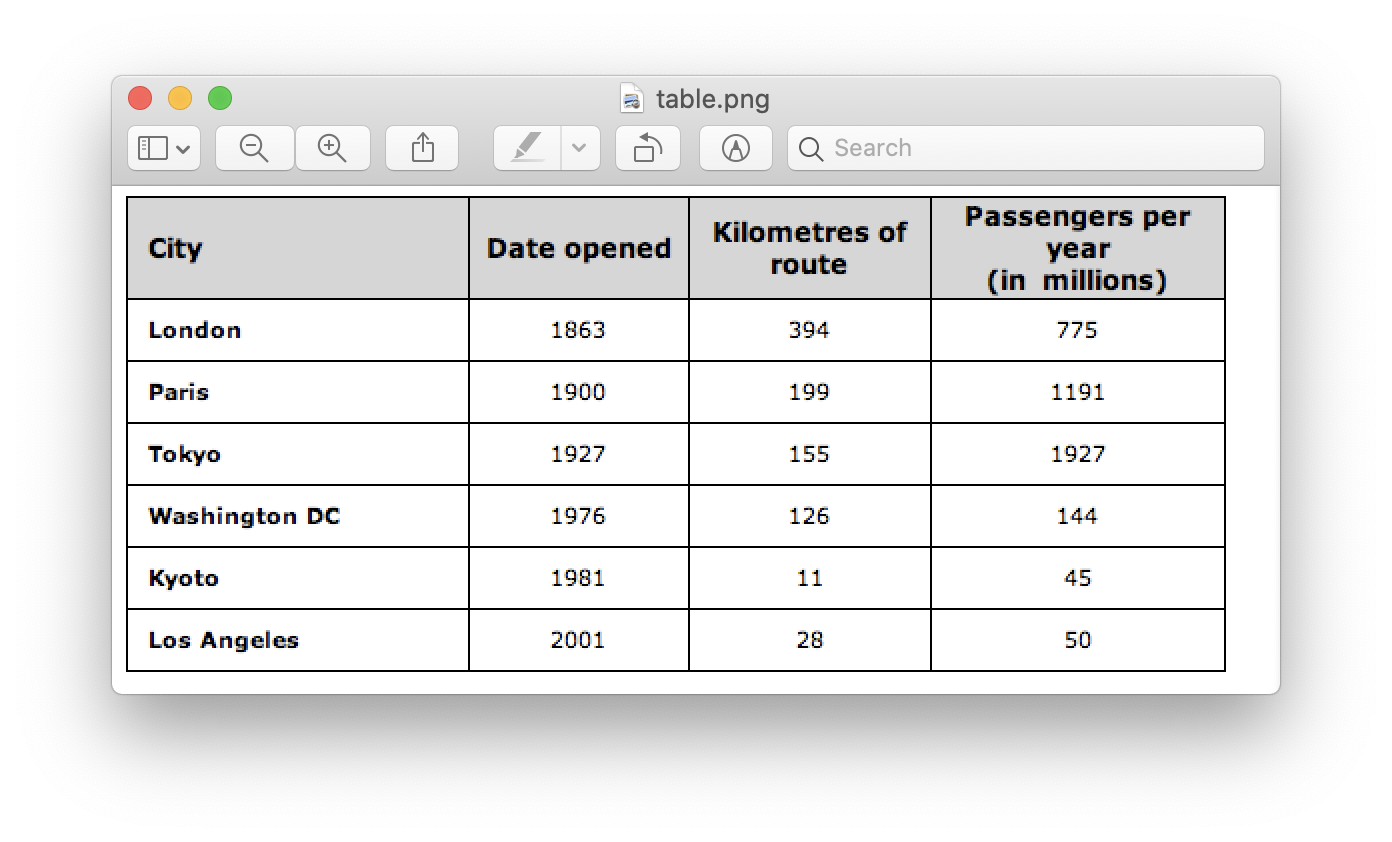
We’ll be needing an image of a table. We can capture this on a phone or use any existing image. Below is the code snippet,
file = r’table.png’
table_image_contour = cv2.imread(file, 0)
table_image = cv2.imread(file)
Here, we have loaded the same image image two variables since we'll be using the table_image_contour when drawing our detected contours onto the loaded image. Below is the image of the table which we are using in our program:
