
Technology keeps evolving, and so do we. With the emergence of artificial intelligence and machine learning, the focus has shifted towards automation. That being said, various computer science disciplines are introduced to study and explore the applications of these emerging trends.
One such example is image processing in AI. In simple language, it refers to exploring images to draw meaningful information. While several techniques are available to achieve this, the most commonly used is – bounding boxes.
This blog delves into various aspects of bounding boxes. It includes what they are, how they work in image processing, parameters that define them, conventions that specify them, common use cases, precautions and best practices, and more.
Let’s dive in.
What Is Image Processing?
Image processing refers to performing certain operations on an image either to enhance it or extract some valuable insights from the features or attributes associated with it. Today, image processing is a primary area of research in engineering and computer technology studies.
The basic steps in image processing consist of:
- Using image acquisition tools to load the image
- Analyzing and interpreting the image
- Generating a modified image as output or report based on analysis of the image
Image processing can be done using two methods - analog image processing and digital image processing.
Analog image processing involves using hard copies of print out and photographs to analyze and manipulate images. Image analysts use various methods to interpret these image copies and extract meaningful results.
Digital image processing uses digital images and interprets them using computers. It is a sub-category of digital signal processing and uses algorithms to process digital images. It provides advantages over analog image processing, such as algorithms to prevent noise and distortion in processing.
Any data that undergoes digital image processing has to pass three phases:
- Pre-processing
- Enhancement and Display
- Information Extraction
Digital image processing has several applications in the areas of medicine, manufacturing, eCommerce, and more.
What Are Bounding Boxes?
Bounding boxes are the key elements and one of the primary image processing tools for video annotation projects. In essence, a bounding box is an imaginary rectangle that outlines the object in an image as a part of a machine learning project requirement. The imaginary rectangular frame encloses the object in the image.
Bounding boxes specify the position of the object, its class, and confidence which tells the degree of probability that the object is actually present in the bounding box.
Bounding Boxes in Image Processing
At the outset, the bounding box is an imaginary rectangular box that includes an object and a set of data points. In the context of digital image processing, the bounding box denotes the border’s coordinates on the X and Y axes that enclose an image. They are used to identify a target and serve as a reference for object detection and generate a collision box for the object.
Computer vision offers amazing applications – from self-driving cars to facial recognition and more. And this, in turn, is made possible with image processing.
So, is image processing as simple as drawing rectangles or patterns around objects? No. That being said, what do bounding boxes do?
Let's understand.
How Do Bounding Boxes Work In Image Processing?
As mentioned, the bounding box is an imaginary rectangle that acts as a reference point for object detection and develops a collision box for the object.
So, how does it help data annotators? Well, professionals use the idea of bounding boxes to draw imaginary rectangles over the images. They create outlines of the objects in question within each image and define its X and Y coordinates. This makes the job of machine learning algorithms simpler, helping them find collision paths and such, thereby saving computing resources.
For example, in the below image, each vehicle is a key object whose position and location are essential for training the machine learning models. Data annotators use the bounding boxes technique to draw the rectangles around each of these objects – vehicles, in this case.
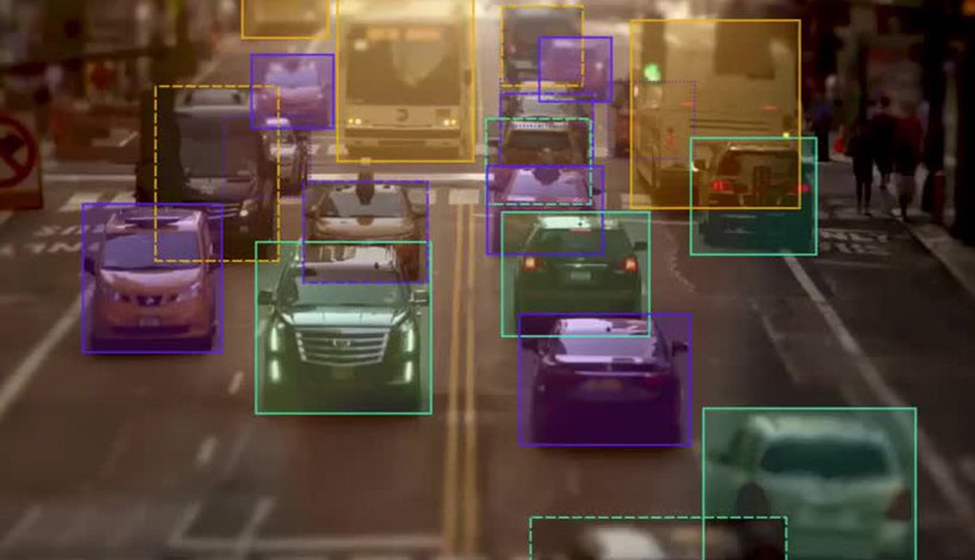
Source: keymakr
Then, they use the coordinates to understand the position and location of each object, which is useful to train the machine learning models. A single bounding box doesn’t provide a good prediction rate. For enhanced object detection, multiple bounding boxes must be used in combination with data augmentation methods.
