

Most of us deal with PDF files regularly. And sometimes, we may have to extract specific pages from large PDFs — an expense claim, an email attachment, a page from an academic paper, a table from a lengthy contract, or even a recipe from a large cookbook.
It can be a pain to manually extract one page or a few pages from a PDF. Methods like copying-and-pasting or printing and scanning are tedious, time-consuming, and can result in loss of quality.
This article lists several methods to extract pages from a PDF document. We'll guide you through each technique step-by-step so you can choose the one that's right for you or even combine them for maximum efficiency.
 →
→

Extract Pages from PDFs with Our Free PDF Splitter!
Manually extracting pages from PDFs can be time-consuming and frustrating. Nanonets' AI-powered tool simplifies the process, allowing you to separate PDF pages with just a few clicks. Make tedious PDF editing a thing of the past now.
Overview of PDF page extraction methods
| Method | Description | Advantages | Disadvantages |
|---|---|---|---|
| Manual Extraction | Use a PDF reader's print function to print desired pages to a new PDF. | No additional software required. | Time-consuming for large documents. |
| AI-powered OCR Tools | Use AI-driven tools like Nanonets to extract data based on content. | Highly efficient and accurate. | Free version available, but subscription required for full features. |
| Adobe Acrobat | Use Adobe Acrobat's 'Organize Pages' feature to extract pages. | Professional tools and features. | Paid software, not free. |
| Online PDF Splitters | Use online services to split PDF files and extract pages. | Convenient and no installation required. | Privacy concerns with sensitive data. |
| Open-source PDF Tools | Use open-source software like PDFtk to extract pages locally. | Free and secure local processing. | Can be less user-friendly, steep learning curve. |
Why do we need to extract pages from PDFs?
PDF is widely used because it is portable, offers security, and preserves formatting. However, a large PDF can be cumbersome, especially when you only need certain pages. You may have to extract individual pages from a PDF for reasons like:
- Sharing specific parts of a document
- Removing confidential information
- Sending only relevant information to conserve space and time
- Creating a new document from parts of an existing one
- Extracting only the summary or brief of a comprehensive report
No matter your reason, extracting pages from a PDF can make your work significantly more straightforward. Now, let's dive into the different methods to extract pages from a PDF.