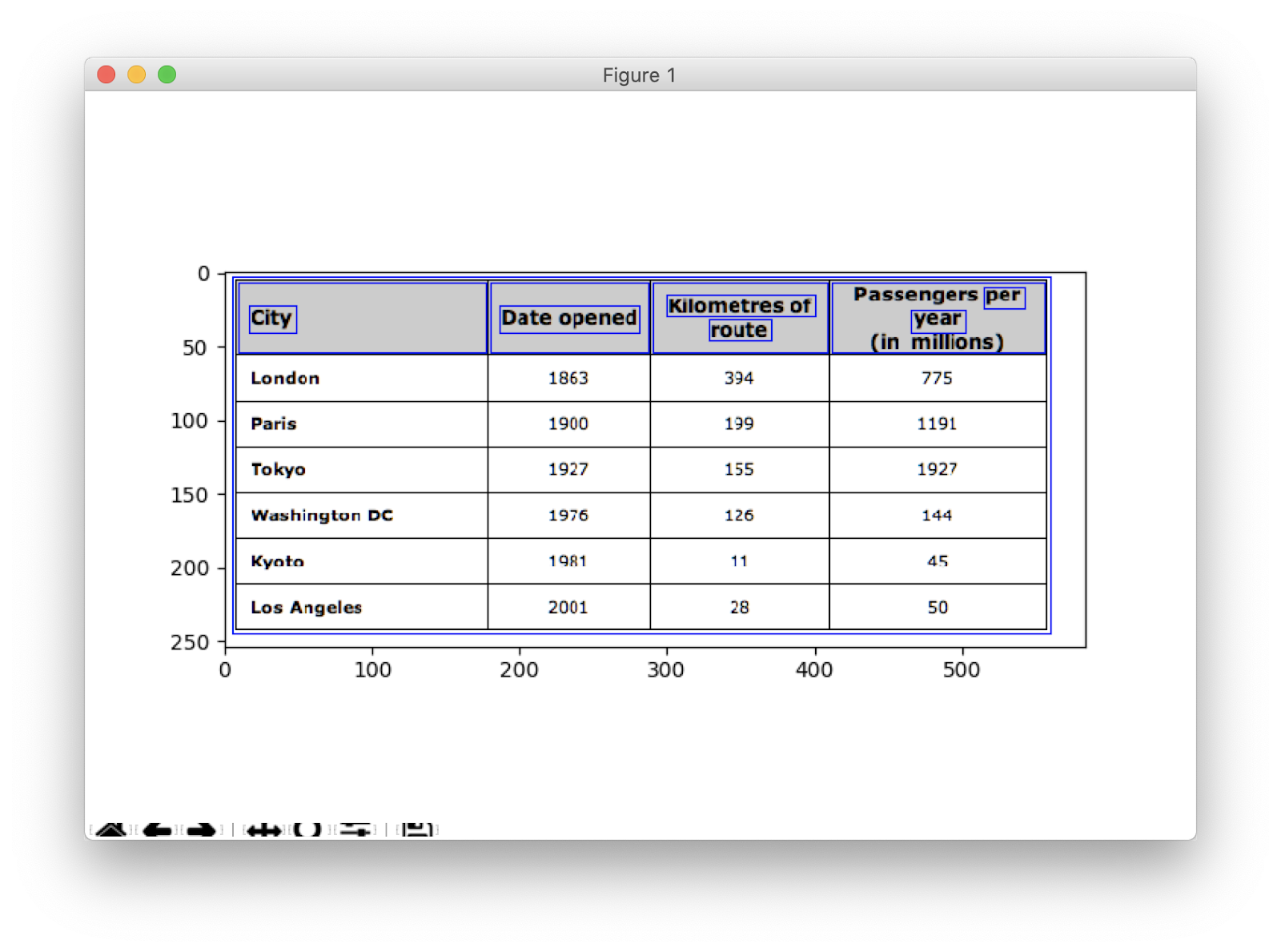
We shall employ a technique called Inverse Image Thresholding which enhances the data present in the given image.
ret, thresh_value = cv2.threshold(
table_image_contour, 180, 255, cv2.THRESH_BINARY_INV)
Another important preprocessing step is image dilation. Dilation is a simple math operation applied to binary images (Black and White) which gradually enlarges the boundaries of regions of foreground pixels (i.e. white pixels, typically).
