Healthcare data extraction remains a significant hurdle, with the sector requiring 7.7x more administrative workers than other industries. Automating healthcare data extraction can help organizations reduce operational spending and streamline their processes while improving patient care.
Healthcare data extraction systems capture and extract crucial information from a range of healthcare documents—patient registration forms, insurance forms, lab results, billing information, regulatory compliance documents, and more. The extracted data is processed and neatly organized into structured formats. The result? Everyone in the healthcare ecosystem benefits: Doctors, nurses, administrative staff, billing departments, et al. Plus, being able to quickly access critical data will lead to smarter decisions across clinical, operational, and financial domains and help offer a better patient experience.
This guide will help you quickly get up to speed with healthcare data extraction. We'll show you how it's transforming the entire healthcare ecosystem, its benefits, and practical steps to implement it in your organization.
The current state of healthcare documentation
Healthcare documentation is the backbone of patient care and organizational operations, but it's also become a monster that's eating up valuable time and resources. Over 71% of clinicians report feeling overwhelmed by the sheer volume of information available.
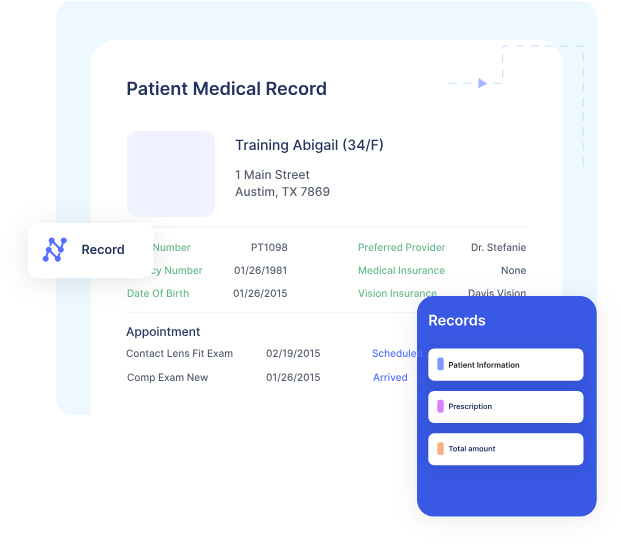
By 2025, it's estimated that the United States will need to hire an additional 2.3 million new frontline healthcare workers due to inefficient data extraction from healthcare documents. This staggering number highlights a critical issue in the industry.
In the current healthcare system, professionals across clinical and administrative roles spend countless hours sifting through patient records, insurance claims, medical reports, billing information, and regulatory documentation. This manual process is not only time-consuming but also prone to errors.
Here's a breakdown of common document types that healthcare organizations are likely grappling with:
- Electronic Health Records (EHRs)
- Electronic Medical Records (EMRs)
- Clinical notes and progress reports
- Lab and imaging results
- Insurance claims and billing information
- Regulatory compliance documents
- Administrative and operational records
- Staff credentialing documentation
- Quality assurance and performance metrics
- Patient registration forms
Unstructured data, like handwritten notes, adds complexity to information management. Each document type may also require specific handling, storage, and retrieval processes. For healthcare administrators, managing this diverse ecosystem efficiently is crucial for maintaining smooth operations and ensuring quality patient care.
Relying on manual data entry and document processing may stress your entire healthcare organization. It can:
- Slow down patient care
- Increase the risk of errors
- Delay insurance reimbursements
- Create backlogs in processing patient registration forms
- Complicate regulatory reporting
- Burden healthcare workers with administrative tasks
- Increase the risk of HIPAA violations and data breaches
Manual data extraction is not just time-consuming; it's a minefield of potential errors. Consider this: 30% of patient charts are misplaced due to inefficient tagging and document archiving. Even more alarming, over 80% of all serious medical errors occur during care transitions, often due to miscommunication or missing information.
The need for a more efficient system is clear. An intelligent automation platform like Nanonets can transform this landscape. By automating just 36% of healthcare document processes, the industry could save up to $11 billion in claims alone. Beyond claims processing, automation can streamline administrative workflows, improve regulatory compliance, and allow healthcare professionals to focus on what matters most: patient care.