Bounding boxes are highly efficient and robust image annotation techniques that reduce costs considerably.
Parameters Defining A Bounding Box
The parameters are based on the conventions used to specify the bounding box. The key parameters used include:
- Class: It denotes the object inside the bounding box — for example, cars, houses, buildings, etc.
- (X1, Y1): This refers to the X and Y coordinates of the top left corner of the rectangle.
- (X2, Y2): This refers to the X and Y coordinates of the bottom right corner of the rectangle.
- (Xc, Yc): This refers to the X and Y coordinates of the center of the bounding box.
- Width: This denotes the width of the bounding box.
- Height: This denotes the height of the bounding box.
- Confidence: This represents the possibility of the object being in the box. Say, the confidence is 0.9. This means there’s a 90% probability that the object will actually be present inside the box.
Conventions Specifying A Bounding Box
When specifying a bounding box, usually, two main conventions need to be included. These are:
- The X and Y coordinates of the top left and bottom right points of the rectangle.
- The X and Y coordinates of the center of the bounding box, along with its width and height.
Let’s illustrate this with the example of a car.
a. With respect to the first convention, the bounding box is specified as per the coordinates of the top left and bottom right points.

Source: AnalyticsVidhya
b. With respect to the second convention, the bounding box is described as per the center coordinates, width, and height.
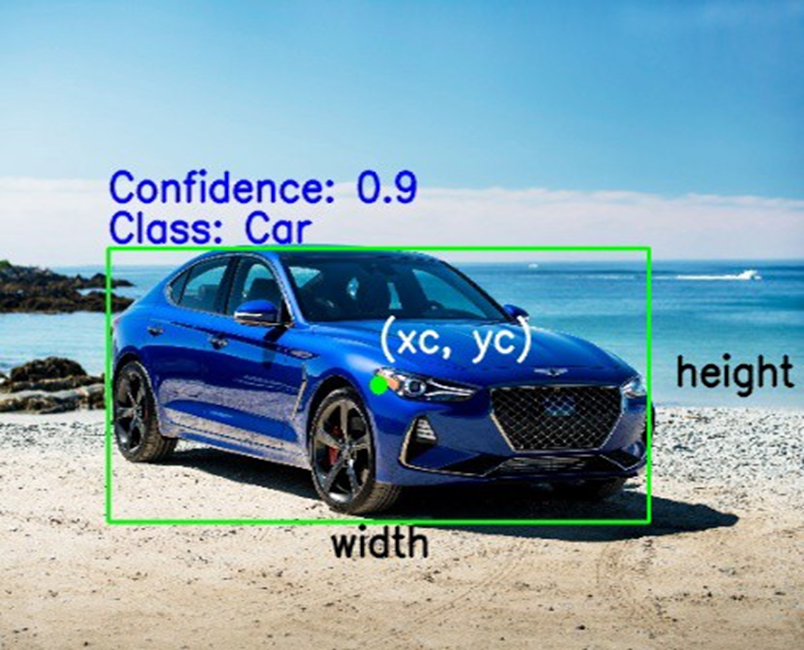
Source: AnalyticsVidhya
How Are The Conventions Related?
Depending on the use case, it is possible to convert between the different convention types.
- Xc = (X1 + X2)/2
- Yc = (Y1 + Y2)/2
- Width = (X2 - X1)
- Height = (Y2 - Y1)
Bounding Boxes Explained With Programming Code
Let’s see another example about the location or position of an object with code snippets.

Source: d2i
We load the image to be used for this illustration. The image has a dog on the left and a cat on the right. There are two objects - a dog and a cat in the image.