kernel = np.ones((5,5),np.uint8)
dilated_value = cv2.dilate(thresh_value,kernel,iterations = 1)
In OpenCV, we use the method, findContours to obtain the contours in the present image. This method takes three arguments, first is the dilated image (the image that is used to generate the dilated image is table_image_contour - findContours method only supports binary images), the second is the cv2.RETR_TREE which tells us to use the contour retrieval mode, the third is the cv2.CHAIN_APPROX_SIMPLE which is the contour approximation mode. The findContours unpacks two values, hence we'll add one more variable named hierarchy. When the images are nested, contours exude interdependence. To represent such relationships, hierarchy is used.
contours, hierarchy = cv2.findContours(
dilated_value, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
The contours mark where exactly the data is present in the image. Now, we iterate over the contours list that we computed in the previous step and calculate the coordinates of the rectangular boxes as observed in the original image using the method, cv2.boundingRect. In the last iteration, we put those boxes onto the original image table_image using the method, cv2.rectangle().
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# bounding the images
if y < 50:
table_image = cv2.rectangle(table_image, (x, y), (x + w, y + h), (0, 0, 255), 1)
This is our last step. Here we use the method namedWindow to render our table with the extracted content and contours embedded on it. Below is the code snippet:
plt.imshow(table_image)
plt.show()
cv2.namedWindow('detecttable', cv2.WINDOW_NORMAL)
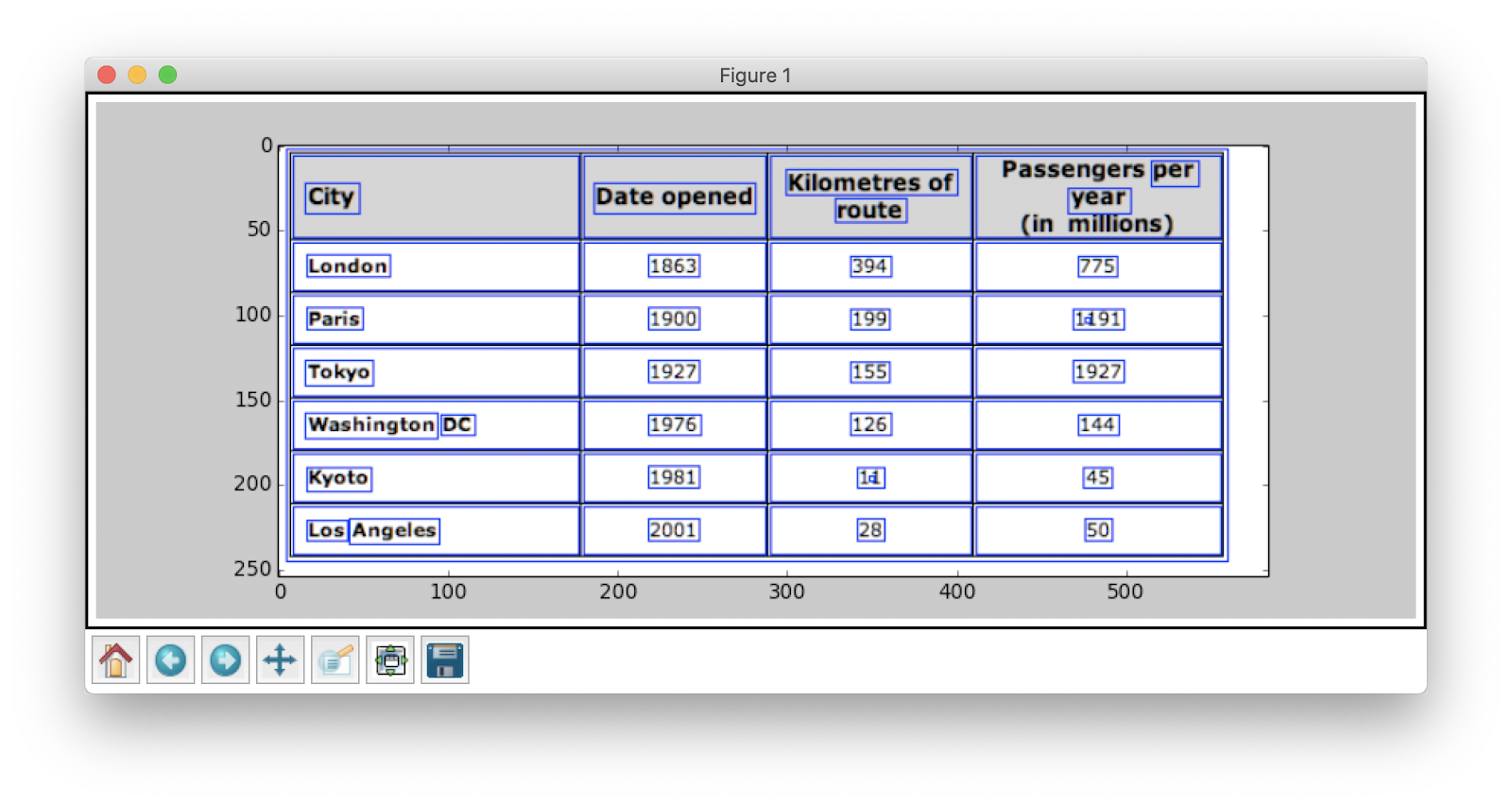
Change the value of y to 300 in the above code snippet, this will be your output:
Once you have the tables extracted, you can run every contour crop through tesseract OCR engine, the tutorial for which can be found here. Once we have boxes of each text, we can cluster them based on their x and y coordinates to derive which corresponding row and column they belong.