What is automated healthcare data extraction?
Simply put, it is the process of automatically pulling relevant information from various healthcare documents using advanced technologies.
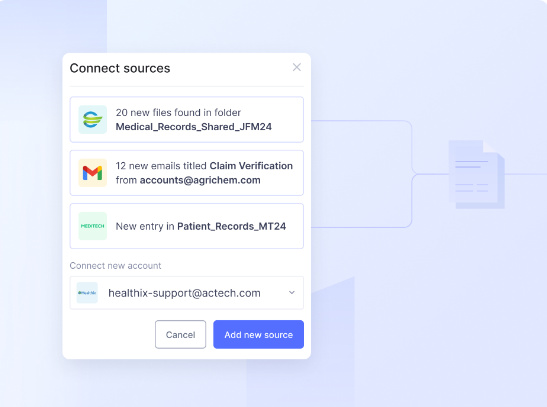
It involves:
- Identifying key information in documents
- Categorizing data into structured formats
- Integrating extracted data into existing systems
Healthcare data extraction relies on a combination of Optical Character Recognition (OCR), Artificial Intelligence (AI), Natural Language Processing (NLP), and workflow automation technologies to capture, extract, and process data with impressive accuracy and speed.
Healthcare data extraction spans multiple domains within the healthcare ecosystem:
Clinical data extraction focuses on patient-specific information like medical histories, diagnoses, lab results, and treatment plans.
Administrative data extraction handles information related to appointments, scheduling, patient registration forms, staff management, and facility operations.
Financial data extraction processes billing information, insurance claims, payment records, and reimbursement documentation.
Regulatory data extraction manages compliance documentation, quality metrics, and reporting requirements for healthcare governing bodies.
The impact of data extraction tools in healthcare
Let's walk through a practical scenario that demonstrates how healthcare data extraction revolutionizes the entire healthcare experience. We'll follow a patient, let's call her Sarah, through her journey:
Pre-clinical visit
Without automated data extraction:
- Sarah calls to schedule an appointment, spending time on hold
- She arrives early to fill out paper forms, often repeating information
- Staff manually enter her details into the system, risking errors
With automated data extraction:
- Sarah books online by simply filling out a form
- The form data is automatically captured and integrated into the hospital's EHR system
- The system extracts and validates her insurance information in advance
- Any missing information is flagged for follow-up before her visit
During the visit
Without automated data extraction:
- Sarah waits while the staff verifies her information and insurance
