
In AI agents, a context graph is the part of agent memory that captures decisions.
This post explains why agents need to capture decisions, how context graphs achieve this, and how agents can use these graphs.
An agent failure case
It's the last week of the quarter. A renewal agent is working a $480k account. The customer wants 20% off or they walk. The agent's instructions state >$100k accounts should not churn, but the agent's policy caps renewals at 10%. Now what?
If a human was handling this, they'll probably use experience and memory to resolve.
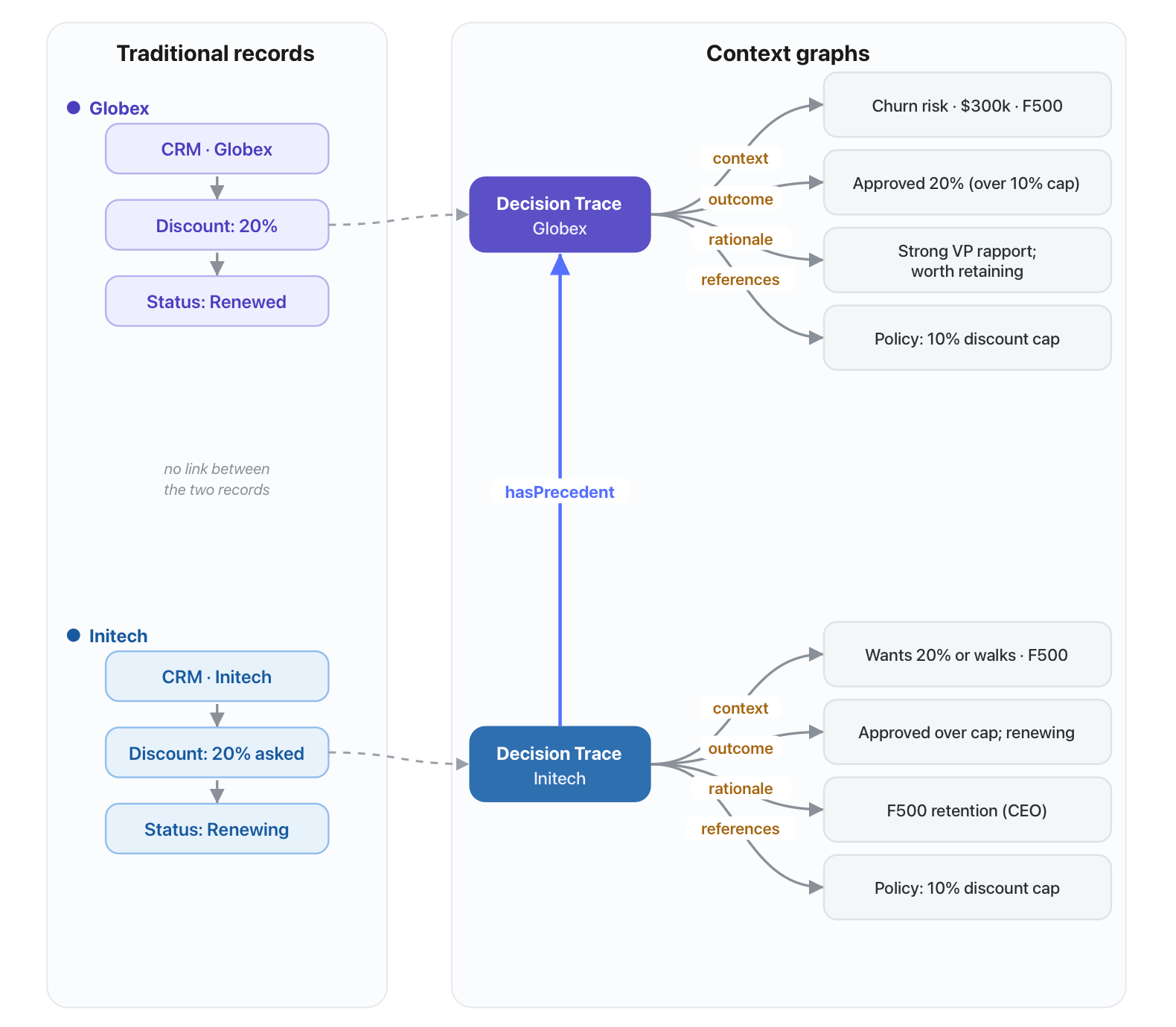
Didn't we do this exact thing with Globex last quarter? It was a similar story. They were threatening to churn, and someone signed off on 20% because the CEO wanted to retain Fortune 500 logos and the risk was worth taking on a $300k account. It worked and Globex renewed shortly after.
This reasoning chain that makes the decision is not written down anywhere your agent can read. The agent will find Globex's exception case in Salesforce, but Salesforce will not tell it that the number was an exception, who approved it, why it was approved, whether the current situation is identical or not.
The why lives in -
- Old slack threads where finance team admits a $300k account is worth the risk.
- Zoom calls where sales veterans mention these kind of accounts pay eventually.
- Emails from the CEO saying retaining Fortune-500 logos is critical.
These are critical pieces of information needed to make the decision, but the agent cannot access them.
So your agent does one of three things -
- It sends an email informing the policy caps at 10%, and you lose the account.