Want a custom OCR model to ramp up manual data extraction processes and increase efficiency? If yes, Click below to Schedule a Free Demo with Nanonets' Automation Experts
1. Extract pages from a PDF manually
This is the most straightforward method for extracting a page from a PDF. You don’t need to download or install any software. Most PDF readers, like Adobe Acrobat, have a print function that allows you to select the pages you want and print them to a new PDF file.
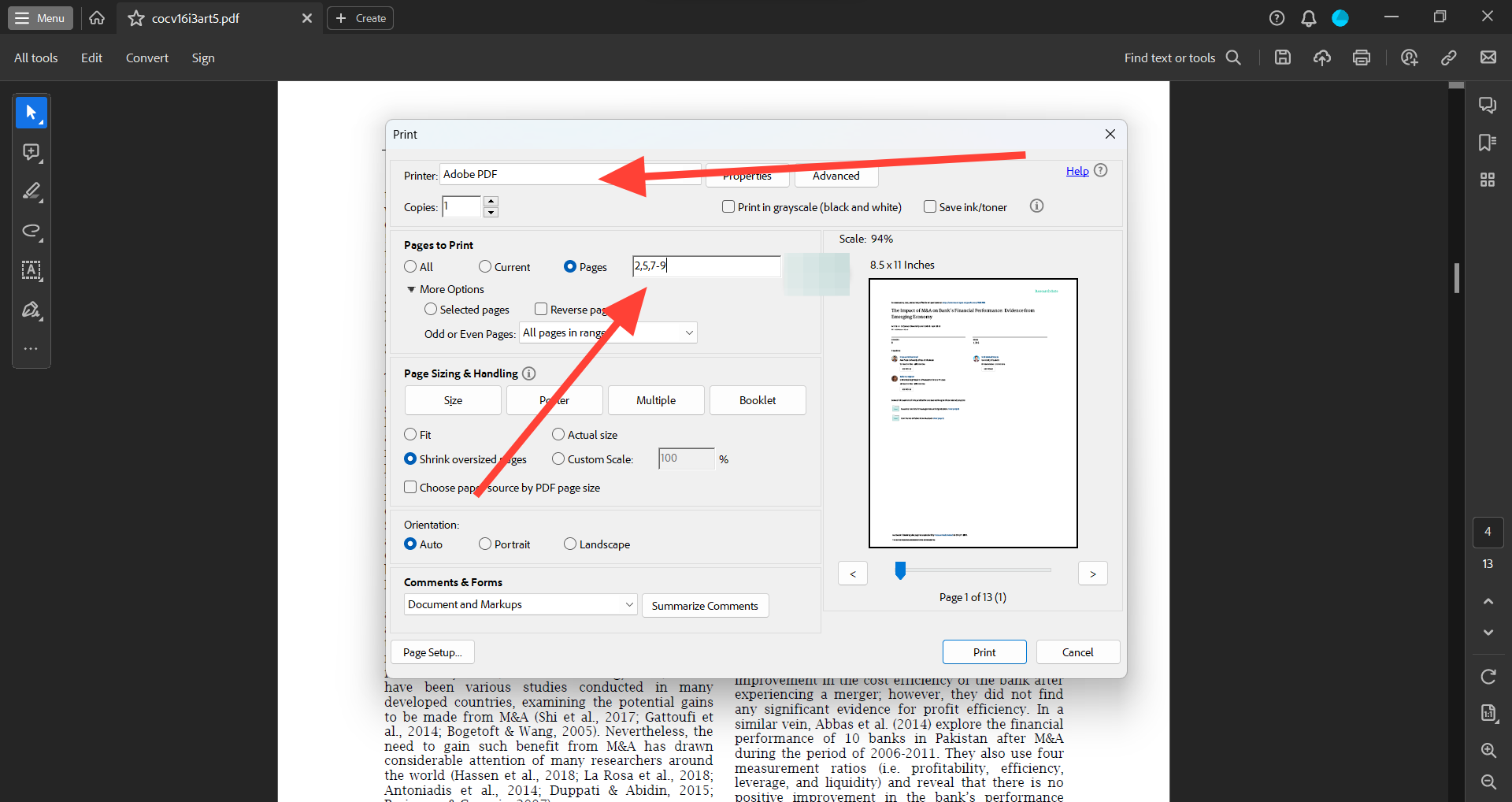
Let’s look at how to extract a page from a PDF using Adobe Reader:
- Open the PDF file from which you wish to extract pages.
- Click on ‘Menu’.
- Choose the 'Print' option.
- Specify the pages you want to extract in the field next to 'Pages to Print'.
- Set the ‘Printer’ as 'Adobe PDF'.
- Click 'Print'.
- Choose the location where you want to save the extracted pages and rename the new PDF file.
- Click 'Save'.
This will create a new PDF file containing the pages you specified. You can enter individual pages, page ranges, and a combination of both (should be separated by commas).
While this method is simple and doesn't require special tools, it has a few drawbacks. Misaligned page numbers could lead to wrong pages being extracted. Bulk processing may be complicated because you must manually enter each page number.
There's no option to rearrange the pages post-extraction. The output remains a PDF, so you cannot choose a different output format.
Note: This method will not work if the PDF is password-protected or printing is disabled.

Automate data extraction from PDFs!
Extracting PDF pages manually is a time-sink. Nanonets' AI-powered OCR tool can automatically extract text and tables from your PDFs, saving you time and effort. It's fast, secure, accurate, and easy to use.
2. Automate data extraction with an AI-powered OCR tool
Most PDF page extraction methods work great when information extraction is based on page numbers. But what if you need to extract pages based on the page's content?

For instance, traditional methods can be time-consuming and prone to errors if you want to extract and process all the invoices with a value of over $500 or all the pages with a specific name or term.
This is where an AI-powered OCR (Optical Character Recognition) tool like Nanonets can be a game-changer. Nanonets offers a comprehensive solution for extracting pages and data from PDFs, making the process more efficient, accurate, and streamlined.