Besides this, there's the option of using PDFMiner to turn your pdf documents into HTML files that we can parse using regular expressions to finally get our tables. Here's how you can do it.
PDFMiner and Regex parsing
To extract information from smaller documents, it’s time taking to configure deep learning models or write computer vision algorithms. Instead, we can use regular expressions in Python to extract text from the PDF documents. Also, remember that this technique does not work for images. We can only use this to extract information from HTML files or PDF documents. This is because, when you’re using a regular expression, you’ll need to match the content with the source and extract information. With images, you’ll not be able to match the text, and the regular expressions will fail. Let’s now work with a simple PDF document and extract information from the tables in it. Below is the image:

In the first step, we load the PDF into our program. Once that’s done, we convert the PDF to HTML so that we can directly use regular expressions and thereby, extract content from the tables. For this, the module we use is pdfminer. This helps to read content from PDF and convert it into an HTML file.
Below is the code snippet:
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.converter import HTMLConverter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from cStringIO import StringIO
import re
def convert_pdf_to_html(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = HTMLConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = file(path, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages = 0 #is for all
caching = True
pagenos=set()
for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages,password=password,caching=caching, check_extractable=True):
interpreter.process_page(page)
fp.close()
device.close()
str = retstr.getvalue()
retstr.close()
return str
Code Credits: zevross
We imported a lot of modules inclusive of Regular Expression and PDF related libraries. In the method convert_pdf_to_html, we send the path of the PDF file which needs to be converted to an HTML file. The output of the method will be an HTML string as shown below:
'<span style="font-family: XZVLBD+GaramondPremrPro-LtDisp; font-size:12px">Changing Echoes\n<br>7632 Pool Station Road\n<br>Angels Camp, CA 95222\n<br>(209) 785-3667\n<br>Intake: (800) 633-7066\n<br>SA </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> TX DT BU </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> RS RL OP PH </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> CO CJ \n<br></span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> SF PI </span><span style="font-family: GDBVNW+Wingdings-Regular; font-size:11px">s</span><span style="font-family: UQGGBU+GaramondPremrPro-LtDisp; font-size:12px"> AH SP\n<br></span></div>'
Regular expression is one of the trickiest and coolest programming techniques used for pattern matching. These are widely used in several applications, say, for code formatting, web scraping, and validation purposes. Before we start extracting content from our HTML tables, let’s quickly learn a few things about regular expressions.