- It escalates to a human, who spends 24 hours doing Slack archaeology to reconstruct a decision the company already made once.
- It makes 500 grep calls via agentic search, and exhausts a large amount of tokens searching, reading, reasoning, and reconstructing context from multiple systems of record. And this happens every time a similar decision needs to be taken.
Either way, the organization failed to benefit by adopting an AI agent.
This is a universal problem. Organizations lose billions each year -
- making the same mistakes,
- reinventing the same solutions,
- wasting time and money on previously solved problems,
- being incredibly slow at onboarding new employees,
- struggling with compliance and audit gaps in an AI-native world.
This is because we have gotten extremely good at recording what happened, but we systematically throw away why it happened, which is the one thing your agent needed here.
Context graphs store the why in an agent's memory.
Foundation Capital called it "a trillion-dollar AI opportunity", which is the kind of phrase that sends people reaching for the back button. But stick around anyway. The term is new and a little overloaded, but it points at something real. If you use or build agents, you'll end up using a context graph soon.
Flat context is bad
The bad way to give your AI agents context is to just give them all the data, records, documents, rules, policies in a flat context window.
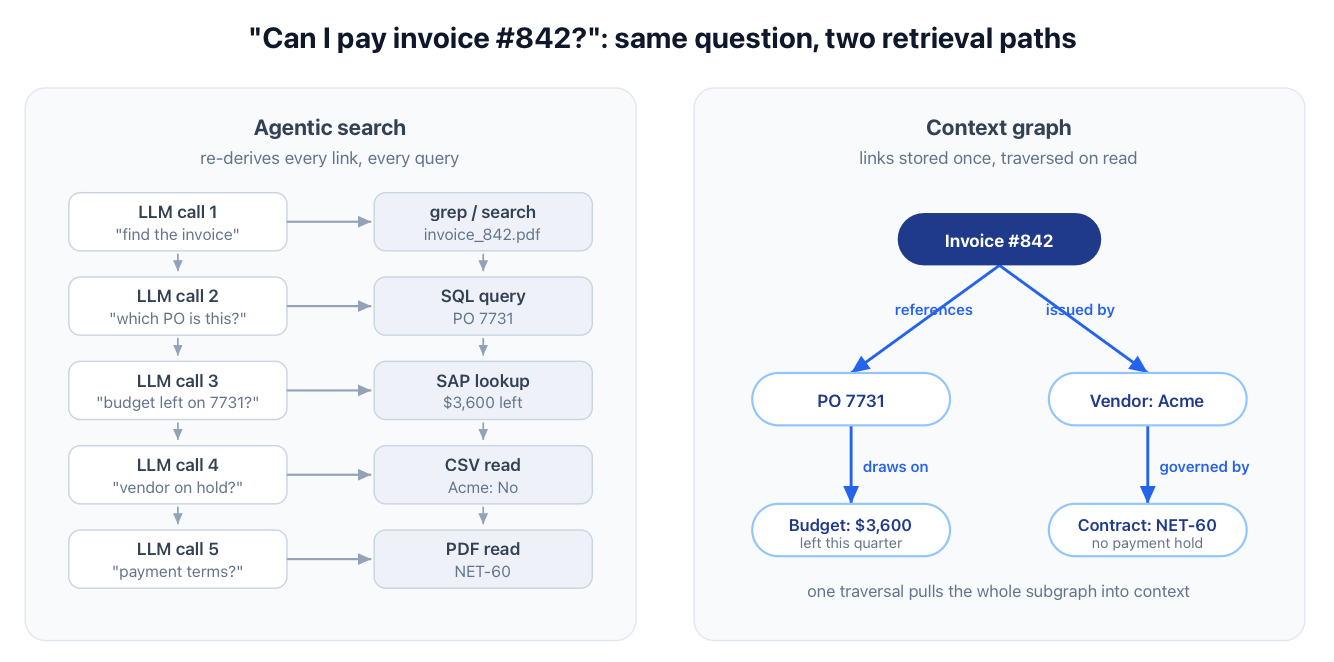
Say you have an invoice processing agent. You dump the invoice, PO, vendor record, contract, policy document into the context. Then watch the agent fail. Why?
1. Context rot
When the agent asks itself “can I pay invoice #842?” To answer, it has to hop - which PO does this invoice reference? does that PO still have budget? was the delivery received? is the vendor on payment hold? does $12,400 cross the approval threshold? what do the contract's payment terms say? is the policy doc accurate and up-to-date? are there undocumented nuances related to this invoice payment currently living on Slack messages and Zoom call transcripts?
Flat retrieval tries to hand this massive amount of information to the LLM model in a pile of disconnected chunks. Some invoice text here, some PO text there, some language from random docs and slack channels, all given as a flat wall of text.
“Can I pay invoice #842?”
Dana 10:21
Acme always pays end of quarter — don’t chase them.
Wes 10:22
noted 👍 leaving #842 as-is
| A · Vendor | B · On hold | |
| 1 | Acme Corporation Ltd | No |
| 2 | Globex LLC | Yes |
| 3 | Initech | No |
The agent is forced to re-derive every one of those connections between these pieces of data from scratch on each turn. Flattening business data into loose text destroys exactly the structure it needs.