Source: d2i
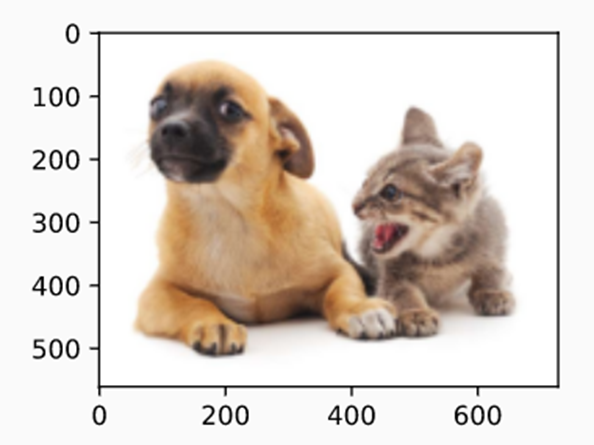
Source: d2i
Let’s take the x and y as coordinates for the upper left and lower-right corners of the bounding box. Say, (x1,y1) and (x2,y2). Similarly, let’s consider the (x,y) - axis coordinates for the center of the bounding box, along with its width and height.
Next, we define two functions to convert these forms: box_corner_to_center converts the two-corner representation to the center-height-width representation and box_center_to_corner does it vice-versa.
The input argument boxes need to be a two-dimensional tensor of shape (n,4), where n is the number of bounding boxes.
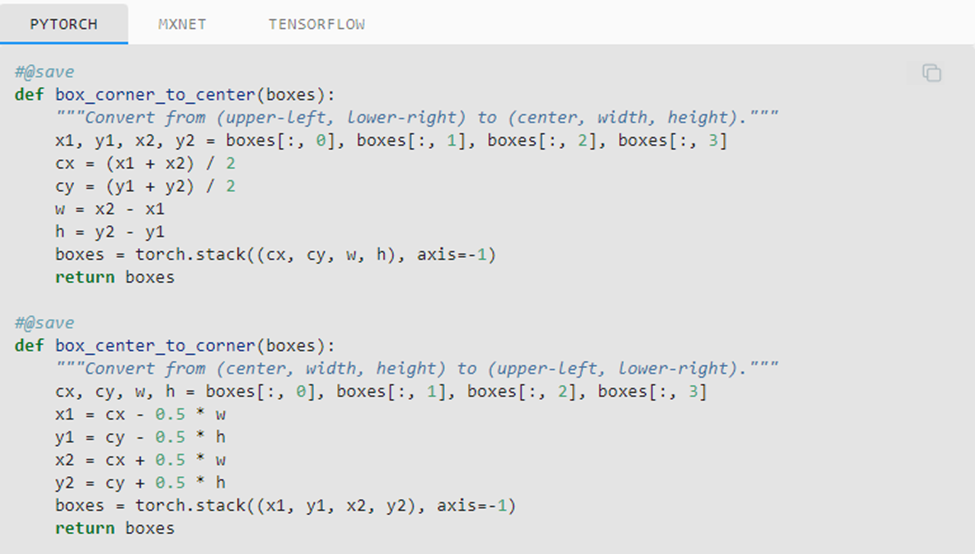
Source: d2i
Next, let’s define the bounding boxes of the dog and the cat on the image based on the coordinates data.

Source: d2i
To verify the correctness of the two bounding boxes conversion functions, we can convert twice.

Source: d2i

Source: d2i
Next, we can draw the bounding boxes of the objects on the image to check if they are accurate. Before that, we define a function bbox_t_rect which represents the bounding box in the relevant format of matplotlib package.
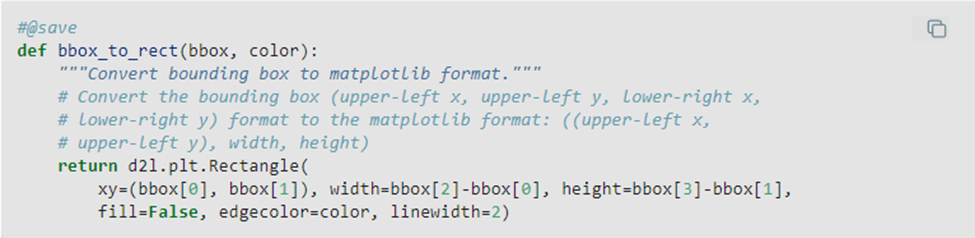
Source: d2i
Now, after adding the bounding boxes of the dog and cat objects to the image, we see that the main outline of these objects is within the two boxes.