This library provides various inbuilt methods to match and search for patterns. Below are a few:
import re
# Match the pattern in the string
re.match(pattern, string)
# Search for a pattern in a string
re.search(pattern, string)
# Finds all the pattern in a string
re.findall(pattern, string)
# Splits string based on the occurrence of pattern
re.split(pattern, string, [maxsplit=0]
# Search for the pattern and replace it with the given string
re.sub(pattern, replace, string)
Characters/Expressions you usually see in regular expressions include:
- [A-Z] - any capital letter
- \d - digit
- \w - word character (letters, digits, and underscores)
- \s - whitespace (spaces, tabs, and whitespace)
Now to find out a particular pattern in HTML, we use regular expressions and then write patterns accordingly. We first split the data such that the address chunks are segregated into separate blocks in accordance with the program name (ANGELS CAMP, APPLE VALLEY, etc.):
pattern = '(?<=<span style="font-family: XZVLBD\+GaramondPremrPro-LtDisp; font-size:12px">)(.*?)(?=<br></span></div>)'
for programinfo in re.finditer(pattern, biginputstring, re.DOTALL):
do looping stuff…
Later, we find the program name, city, state, and zip which always follow the same pattern (text, comma, two-digit capital letters, 5 numbers (or 5 numbers hyphen four numbers) - these are present in the PDF file which we considered as input). Check the following code snippet:
# To identify the program name
programname = re.search('^(?!<br>).*(?=\\n)', programinfo.group(0))
# since some programs have odd characters in the name we need to escape
programname = re.escape(programname)
citystatezip =re.search('(?<=>)([a-zA-Z\s]+, [a-zA-Z\s]{2} \d{5,10})(?=\\n)', programinfo.group(0))
mainphone =re.search('(?<=<br>)\(\d{3}\) \d{3}-\d{4}x{0,1}\d{0,}(?=\\n)', programinfo.group(0))
altphones = re.findall('(?<=<br>)[a-zA-Z\s]+: \(\d{3}\) \d{3}-\d{4}x{0,1}\d{0,}(?=\\n)(?=\\n)', programinfo.group(0))
This is a simple example explaining how we extract information from PDF files using a regular expression. After extracting all the required information, we load this data into a CSV file.
def createDirectory(instring, outpath, split_program_pattern):
i = 1
with open(outpath, 'wb') as csvfile:
filewriter = csv.writer(csvfile, delimiter=',' , quotechar='"', quoting=csv.QUOTE_MINIMAL)
# write the header row
filewriter.writerow(['programname', 'address', 'addressxtra1', 'addressxtra2', 'city', 'state', 'zip', 'phone', 'altphone', 'codes'])
# cycle through the programs
for programinfo in re.finditer(split_program_pattern, instring, re.DOTALL):
print i
i=i+1
# pull out the pieces
programname = getresult(re.search('^(?!<br>).*(?=\\n)', programinfo.group(0)))
programname = re.escape(programname) # some facilities have odd characters in the name
So this is a simple example explaining how you can push your extracted HTML into a CSV file. First we create a CSV file, find all our attributes, and push one-by-one into their respective columns. Below is a screenshot:
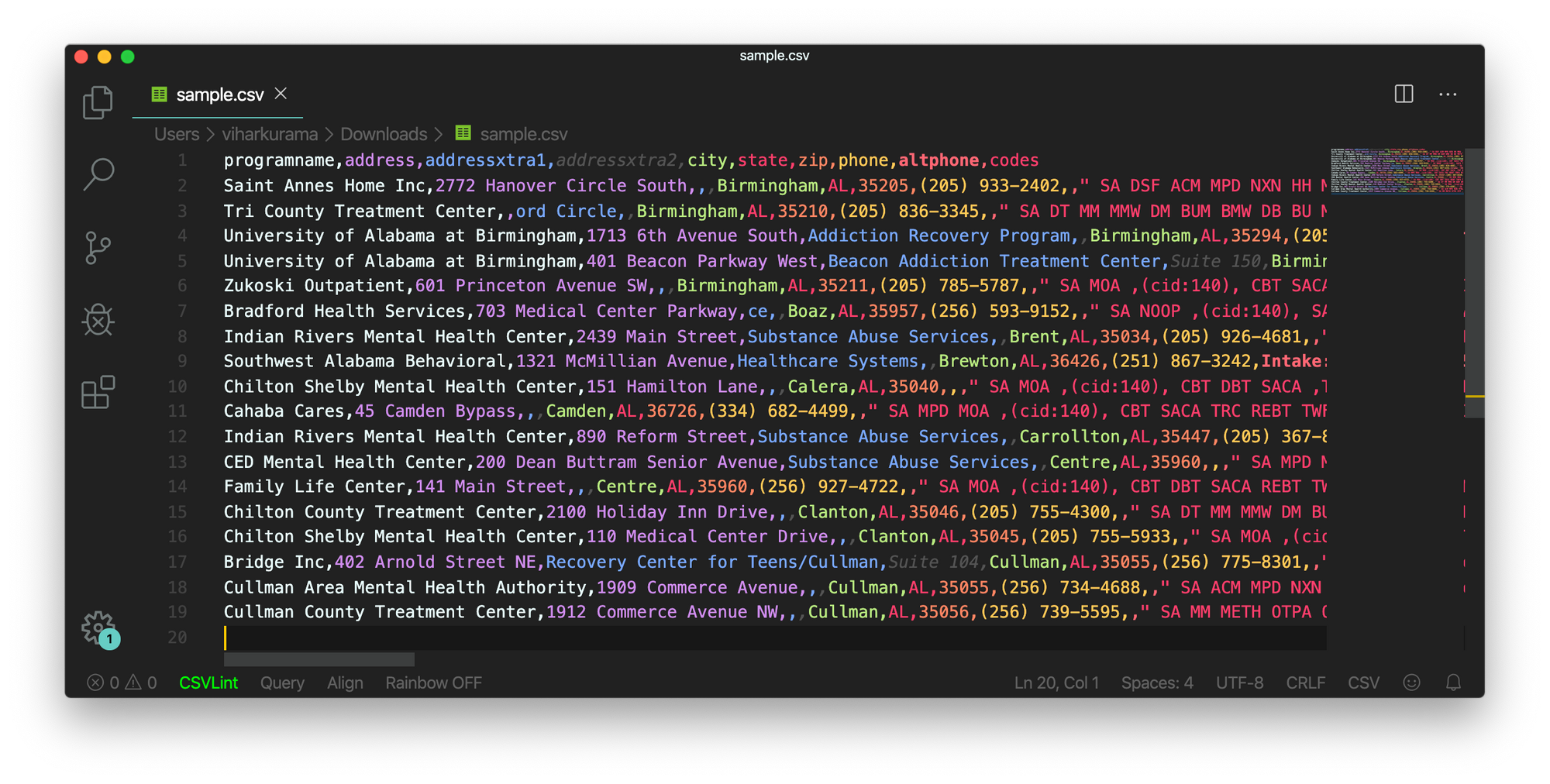