- The doctor spends time sifting through paper records or multiple digital systems
- Prescriptions are handwritten, risking misinterpretation
With automated data extraction:
- Sarah's identity is quickly verified against extracted data
- The doctor accesses a comprehensive, up-to-date patient history instantly
- The doctor can quickly create prescriptions digitally and automatically added to the hospital's EHR system
Post-clinic visit
Without automated data extraction:
- Billing staff manually process insurance claims
- Sarah receives a paper bill weeks later, unsure of the breakdown
With automated data extraction:
- Insurance claims are automatically generated and submitted
- Sarah receives a digital invoice promptly, with a clear breakdown of charges
- Follow-up appointments are scheduled with automated reminders sent
The impact
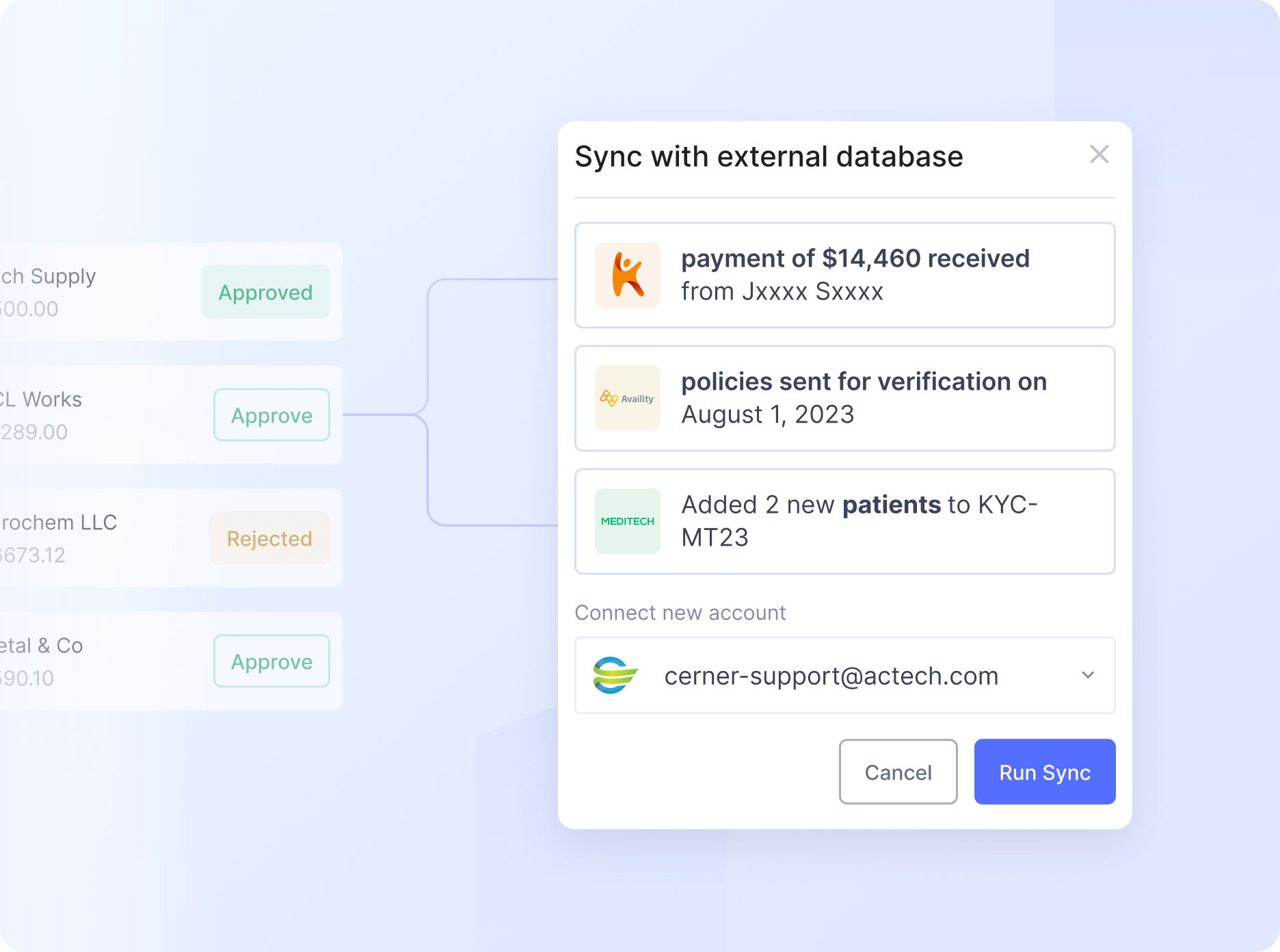
For patients like Sarah, healthcare data extraction reduces repetitive paperwork and lengthy wait times. Online scheduling, swift check-ins, and doctors who are instantly up-to-speed on her health history make each visit efficient and effective. Clear digital invoices and automated reminders also keep Sarah informed without the hassle. Insurance claims would be processed faster, reducing reimbursement delays.
For healthcare providers, it offers a range of benefits. Because of the seamless data flow between systems, admin staff can reduce manual data entry and tedious copy-pasting. Claim forms are automatically populated, reducing errors and speeding up reimbursement. It ensures more accurate resource allocation and staffing based on patient volume patterns and better inventory management of medical supplies and medications. Moreover, it facilitates enhanced compliance tracking and reporting for regulatory requirements and improved revenue cycle management with faster claim processing.
Doctors and nurses will have access to comprehensive patient histories and test results all in one place. They won't have to waste time deciphering handwritten notes or sifting through multiple systems. This streamlined access to information allows for better decision-making and patient care. Cash flow improves as billing becomes more efficient and accurate.