Source: d2i
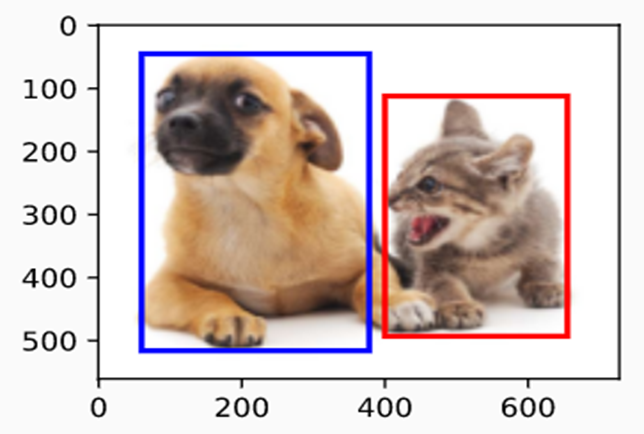
Source: d2i
Common Use Cases Of Bounding Boxes
Object Localization Of Self-Driving Vehicles
Bounding boxes are integral in training self-driving or autonomous vehicles to identify objects on the road like buildings, traffic signals, any obstructions, and more. They help annotate any obstacles and enable robots to drive the vehicle safely and prevent accidents, even in case of congestion.
Robotics Imagery
Image annotation techniques like bounding boxes are widely used to mark the viewpoints of robots and drones. These autonomous vehicles help classify objects on the earth using the photographs obtained from this annotation method.
Image tagging for eCommerce and Retail
Bounding box annotations help improve product visualization, which is a big plus in eCommerce and retail. Models trained on similar items can annotate objects like fashion apparel, accessories, furniture, cosmetics, etc., more precisely when properly labeled. Below are some of the challenges addressed by bounding boxes annotations in retail:
- Incorrect Search Results
If searching is the only way customers can stumble upon the eCommerce site, then incorrect catalog data can result in inaccurate search results, thereby not driving the customer traffic to the site.
- Unorganized Supply Chains
For those who wish to expand their retail business so millions of products can be shipped annually, it becomes imperative to have the offline and online data in sync.
- Continuous Digitization
It's critical to have all products digitized and tagged systematically and promptly to ensure that customers do not miss any new opportunities. In addition, the tags must be in context, adhering to which becomes difficult as the retail business expands and more products are added.
Detects Car Loss For Insurance Claims
The technique of bounding boxes helps track cars, bikes, or other vehicles damaged in an accident. Machine learning models use these images from bounding boxes to understand the position and intensity of losses. This helps predict the cost of losses incurred, based on which clients can present their estimate before making a lawsuit.

Source: Superannotate
Detecting Indoor Items
Bounding boxes help computers detect indoor items like beds, sofas, desks, cabinets, or electrical appliances. This lets computers get a sense of space and the types of objects present, with their dimensions and location. This, in turn, helps machine learning models in identifying these items in a real-life situation.
Bounding boxes are widely used in photographs as a deep learning tool to understand and interpret various kinds of objects.
Disease And Plant Growth Identification In Agriculture
Early detection of plant diseases helps farmers prevent severe losses. With the emergence of smart farming, the challenge lies in training data to teach machine learning models to detect plant diseases. Bounding boxes are a major driver that provide the necessary vision to machines.
Manufacturing Industry
Object detection and identifying items in industries is an essential aspect of manufacturing. With AI-enabled robots and computers, the role of manual intervention is reduced. That said, bounding boxes play a crucial role by helping train the machine learning models to locate and detect industrial components. In addition, processes like quality control, sorting, and assembly line operations which are all a part of quality management, need object detection.
Medical Imaging
Bounding boxes also find applications in the healthcare industry, such as in medical imaging. The technique of medical imaging deals with detecting anatomical objects like the heart and requires rapid and accurate analysis. Bounding boxes can be used to train the machine learning models, which will then be able to detect the heart or other organs quickly and accurately.
Automated CCTVs
Automated CCTVs are a mandate in most residential, commercial, and other establishments. Often, high memory storage is required to keep the captured CCTV footage for long. With object detection techniques like bounding boxes, it can be ensured that the footage is recorded only when certain objects are identified.
Bounding boxes can train the machine learning models, which will detect only those objects, and at that instant, the footage can be captured. Techniques such as Raspberry Pi object detection can further enable cost-effective and efficient edge-based implementation for real-time object detection in CCTVs. This would also help minimize the extent of storage required for CCTV and reduce costs.