Nanonets' free online PDF splitter
For those looking for a quick and easy way to extract pages from PDFs, Nanonets offers a free online PDF splitter tool. It lets you easily extract pages from a PDF in just a few clicks:
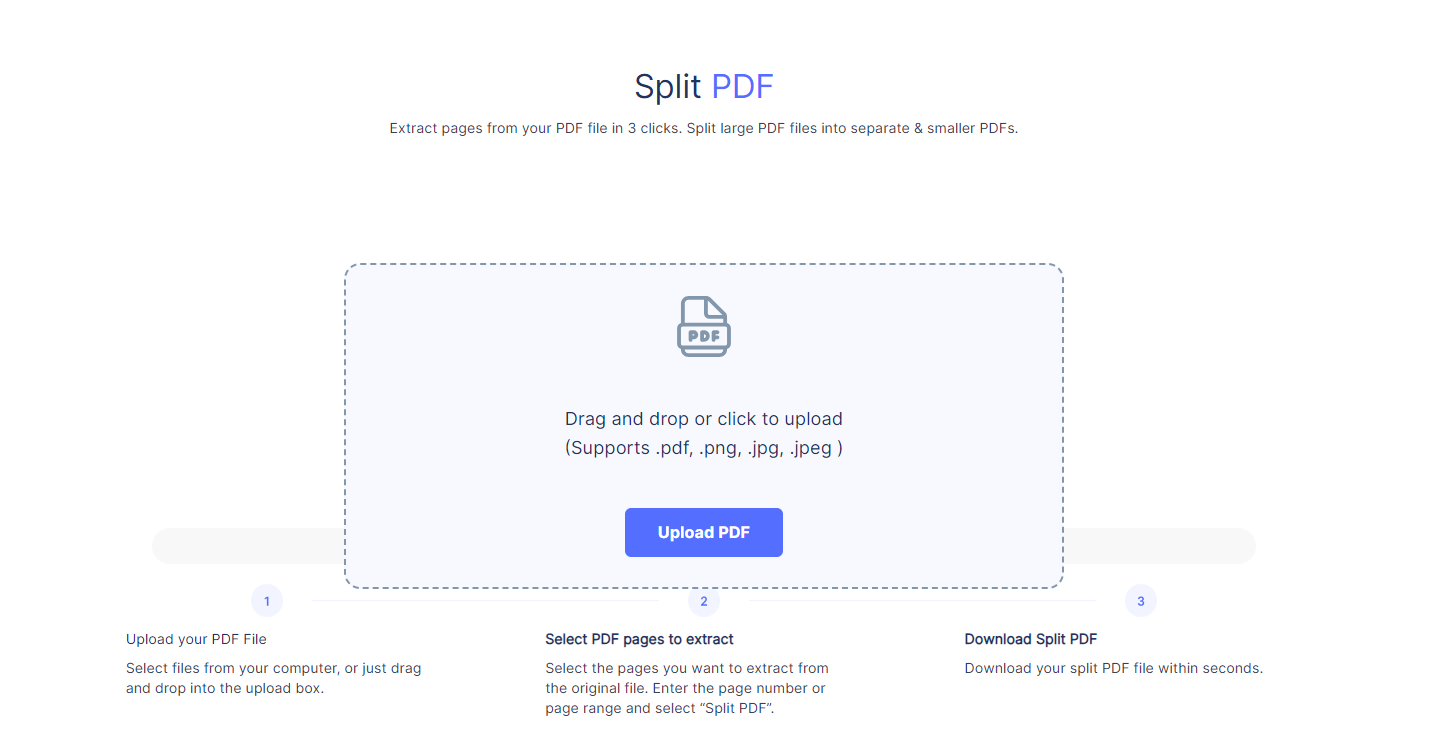
- Go to the Nanonets PDF Splitter page.
- Upload your PDF file by clicking the 'Upload PDF' button or dragging and dropping the file.
- Select the pages to extract by entering page numbers or specifying a range (e.g., 1,3,5 or 2-5).
- Click the 'Split PDF' button to process your request.
- On the download page, click the 'Download Split PDF' button.
- Choose a location on your computer and click 'Save' to store the new PDF file.
Advanced data extraction with Nanonets AI document processing
Beyond simple page extraction, Nanonets harnesses the power of machine learning and natural language processing to automatically extract specific data from multiple pages of a PDF at once. This means you can easily extract and process invoices, forms, receipts, or any other documents based on their content rather than just page numbers.