Overall, healthcare data extraction tools significantly enhance operational efficiency, reduce errors, and improve patient care.
Challenges in healthcare data extraction
Not all automation tools are created equal. Some may struggle with complex healthcare terminology or handwritten notes. Others may not integrate seamlessly with existing healthcare systems.
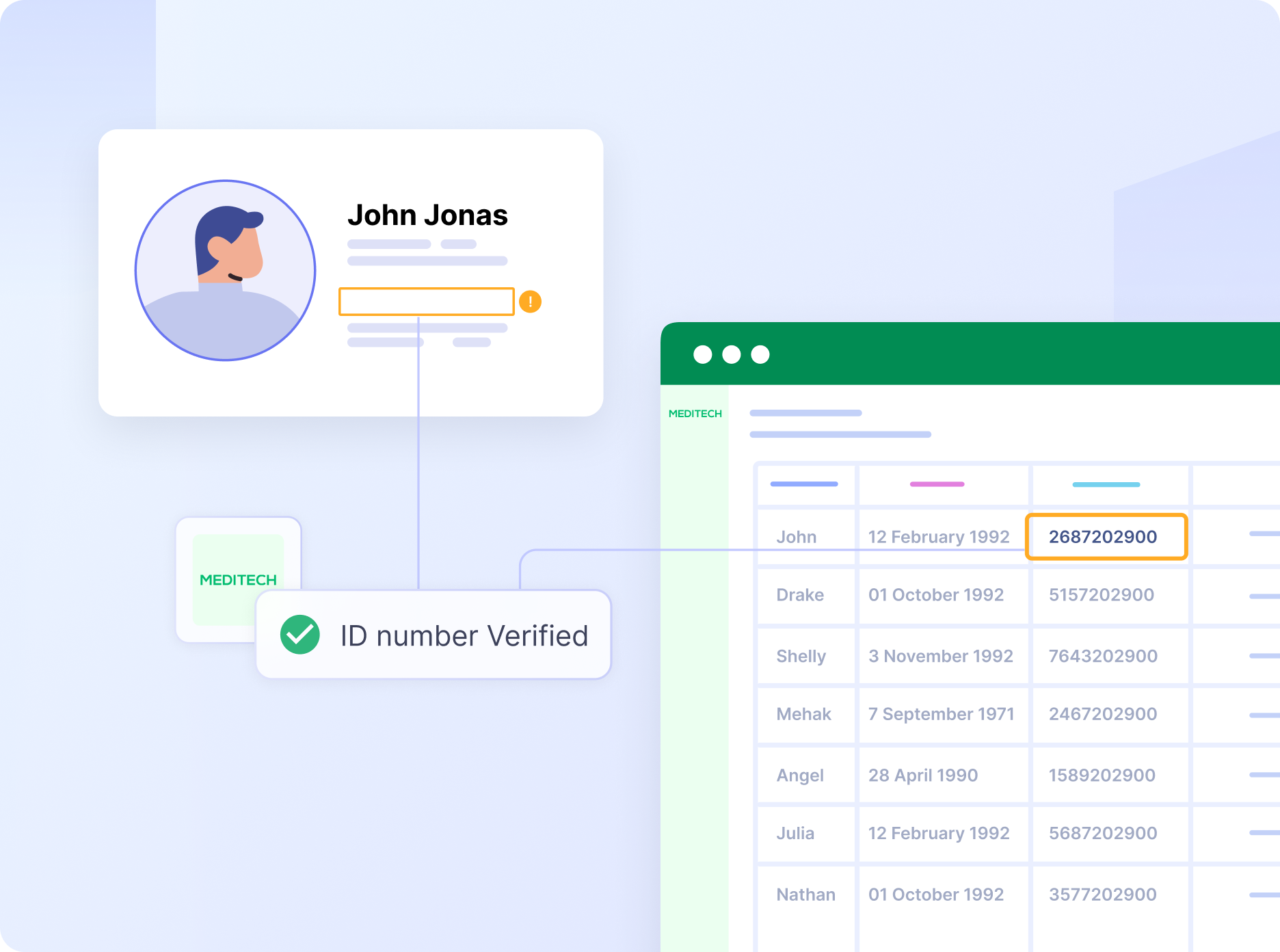
You need to consider these challenges when selecting a data extraction tool for healthcare:
1. Dealing with inconsistent data formats
Healthcare data comes in countless formats, from different EHR systems to various imaging standards, billing systems, and administrative platforms. Your extraction solution needs to make sense of it all. For instance, how do you ensure that a blood pressure reading from one system is interpreted the same way as in another? Or that billing codes are consistently applied across different departments? Your tool should be able to map diverse data formats to a common standard, ensuring consistency across the board.