Facial Recognition and Detection
Facial recognition offers multiple applications, such as it is used in biometric surveillance. Besides, various agencies like banks, airports, retail shops, stadiums, and other institutions use face recognition to prevent crimes and violence. That said, facial detection is an important element of computer vision that involves image processing. And here again, bounding boxes can be used as an effective tool for character recognition.
Bounding Boxes For Character Recognition
Object detection comprises - image classification and object localization. This means for a computer to detect an object, it needs to know what is the object in question and where it is located. Image classification assigns a class label to an image. Object localization is related to drawing the bounding box around the object in question in an image.
The process involves an annotator drawing the bounding boxes around the objects and labeling them. This helps to train the algorithm and allows it to understand what the object looks like. As the first step for object detection, the image dataset must have labels.
To label an image, follow the below steps:
- Pick the dataset that you want to train and test. Make a folder of it.
- Let’s take the example of a face detection project like: BTS, Avenger, etc.
- Make folder name data.
- In Google Drive, create a folder with the name FaceDetection.
- In the FaceDetection folder, make a folder of the image.
- In the image folder, make folders of the test image, test XML, train image, and train XML.

Source:indusmic
Now, in the train image folder, download and upload 10-15 images of BTS and Avengers in JPEG format. Similarly, in the test image folder, do the same for 5-6 images. It’s recommended to have more images in the dataset for accurate results.
Source: indusmic
Source: indusmic
Next, generate an XML file for each image of the test image and train image folders
Download and click windows v_1.8.0. Click on the .exe file from GitHub and press Run.
Next, click the open directory to select the folder of the image. You will see the image that has to be labeled. To label, press W on the keyboard and right-click and drag the cursor to draw the box around the object. Give it a name and click OK.
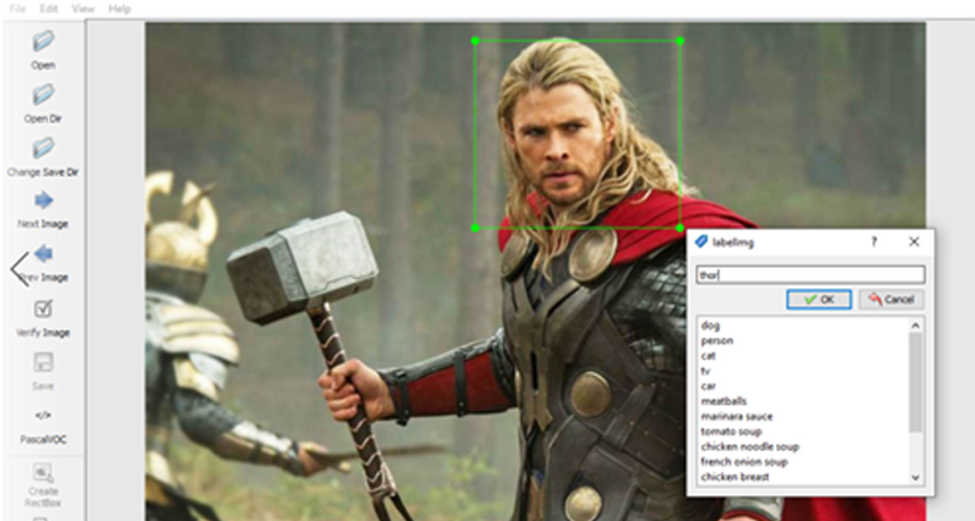
Source: indusmic
Next, save the image to generate the XML file of the image in the image folder, as shown below.
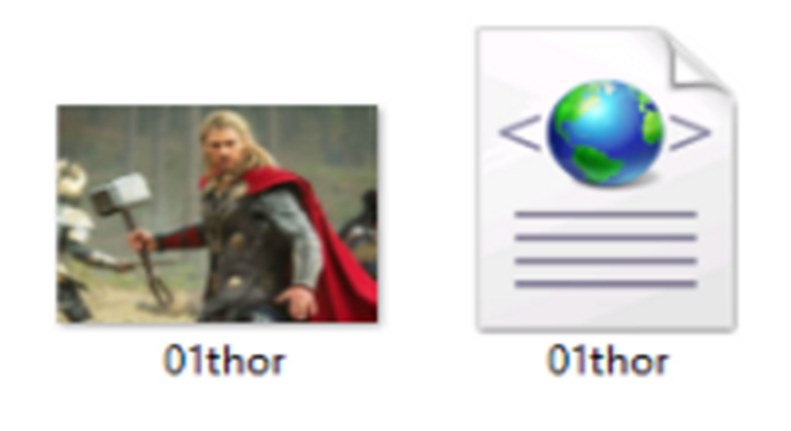
Source: indusmic
Open the XML file to see the coordinates.