And as context becomes large, LLMs struggle to cope up with the size and start failing in their tasks. They fail to follow instructions, drop rules randomly, misunderstand the relation between two pieces of information far apart, ignore middle-of-context data, apply rules and constraints out of order.
Surge AI documents this in their instruction-following benchmark. The best frontier model solves <41% of such complex tasks.
2. Lack of decision traces
Like we saw in our first example, AI Agents run into the same ambiguity humans resolve every day with precedents, experiences, organizational memory. But you can't give these things to an agent in a flat context window.
- Tribal knowledge. "We always waive the $5k onboarding fee for logistics companies but only if they push back on the timeline first." That's not in the CRM. It's tribal knowledge passed down through internal conversations.
- Past decisions. "We structured a deal for account X where they split payments into installments. We should offer this similar account Y the same." No system links the two deals to convey why Y's contract was drafted this way.
- Context across systems of record. An account manager sees usage sliding in the product dashboard, an unpaid invoice in NetSuite, a cold one-line email. They flag the account as "churn risk" in the CRM. The reasoning happened in their head, but the CRM record just shows "churn risk".
- Manual approvals. A VP approves a discount on a Zoom call. The Hubspot record shows the changed price. It doesn't show why this decision was made.
Reasoning behind data, decisions, actions isn't captured in a flat context window.
If you are a developer, this concept hits even harder. Why did we pick this queue over that one in 2019? Why is there a sleep(200) in the retry path that breaks everything when you remove it? It was obvious to whoever wrote it, but that information is gone now.
Remember Architecture Decision Records? They were invented back in 2011 to fix exactly this. But most ADR folders die at three entries, because writing them is friction and nobody reads them later.
This is a universal problem. Companies are good at storing what happened, and bad at storing why they happened. This is because the why is unstructured, spread across systems, and nobody reads it even if you store it.
Both problems, context rot and lack of decision traces, are solved by context graphs.
What is a context graph?
A context graph is a way of structuring an agent's memory as a graph, where nodes hold pieces of information and edges hold the relationships between them. It's optimized for the agent to read, not for a human to browse.
Most agent memory today is flat, and is implemented in one of two ways -
- AI agents embed your data, split them into chunks, and return the few chunks that look most similar to the ongoing task. The LLM gets a pile of text with no sense of how these chunks connect to one another. This is vector RAG, the standard memory used in AI agents today.
- AI agents are given tools to iteratively search your systems of record to find context (grep, file read, SQL queries, APIs to search and read). This is costly, and again, the LLM needs to infer connections between the chunks of data it retrieves.
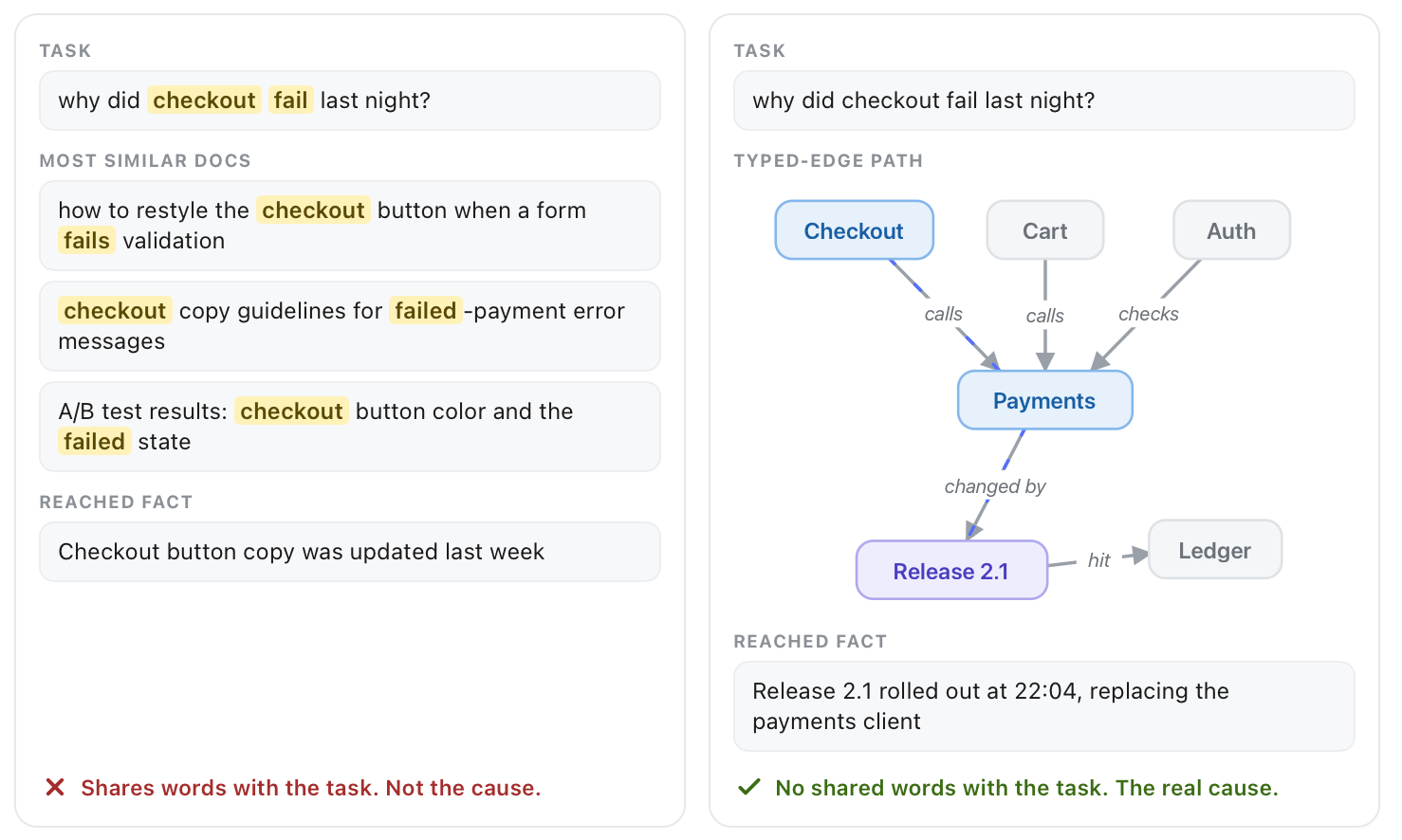
A context graph keeps those connections in a graph. Instead of "here are five similar paragraphs," it can say "Service A –depends on–> on Service B," "this release –caused–> that outage," or "this invoice –follows–> that policy." The edges carry meaning, and the model can traverse them.