2. Ensuring patient data privacy and security
HIPAA compliance aside, you must ensure that every step of the extraction process, from capture to storage, adheres to strict privacy standards. It is crucial to retaining your patients' trust and your organization's reputation. Healthcare organizations handle some of the most sensitive personal information, making security not just a compliance requirement but a fundamental operational necessity.
3. Integrating with existing healthcare systems
Your data extraction solution needs to work seamlessly with various EHR and EMR systems, laboratory information systems, billing platforms, scheduling software, and other critical healthcare software. This integration should allow for real-time data sharing and updates across platforms. This should help the healthcare providers and administrators get a complete picture of both patient care and organizational operations.
4. Handling unstructured data
Much of healthcare data is unstructured, including physician notes, patient narratives, administrative correspondence, and imaging reports. Even seemingly structured documents like patient registration forms often contain free-text fields and handwritten information that require sophisticated processing.
Your extraction tool must be capable of unstructured data extraction, parsing this information effectively, extracting relevant details, and organizing them in a structured format. This requires advanced natural language processing capabilities and machine learning algorithms to accurately interpret and categorize diverse healthcare terminology, different languages, and currencies.
5. Maintaining accuracy and quality control
Given the critical nature of healthcare data, even small errors can have significant consequences. Your extraction tool must have robust quality control measures in place. This includes validation checks, error detection algorithms, and having a human in the loop where necessary. Regular audits and continuous improvement processes are essential to ensure the tool's accuracy and reliability over time.
6. Navigating data ownership complexities
Healthcare data extraction is further complicated by complex data ownership questions. With competitive relationships between healthcare providers, insurance companies, and technology vendors, there are often limitations on what information can be extracted and shared. Many EHR vendors provide data access on a restricted "read-only" basis, limiting the extraction capabilities.
This fragmented approach to data ownership means that even with advanced extraction technology, organizations may only have access to partial patient information—creating incomplete datasets that limit the value of automated extraction efforts. Successful implementation requires careful navigation of these data governance challenges.
7. Managing regulatory compliance across jurisdictions
Healthcare organizations must navigate complex regulatory requirements that vary by location, specialty, and facility type. Your data extraction solution should help maintain compliance with regulations like HIPAA, GDPR, and regional healthcare data laws by properly handling protected health information, maintaining audit trails, and supporting required reporting.
Implement a comprehensive strategy to tackle these challenges head-on. Start by selecting a tool that can handle diverse formats and unstructured data, ensuring it integrates with your existing systems and prioritizes security. Set up quality control measures and regular audits to maintain accuracy. These steps lay the foundation for efficient data management.
Next, focus on your team and processes. Train your staff thoroughly on the new system and establish clear protocols for data handling. Continuously monitor and improve the extraction process, adapting to new challenges as they arise. This holistic approach ensures that your organization can effectively leverage data to improve patient care and streamline operations.
How to extract data from healthcare documents using Nanonets
Nanonets is an AI-based OCR software. A HIPAA-certified, GDPR and SOC-2-compliant platform perfect for healthcare document management. You can extract text from your healthcare documents, process data, sync data into different systems, process invoices, and more.
Here's how Nanonets can automate data extraction from healthcare documents.