Source: indusmic
Repeat the procedure for all the images to generate the XML files and look for the coordinates.
Various Annotation Formats Used In Bounding Boxes
Essentially, a bounding box has 4 points in (x,y) axes representing the corners:
Top-left : (x_min, y_min)
Top-right: (x_max, y_min)
Bottom-left:(x_min, y_max)
Bottom-right: (x_max, y_max)
The coordinates of the bounding box are calculated with respect to the top-left corner of the image.
There are several bounding box annotation formats, each using its own representation of the bounding box coordinates.
a. Albumentations
They use four values to represent the bounding box - [x_min, y_min, x_max, y_max] - which are normalized by dividing the coordinates in pixels for the x-axis by the width and y-axis by the height of the image.
Say the coordinates of the bounding box are: x1 = 678, y1 = 24; x2 = 543, y2= 213.
Let width = 870, Height = 789
Then, [678/870, 24/789, 543/870, 213/789] = [ 0.779310, 0.030418 ,0.624137, 0.269961]
Albumentations uses and interprets these values internally with bounding boxes and enhances them.
b. COCO
This is a format used by the Common Objects in Context COCO dataset. In COCO format, a bounding box is represented by four values: (x_min, y_min, width, height). Essentially, they refer to the top-left corner and the width and height of the bounding box.
c. YOLO
In this format, a bounding box is presented with four values :(x_center, y_center, width, height). Here, x_center and y_center denote the normalized x and y coordinates of the center of the bounding box. To normalize, the x coordinate of the center by the width of the image and the y coordinate of the center by the height of the image. The values of width and height are also normalized.
d. PASCAL
In the Pascal format, the bounding box is represented by the top-left and bottom-right coordinates. So, the values encoded in pixels are: [x_min, y_min, x_max, y_max]. Here, [x_min, y_min] is that of the top-left corner, while [x_max, y_max] denotes the bottom-right corner of the bounding box.
Precautions And Best Practices In Using Bounding Boxes
Some precautions and best practices are recommended for optimum use of bounding boxes in image processing. They include:
Box Size Variations
Using all bounding boxes of the same size will not render accurate results. Training your models on bounding boxes of the same sizes would make the model perform worse. For example, if the same object appears smaller in size, the model may fail to detect it. In the case of objects appearing larger than expected, it may take up a greater number of pixels and not provide the precise position and location of the object. The crux is to keep in mind the variation in size and volume of the object to achieve desired outcomes.
Pixel-Perfect Tightness
Tightness is a crucial factor. This means the edges of the bounding box must be as close to the object in question as possible for accurate results. Consistent gaps may impact the accuracy in determining the area of overlap between the model’s prediction and the real object, thereby creating issues.
Diagonal Items Placed In Bounding Boxes
The problem faced with items diagonally placed within a bounding box is that they take up considerably less space inside the box as compared to the background. However, if exposed longer, the model may presume that the target is the background as that consumes more space. So, as a best practice, it is recommended to use polygons and instance segmentation for diagonal objects. Yet, it is possible to teach the models with a bounding box with a good amount of training data.
Reduce Box Overlap
It is always safe to avoid annotation overlaps in all scenarios. Sometimes, this might cause so much clutter that only some overlapping boxes may be finally visible. Objects that have a labeling overlap with other entities produce relatively worse outcomes. The model will fail to differentiate between the target object and other items due to excessive overlapping. In such cases, polygons may be used for higher accuracy.
Conclusion
Image processing is an emerging realm of technology that offers wide scope. That said, bounding boxes form the most commonly applied image processing technique.
To sum up, bounding boxes are an image annotation method to train AI-based machine learning models. It’s used for object detection and target recognition in a wide range of applications, including robots, drones, autonomous vehicles, surveillance cameras, and other machine vision devices.
Suggested Resources:
- Bounding Box Deep Learning: The Future of Video Annotation
- Annotating With Bounding Boxes: Quality Best Practices
Nanonets online OCR & OCR API have many interesting use cases that could optimize your business performance, save costs and boost growth. Find out how Nanonets' use cases can apply to your product.