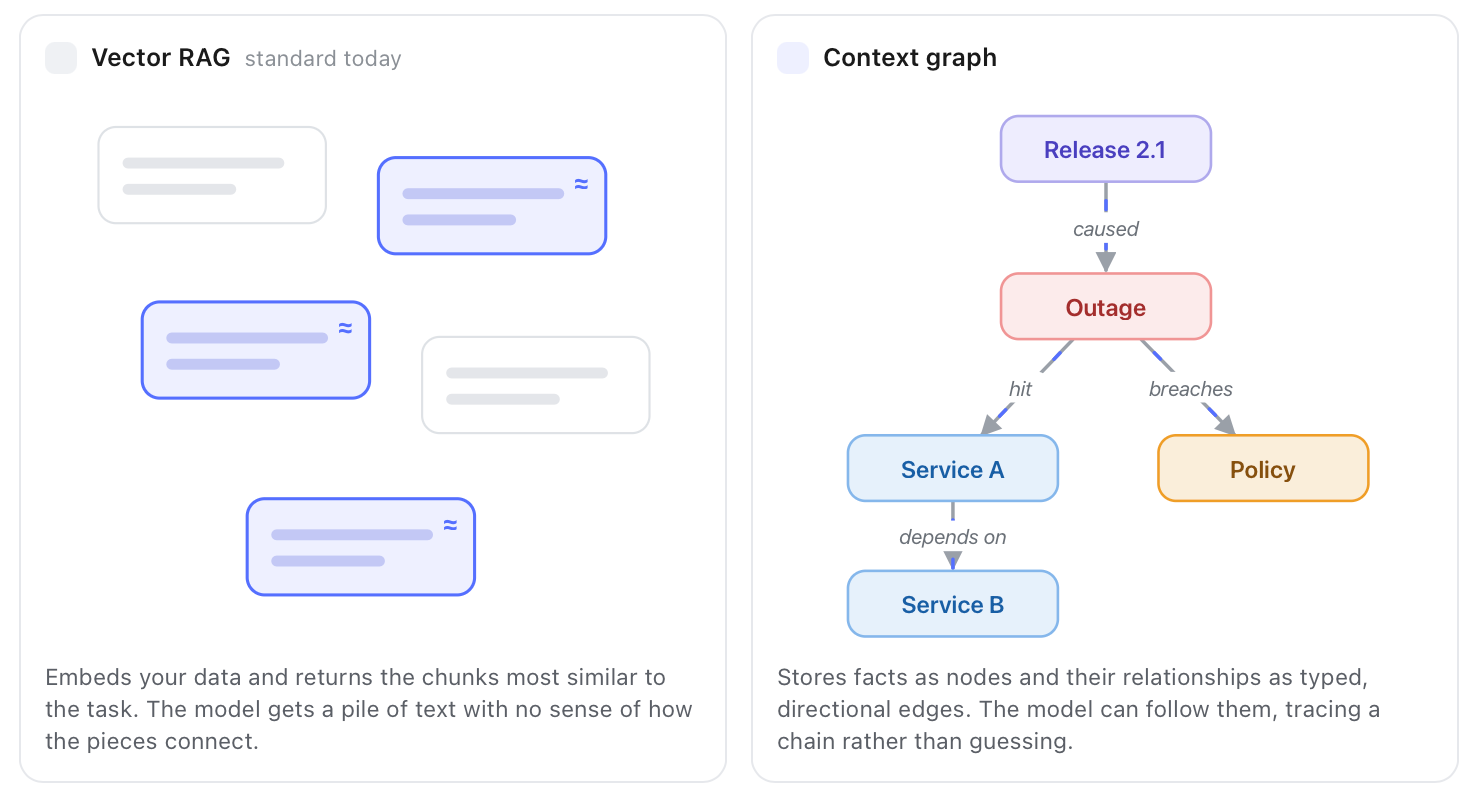
This matters because similarity is not relevance. Two chunks can share words with your task and still have nothing to do with your actual task. Two other chunks can share no words with your task and still relate to your task semantically.