1. Healthcare document collection
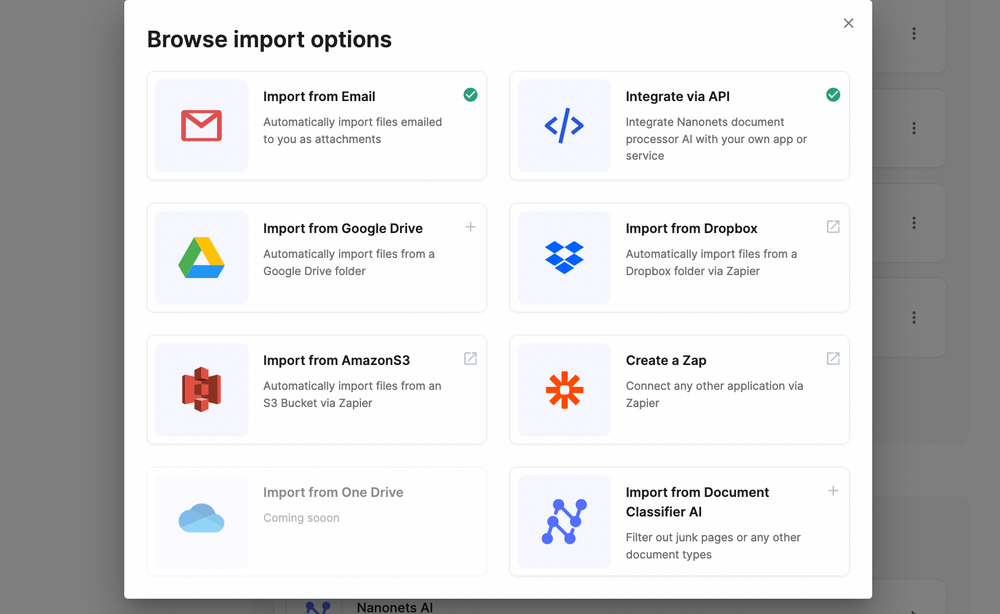
You can automatically collect documents from email, Drobox, Zapier, and more. This way, you'll automatically ingest healthcare documents into the system. You can also classify incoming documents using AI (e.g., clinical records, patient registration forms, administrative forms, billing documents, insurance claims, and regulatory filings).
2. Data extraction and processing

Utilize pre-trained OCR models for standard documents like invoices or ID cards, or create custom models for specialized healthcare forms in as little as 15 minutes. These models can process multi-page documents, lengthy tables, and various EHR/EMR formats as well as billing systems and administrative platforms with ease.
For patient registration forms, Nanonets offers significant advantages over traditional processing methods. While manual data entry of these forms is time-intensive and error-prone, and even EHR-based registration can struggle with inconsistent formatting, Nanonets can handle:
- Variable handwriting styles with high accuracy
- Different form layouts across facilities
- Mixed data types including checkboxes, multiple choice, and free text
- Integration with existing patient management systems
This means your front desk staff can focus on patient service rather than data entry, dramatically improving first-contact efficiency and reducing waiting times.
After data extraction, you can set up automated rules to perform data formatting, such as text capitalization, date formatting, and more. You can also set up database matching to verify extracted information against existing patient records, billing systems, or insurance databases.
3. Data validation and syncing
The validation workflow enables you to detect and flag duplicate documents to prevent issues like double billing. You can also create multi-stage review processes for critical documents, assigning different team members as needed.
For registration forms, this validation step is particularly valuable as it helps ensure data consistency across care settings. The system can automatically flag discrepancies between new registration information and existing patient records, reducing redundancy and preventing the need for patients to provide the same information multiple times across different departments.
Once data is extracted and approved, update it in your systems, such as ERP, CRM, billing platforms, or EHR. To do this, you can simply set up the relevant data export rules.
You can also download the structured outputs (CSV, JSON, XML) for further analysis or use webhooks or Zapier to push the data to other systems in real time.
4. Document archiving
Convert your healthcare documents into searchable PDFs and save them in a digital drive. You can then securely access the documents anytime by just searching for related keywords.