At times, the above-discussed techniques seem complicated and pose challenges to the programmers if at all the tables are nested and complex. Here, choosing a CV or Deep learning model saves a lot of time. Let’s see what drawbacks and challenges hinder the usage of these traditional methods.
Challenges with Traditional Methods
In this section, we’ll learn in-depth regarding where the table extraction processes might fail, and further understand the ways to overcome these obstacles using modern methods born out of Deep Learning. This process isn’t a cakewalk though. The reason being that tables usually do not remain constant throughout. They have different structures to represent the data, and the data inside tables can be multi-linguistic with various formatting styles (font style, color, font size, and height). Hence to build a robust model, one should be aware of all these challenges. Usually, this process includes three steps: table detection, extraction, and conversion. Let’s identify the problems in all phases, one by one:
Table Detection
In this phase, we identify where exactly the tables are present in the given input. The input can be of any format, such as Images, PDF/Word documents and sometimes videos. We use different techniques and algorithms to detect the tables, either by lines or by coordinates. In some cases, we might encounter tables with no borders at all, where we need to opt for different methods. Besides these, here are a few other challenges:
- Image Transformation: Image transformation is a primary step in detecting labels. This includes enhancing the data and borders present in the table. We need to choose proper preprocessing algorithms based on the data presented in the table. For example, when we are working with images, we need to apply thresholding and edge detectors. This transformation step helps us to find the content more precisely. In some cases, the contours might go wrong and the algorithms fail to enhance the image. Hence, choosing the right image transformation steps and preprocessing is crucial.
- Image Quality: When we scan tables for information extraction, we need to make sure that these documents are scanned in brighter environments which ensures good quality images. When the lighting conditions are poor, CV and DL algorithms might fail to detect tables in the given inputs. If we are using deep learning, we need to make sure the dataset is consistent and has a good set of standard images. If we use these models on tables present in old crumpled papers, then first we need to preprocess and eliminate the noise in those pictures.
- Variety of Structural Layouts and Templates: All tables are not unique. One cell can span over several cells, either vertically or horizontally, and combinations of spanning cells can create a vast number of structural variations. Also, some emphasize features of text, and table lines can affect the way the table’s structure is understood. For example, horizontal lines or bold text may emphasize multiple headers of the table. The structure of the table visually defines the relationships between cells. Visual relationships in tables make it difficult to computationally find the related cells and extract information from them. Hence it’s important to build algorithms that are robust in handling different structures of tables.