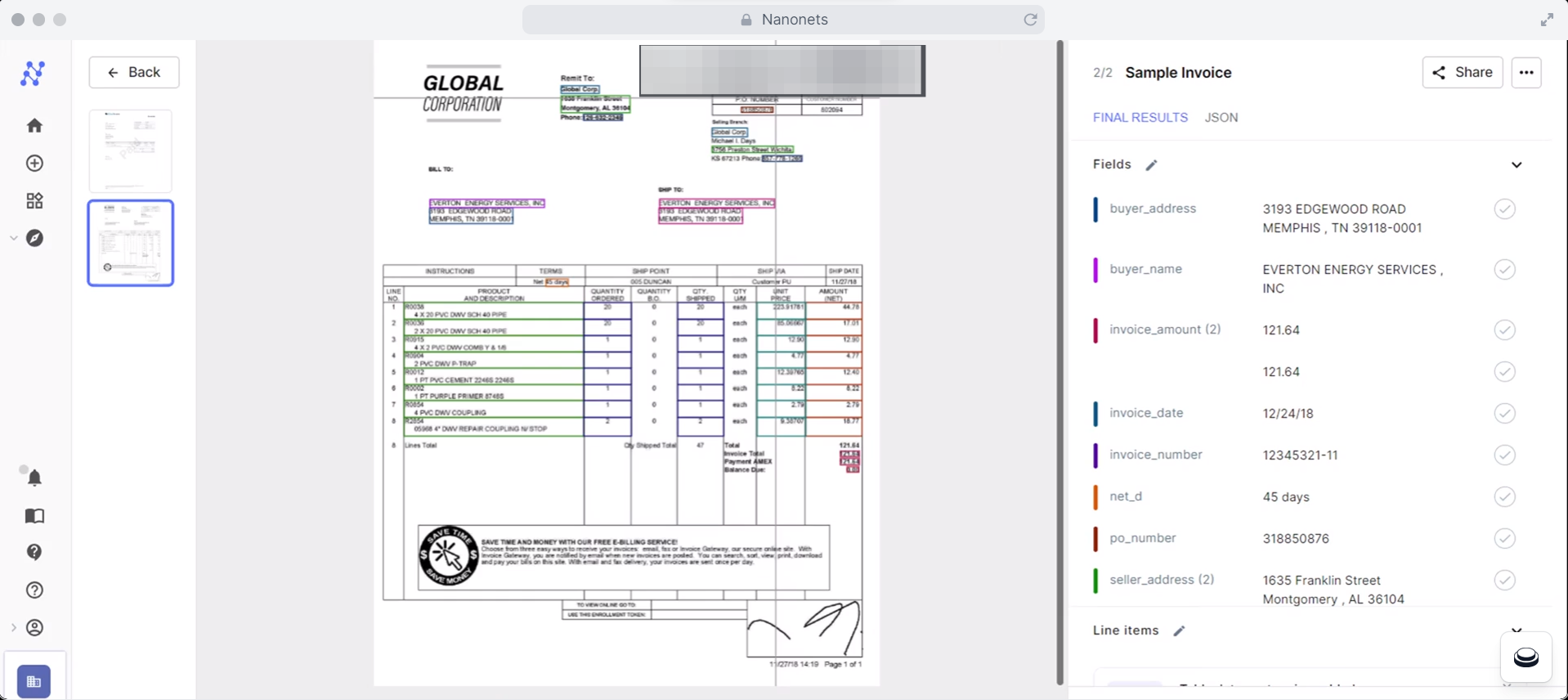
Nanonets can seamlessly handle scanned PDFs as well. The software automatically detects and extracts text, images, and other elements from scanned documents, making selecting and extracting specific pages easier. Once the scanned PDF has been processed with OCR, you can use any methods discussed in this article to extract the desired pages.
Here's a general guide to automate the extraction of data from PDFs using Nanonets:
- Sign up for a free account on Nanonets.
- Upload your PDF files.
- Configure the AI model by selecting the data fields you want to extract.
- Train the model by providing some examples.
- Once the model is trained, extract your desired data from the uploaded PDF.
- Download the extracted data in your preferred format (CSV, JSON, etc.).
Upload any number of PDFs and let Nanonets do the heavy lifting for you. The tool can process multiple files simultaneously, saving you considerable time and effort.
Finding it difficult to process PDFs in different languages?