This archiving capability creates a secure, searchable repository of all patient registration information that complies with regulatory requirements. Unlike traditional filing systems where registration forms might be difficult to locate, Nanonets ensures this foundational patient data remains accessible while maintaining strict privacy controls.
Nanonets can be used to extract data from:
- Clinical records
- Health insurance plans
- Invoices
- Claims
- Patient Surveys
- Authorization Forms
- Doctor Letters
- Prescriptions
- ID Cards
- Regulatory compliance documents
- Administrative forms
- Staff credentialing records
- Quality assurance reports
- Operational documents
And more.
Are you solving any healthcare document processing issues? We would love to help you out. Schedule a call so our experts can understand your use case and create automated workflows for you.
Why Nanonets for your healthcare data extraction?
Nanonets is a highly flexible platform – we can tailor the solution to meet your specific needs. Contact us to discuss your unique requirements and explore how our AI-based document processing can streamline your healthcare operations.
Here's why Nanonets is a great choice for healthcare document automation:
- Eliminate manual data entry: Automate data extraction from any type of healthcare document (clinical records, administrative forms, invoices, insurance claims, compliance documents, and more), to reduce errors and improve efficiency.
- Enhance patient experience: Reduce wait times by streamlining patient onboarding, claims processing, and Medicare compliance checks.
- Expedite claims processing: Quickly verify and approve claims by automatically extracting and cross-referencing patient data from various sources.
- Ensure compliance: Maintain HIPAA, GDPR, and SOC2 compliance with secure data handling and processing.
- Flexible and customizable: Easily implement new features or customize processes to meet specific healthcare workflow needs.
- User-friendly interface: Intuitive drag-and-drop interface requires minimal training, even for non-technical staff.
- Comprehensive integration: Connect seamlessly with existing healthcare IT infrastructure through robust APIs and pre-built integrations.
- Multilingual support: Process documents in multiple languages, catering to diverse patient populations.
- Audit trail and version control: Maintain detailed logs for compliance and track document changes over time.
- End-to-end healthcare ecosystem support: Process documents across clinical, administrative, financial, and operational domains for complete healthcare data management.
- Scalable for any organization size: Whether you're a small clinic or a large hospital network, Nanonets scales to meet your document processing needs.
- Unparalleled image processing: Process healthcare documents that aren't perfect to start with—Nanonets can automatically deskew, reorient, rotate, and crop patient registration forms and other documents that arrive folded, skewed, or poorly scanned.
- Template-free recognition: Extract data without relying on predefined templates, allowing you to process registration forms from multiple facilities with varying formats without reconfiguration.
- Intelligent field detection: Automatically identify form fields like name, address, insurance ID, and signature blocks without manual setup, significantly reducing configuration time for new document types.
- Confidence scoring and continuous learning: Receive confidence scores for each extracted data element to focus human review where needed, while the system continually improves as it processes more of your organization's specific document types.
Final thoughts
Extracting data from healthcare documents and digitizing healthcare is the next obvious step to providing great healthcare experiences and low cost by reducing manual document processing costs. Using platforms like Nanonets, you can quickly extract data using OCR from patient registration forms, PDFs, and scanned documents and combine patient data for efficient healthcare outcomes.
Beyond clinical applications, healthcare data extraction streamlines administrative workflows, improves financial operations, and ensures regulatory compliance across your entire organization.
If you need custom workflows, you can schedule a call with our team to tell us your exact requirements.
FAQs
What is extraction eMR?
Pulling specific data from Electronic Medical Records. Example: Extracting all diabetic patients' A1C levels from the lab results section for the past year to identify those needing intervention.
What is the healthcare documentation process?
Recording patient information in EMRs or paper charts during care. Encompasses clinical documentation (diagnoses, treatment plans), administrative records (scheduling, staff management), and financial documentation (billing, claims processing) throughout the patient journey.
What is medical record processing?
Organizing patient data in healthcare systems. Involves scanning paper documents, inputting data into EMRs, coding diagnoses for billing, and ensuring record completeness and accuracy.
What is an extract in healthcare?
A subset of healthcare data pulled from a larger healthcare database or system for specific purposes such as analysis, reporting, or transfer.