- Cell Padding, Margins, Borders: These are the essentials of any table - paddings, margins, and borders will not always be the same. Some tables have a lot of padding inside cells, and some do not. Using good quality images and preprocessing steps will help the table extraction process to run smoothly.
Table Extraction
This is the phase where the information is extracted after the tables are identified. There are a lot of factors regarding how the content is structured and what content is present in the table. Hence it’s important to understand all the challenges before one builds an algorithm.
- Dense Content: The content of the cells can either be numeric or textual. However, the textual content is usually dense, containing ambiguous short chunks of text with the use of acronyms and abbreviations. In order to understand tables, the text needs to be disambiguated, and abbreviations and acronyms need to be expanded.
- Different Fonts and Formats: Fonts are usually of different styles, colors, and heights. We need to make sure that these are generic and easy to identify. Few font families especially the ones that fall under cursive or handwritten, are a bit hard to extract. Hence using good font and proper formatting helps the algorithm to identify the information more accurately.
- Multiple Page PDFs and Page Breaks: The text line in tables is sensitive to a predefined threshold. Also with spanning cells across multiple pages, it becomes difficult to identify the tables. On a multi-table page, it is difficult to distinguish different tables from each other. Sparse and irregular tables are hard to work with. Therefore, graphic ruling lines and content layout should be used together as important sources for spotting table regions.
Table Conversion
The last phase includes converting the extracted information from tables to compiling them as an editable document, either in excel or using other software. Let’s learn about a few challenges.
- Set Layouts: When different formats of tables are extracted from scanned documents, we need to have a proper table layout to push the content in. Sometimes, the algorithm fails to extract information from the cells. Hence, designing a proper layout is also equally important.
- Variety of value presentation patterns: Values in cells can be presented using different syntactic representation patterns. Consider the text in the table to be 6 ± 2. The algorithm might fail to convert that particular information. Hence the extraction of numerical values requires knowledge of possible presentation patterns.
- Representation for visualization: Most of the representation formats for tables, such as markup languages in which tables can be described, are designed for visualization. Therefore, it is challenging to automatically process tables.
These are the challenges that we face during the table extraction process using traditional techniques. Now let’s see how to overcome these with the help of Deep Learning. It is being widely researched in various sectors.
Want to scrape data from PDF documents, extract PDF data to Excel or automate table extraction? Find out how Nanonets PDF scraper or PDF parser can power your business to be more productive.
Extract Table from Image with Nanonets Table OCR
-
Sign up for a free Nanonets account
- Upload images/files to Nanonets Table OCR model
- Nanonets automatically detects & extract all the tabular data
- Edit & review the data (if required)
- Export the processed data as Excel, csv or JSON
Extract Table from Image with Nanonets
Nanonets Table OCR API

The Nanonets OCR API allows you to build OCR models with ease. You do not have to worry about pre-processing your images or worry about matching templates or build rule based engines to increase the accuracy of your OCR model.
You can upload your data, annotate it, set the model to train and wait for getting predictions through a browser based UI without writing a single line of code, worrying about GPUs or finding the right architectures for your table detection using deep learning models.
You can also acquire the JSON responses of each prediction to integrate it with your own systems and build machine learning powered apps built on state of the art algorithms and a strong infrastructure.
https://nanonets.com/documentation/
Need to digitize documents, receipts or invoices but too lazy to code? Head over to Nanonets and build OCR models for free!
Summary
In this article, we’ve reviewed in detail about information extraction from tables. We’ve seen how modern technologies like Deep Learning and Computer Vision can automate mundane tasks by building robust algorithms in outputting accurate results. In the initial sections, we’ve learned about table extraction’s role in facilitating the individuals, industries and business sectors tasks’, and also reviewed use cases elaborating on extracting tables from PDFs/HTML, form automation, invoice Automation, etc. We’ve coded an algorithm using Computer Vision to find the position of information in the tables using thresholding, dilation, and contour detection techniques. We’ve discussed the challenges that we might face during the table detection, extraction, and conversion processes when using the conventional techniques, and stated how deep learning can help us in overcoming these issues. Lastly, we’ve reviewed a few neural network architectures and understood their ways of achieving table extraction based on the given training data.