How to create a context graph?
A context graph goes after both failures, context rot and lack of decision traces, by changing what you store and how.
Start with "how you store". You store your business as a graph. Entities, for example, the invoice, the PO, the account, the vendor, the contract, the policy, the approver, are all nodes in the context graph. The relationships between them are edges. This invoice –references–> that PO. This PO –draws on–> that budget. This budget –approved by–> that person. This vendor –governed by–> that contract.
“Can I pay invoice #842?”
You store each of those links once, instead of leaving the model to re-derive them from chunks of text every time it needs them. For each task/subtask, the agent pulls a small subgraph and leaves the other ten thousand records out of the window. Context rot goes away, because the window stays small and on-point.
Now the "what you store". You now also store each decision in a context graph. The unit of this context graph will be a decision trace. A flat record stops at the outcome "Initech renewed at 20%". A decision trace keeps the story behind it. The problem that triggered it, the options weighed, why the rejected ones lost, the constraints, the exceptions, who decided, and the reasoning.
This is also what an employee keeps in their head. But with a context graph of decision traces, an agent can read it.
Entities and their relationships, plus decisions and their relationships to entities and other decisions, created across systems of record and time. Foundation Capital's one-liner for it is a "system of record for decisions". Most of your systems already store the current state of things. A context graph stores how the state got that way.
You use a schema for the decision trace that is ideal for your use case.
Now the second half is turning old decisions into something the agent can lean on.
How to use a context graph?
Few implementation details when using context graphs -
Capture it on the way in
Agents with context graphs need to be low friction, otherwise no one will want to maintain them. Capture the decision the moment it is made, not later.
Reconstructing context after the decision will be lossy guesswork, and also costly and time consuming. The meeting is over, the Slack thread scrolled away, the person left the company. Most of the agent's context has slipped away without getting saved in the agent memory.
Capture it when the decision is made, at almost no extra effort. All of the context is already there in the active context window. Also if a human overrides the agent's decision, that override is the moment to ask why and store the answer with minimal friction from the human.
Reconstructing it later
Rationale: "approved, see Slack"
Approved by: ???
outcome: 20% (exception to cap)
rationale: logo worth the risk
links: DEC-2025-118, policy v4
"F500 logo. Worth the risk at $300k."
human decided: 20%
rationale: F500 logo retention, CEO directive
decided by: VP Sales
OLD ORGANIZATIONAL MEMORY
AGENT IN THE EXECUTION PATH
reading: every run, tirelessly
This is also why agents change the economics of organizational memory. We have always known we lose the why. Wikis, Confluence, post-mortems, ADRs: every one of them tries to save it, and every one decays, for the same two reasons. Writing it down is friction, and nobody reads it back.
Agents break both at once. The agent sits in the execution path, so capture is a side effect of doing the work, not an extra task bolted on afterward. And the agent is a tireless reader that will happily consult ten thousand past decisions before making the next one. Organizational memory finally has a reader worth writing for.
Use stored decisions as precedent
Once decisions live in the graph, search turns them into precedent.
- a new decision choice shows up
- the agent pull the direct context (entities and their relationships)
- the agent pulls the closest precedents (past decisions)
- the agent reasons on the direct context and precedents
- the agent takes a decision (or suggests it)
- decision is taken
- decision is stored as a decision trace in the context graph
- decision is linked to similar past decisions in the context graph
You can use vector embeddings to find semantically similar decisions, and then apply graph-based filters to narrow by entity properties.
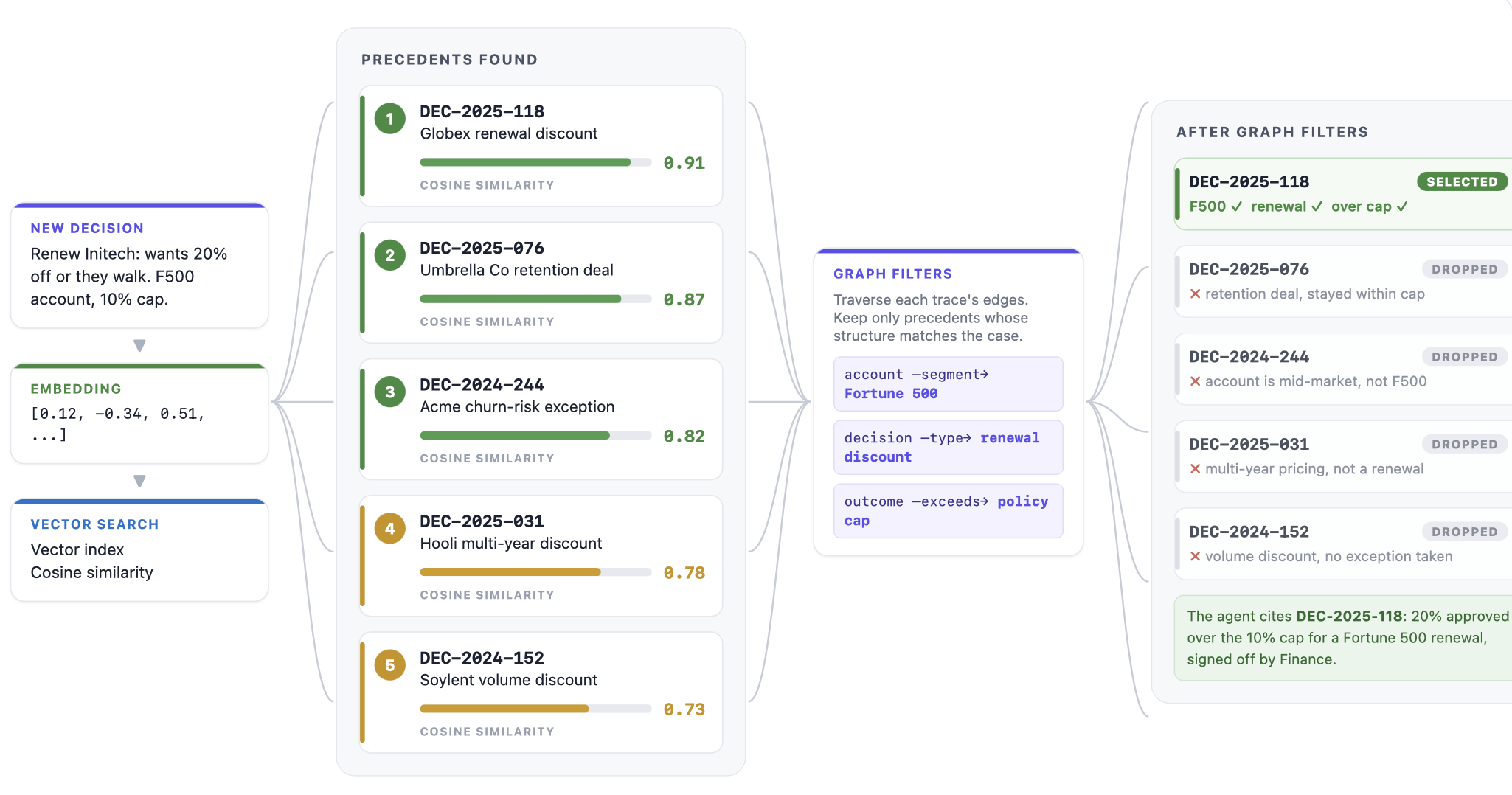
A pile of old decisions becomes memory the agent can actually use. This is also how an agent enter a mode of self-learning without anyone fine-tuning it or updating rules/instructions.
- paid late once last year
- $500k renewal at risk
- #348 on the Fortune 500
- late twice but still granted
- $540k judged worth the risk
- #211 on the Fortune 500. Great logo.
There's a second payoff here. Because traces record exceptions, not just the clean path, you can see when a rule keeps getting overridden. If AP grants the same late-payment exception to twenty vendors, the policy is wrong, not the vendors. The graph can turn this pattern into a signal to fix the underlying policy itself.
was granted this quarter
Over time, the context graph becomes the real source of truth for autonomy, and your company can easily audit and debug this autonomy.
The recent ACE paper, "Agentic Context Engineering", makes the mechanism concrete:
Treat the accumulated context as a playbook that grows through generation, reflection, and curation, and let real outcomes refine it. The agent gets better by editing what it knows, not by touching a single weight. A correction today becomes a rule tomorrow. A trace today becomes precedent next quarter. This feedback loop enables learning in agents.
Example of an agent using context graphs
Similar to knowledge graphs?
The parts are the same, but the implementation is new.
Knowledge graphs have been around since Google shipped one in 2012. Event sourcing, storing the sequence of events instead of just the latest state, is a pattern any backend engineer already knows. A context graph is close to event sourcing for decisions, where each event drags along its rationale and its links to everything.
So there's no new primitive here. What's new is that you capture the why on the write path as structured data, because for the first time there's a consumer, i.e. the agent, hungry and tireless enough to read it.

Standard RAG, for contrast, retrieves documents that look similar to your question. A context graph retrieves decisions, with their reasoning and their edges to everything they affected. One hands the model text to read. The other hands it structure to walk and precedent to reason from.
Isn't agentic search enough?
There's a sentiment these days that agent memory and retrieval methods are outdated, and agentic search works better. Give the model simple tools (grep, file read, SQL queries, list directories, search) in the agent loop, and let the model itself decide what to look up, look at the result, and search again.
Claude Code initially shipped like this. It just gave the model grep, glob, file-read tools, and the model navigated codebases like a human developer would. And the surprising result was it worked better than Cursor who were using standard RAG.
A recent paper (AgenticRAG) measured retrieval. One-shot search on the BRIGHT benchmark got 8.4% recall, and the same retriever inside an agentic search loop got 49.6%. On FinanceBench, agentic search hit 92% answer correctness, where handing the model perfect evidence gets 94%.
Agentic search works. Given enough turns, the agent finds almost everything that exists in the data.
So why bother with a graph? Two reasons.
1. Agentic search is a brute-force loop, and you pay for it on every query.
That 92% on FinanceBench cost 115K tokens per query, about 8x the single-shot cost. Every hop is another LLM call, so latency stacks the same way. And the agent re-derives the same links every time. Which PO does this invoice reference? Is the vendor on hold? It answered that yesterday, and it will need to answer it again tomorrow.
| Accuracy | Tokens/query | Latency | |
|---|---|---|---|
| Agentic search | very high | very high (multiple LLM calls) | seconds |
| Context graph | high | very low | microseconds |
The graph employs memoization. It stores each link once, and the agent traverses instead of re-deriving. Other benchmarks bear this out.
- A2RAG put a graph under an agent loop and cut tokens and latency by ~50% while gaining ~10 points of recall.
- GRASP got the highest multi-hop accuracy while spending 40-50% fewer tokens than the strongest search-only baseline.
- A benchmark paper literally titled "Do We Still Need GraphRAG?" found that agentic search narrows the gap, but the graph still wins on hard multi-hop questions and makes the agent's search behavior more stable.
2. Agentic search can only find what was written down.
The Initech decision wasn't in any text. Salesforce shows Globex renewed at 20%. It doesn't say that was an exception, who signed off, or why. The reasoning lived in a Zoom call and three Slack replies, and half of it never left anyone's head.
An agent with search tools will find the what and might still miss the why, because the why was never stored. No search method fixes a write-path problem. But a context graph mandates the storage of every decision trace the moment it is made.
To summarize, agentic search is the correctness baseline, and it's probably still the best method for some tasks. But the context graph does two things on top of it.
- It caches the hops the agent would otherwise recompute on every query, which is a cost, latency, and in some cases, accuracy optimization.
- It forces the capture of reasoning at decision time, which search alone can never recover after the fact.
Maybe we let the agent search when the graph comes up empty, and write what it learns back into the graph so the next run doesn't have to?
System-of-record agents won't work
Systems of record probably have it wrong. Salesforce released Agentforce, ServiceNow released Now Assist, Workday is doing something similar. Their reasoning is to add intelligence where the data resides.
But their agents will inherit the exact same limitations as their parents.
- Systems of record capture what changed, not why. Salesforce tracks field history, but only for a limited set of fields, and only for a while. And when someone approves a discount, no field anywhere stores the reasoning. The context of the decision is gone the moment it's made.
- These systems also miss data. A support ticket doesn't just live in Zendesk. It needs user tiers from CRM, SLA terms from billing, recent outages from PagerDuty, Slack thread flagging churn risk. No single system of record sees the whole picture. And each vendor's agent treats its own system as the center of the universe.
Systems of record are building their own agents, locking down APIs (ahem ahem), and slapping egress fees, but they can't insert themselves into an orchestration layer they were never part of.

When an agent triages an escalation, responds to an incident, or decides on a discount, it pulls context from multiple systems and time periods. The orchestration layer alone sees the full picture - what inputs were gathered, what policies applied, what exceptions were granted, and why decisions were taken.
Because it's executing the workflow, it can capture that context at decision time instead of bolting on governance afterwards.
This is the essence of a context graph, and that will be the single most valuable asset for your company in the era of AI.
The hard parts
Before you get too excited -
- Garbage in, garbage precedent. If the captured rationale is lazy ("approved, see Slack"), your precedents are landfill. The graph is worth exactly the quality of the why you put in it, and writing a good why is real work. But this time, it is certain this work will reap benefits.
- Who writes the trace. If a human has to type thoughtful rationale every time, it might rot the same way as a wiki. If the agent infers the rationale, you have to trust the inference, and "the model guessed why we did this" is a shaky base. The real answer is somewhere in between, and getting that right is not trivial.
- The decision swamp. A better name today for data lakes that exist in organizations would be data swamps. We dump everything in them with no schema and no curation. A graph of millions of contradictory, half-true traces is the same failure with extra edges. Without curation, more traces make precedent search worse, not better.
- This is early. Most vendor decks make it sound shipped. It isn't. The pattern is sound and the early results are unbelievably good. There is something here, definitely. But "great early results" is not "proven," and anyone who tells you otherwise is pitching.
The full stack
An AI-native workflow with context graphs has four layers -
1. Systems of record. Salesforce, SAP, Zendesk, GitHub, Slack, the Zoom transcript from this morning's call. They hold the state of your business - every record, ticket, commit, and message. What they don't hold is the reasoning that connects them. But they're still the ground truth for what is.
2. The harness. It sits in the execution path and runs the reason → act → observe loop. It holds the tools, picks what goes into the model on each step, stores corrections as memory, checkpoints long runs, enforces permissions, logs every decision, and catches errors before they crash the run. This engine turns a stateless LLM into a system that finishes work.
3. The context graph. As the harness runs, every decision leaves a trace: what inputs it gathered, which rule it applied, what exception it took, who approved, and why. The graph stitches those traces across entities and time. Your systems of record stay the truth for what happened. The graph becomes the truth for why.
4. Agents and humans. Agents execute the routine cases end to end. Humans handle the cases the agent flags as uncertain. Every correction a human makes flows back into memory and the graph, so future agent runs are better.
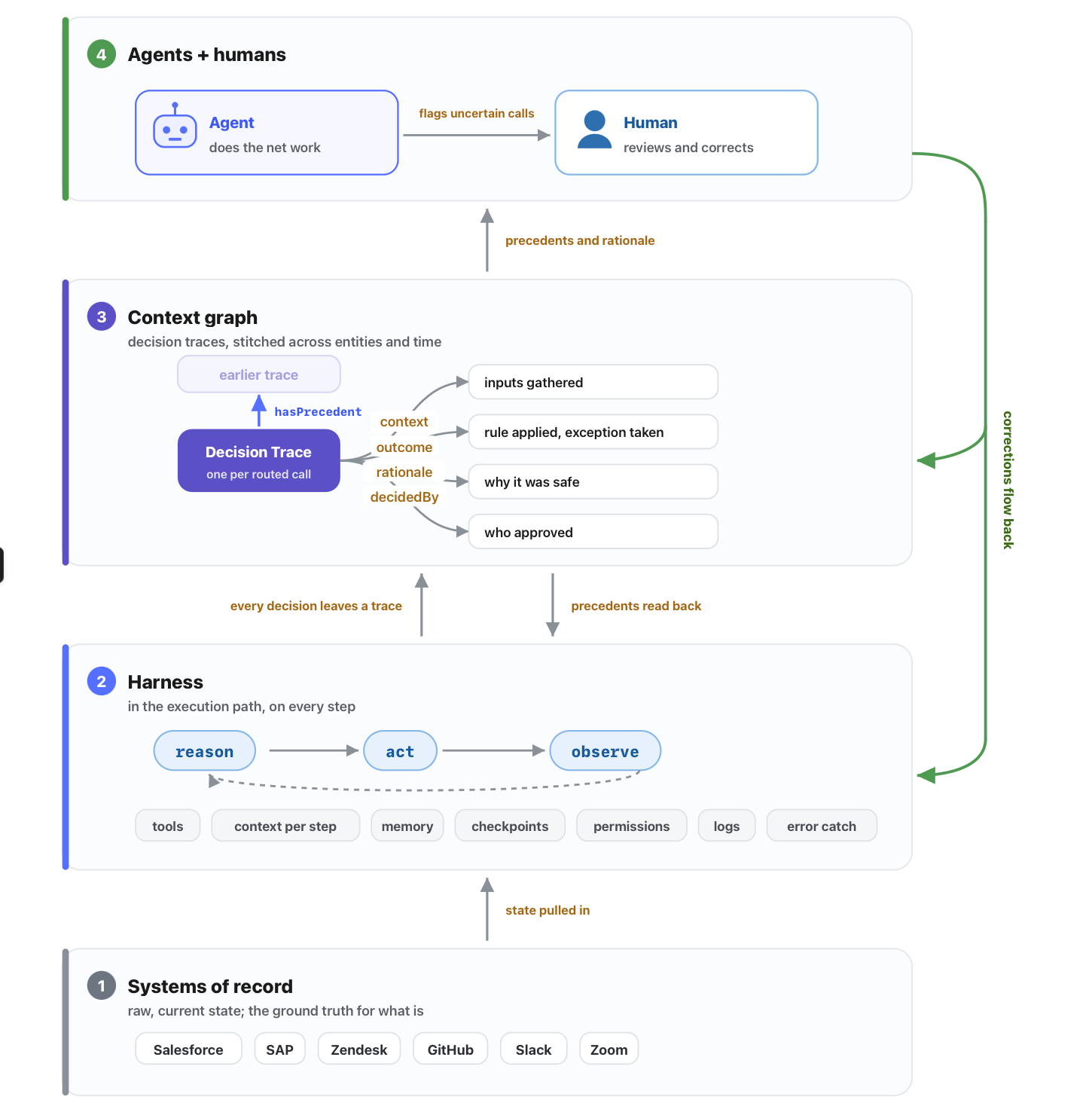
This maps to the two core features of AI-native organizations, Universal context and Loops.
- Universal context is your systems of record made queryable through the context graph. The agent doesn't re-derive the links between an invoice, a PO, a contract, and a Slack message on every turn. The graph already holds them.
- Loops are the harness closing feedback on every run. A correction today becomes a rule tomorrow. A decision trace today becomes precedent next quarter.
Where to start
Build a context graph when your agents run long, decisions made early have to survive many turns, and questions chain facts together. That's most multi-agent work.
Enterprises and startups we work with use context graphs to automate processes with -
- High team size. If you have 50 people running a workflow manually. The headcount is high only because the decision logic is too complex to automate with traditional AI tools.
- Exception-heavy decisions. Think about procurement, insurance claims, deal desks, compliance. In these jobs, the answer is always "it depends."
- Cross-functional roles. RevOps, FinOps, DevOps, Security Ops. These roles emerge precisely because no single system of record owns the cross-functional workflow. Your company creates a role to carry the context.
Procurement, finance, claims, deal desk, underwriting, escalation management are few examples.
Context graph as a map
A clean way to hold all of this in your head:
The model is your brain, the agent / agentic harness is your limbs, and the context graph is the map of your specific world (or company). A superb body with no map of your world stalls at every fork in the road that requires knowing the map, and enterprise processes are nothing but those forks.