See how Nanonets' advanced OCR technology enables you to extract data from PDFs in over 100 languages. Streamline your global document processing workflow and save time. Join us for a live demo to see how Nanonets can help you efficiently handle multilingual PDFs.
Nanonets combines advanced OCR and AI technology to recognize text, numbers, and other data in your receipts, invoices, claim documents, form entries, bank statements, purchase orders, customer orders, user complaints, export forms, and other documents. It can also make PDFs searchable and process complex documents with multiple layouts, languages, and structures.

This enables the tool to handle structured and unstructured documents and accurately extract only the information you need. Moreover, it learns from your intervention and improves over time.
What’s more, Nanonets comes with pre-built, low-code automation workflows. You can automate the entire process from extraction, verification, and validation to creating audit trails, processing payments, or any other operation. This allows you to process documents faster, reduce manual errors, and save valuable time.

Trigger automated workflows based on PDFs received in Gmail.
▼
Trigger automated workflows based on PDFs received in Gmail.
- Automatically extract text from new email attachments and files in Google Drive
- Process Gmail attachments and add extracted data to Google Sheets
- Sync extracted data from Salesforce or QuickBooks Online to Airtable
Nanonets integrates seamlessly with your existing systems, such as ERP, CRM, and accounting software. Whether you use Xero, QuickBooks, Salesforce, Airtable, Zapier, or any other application, you can directly feed the extracted data into these systems with minimal manual intervention.
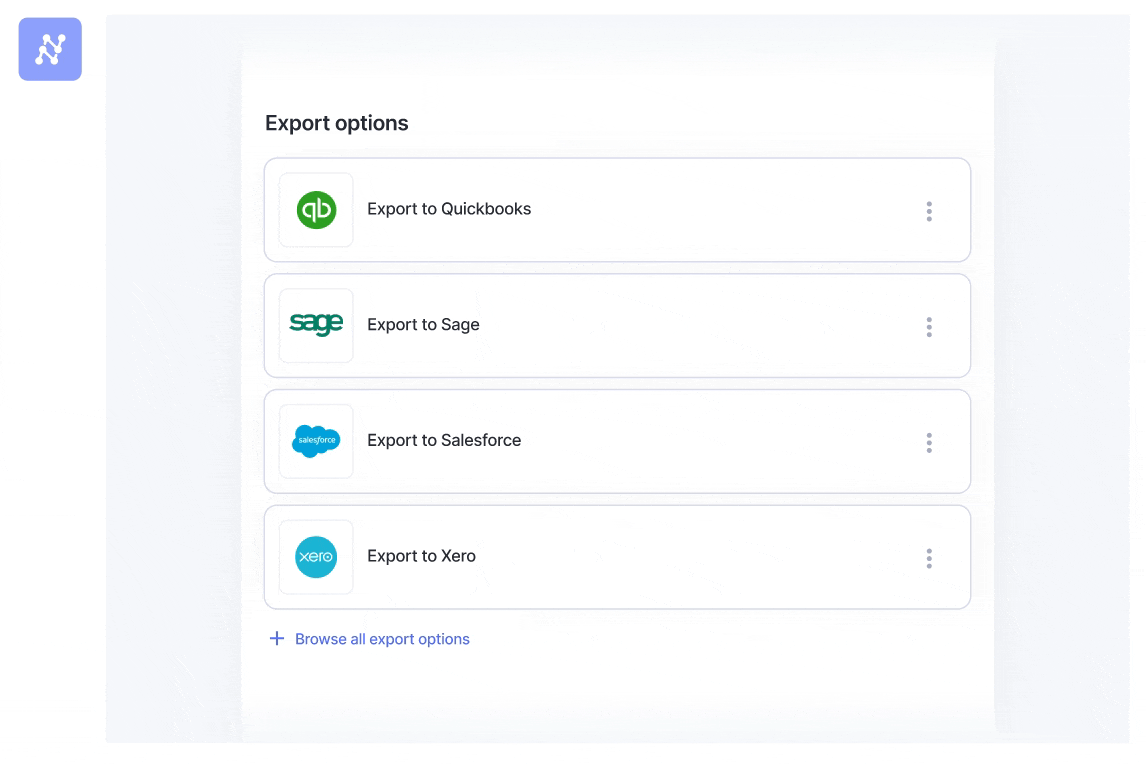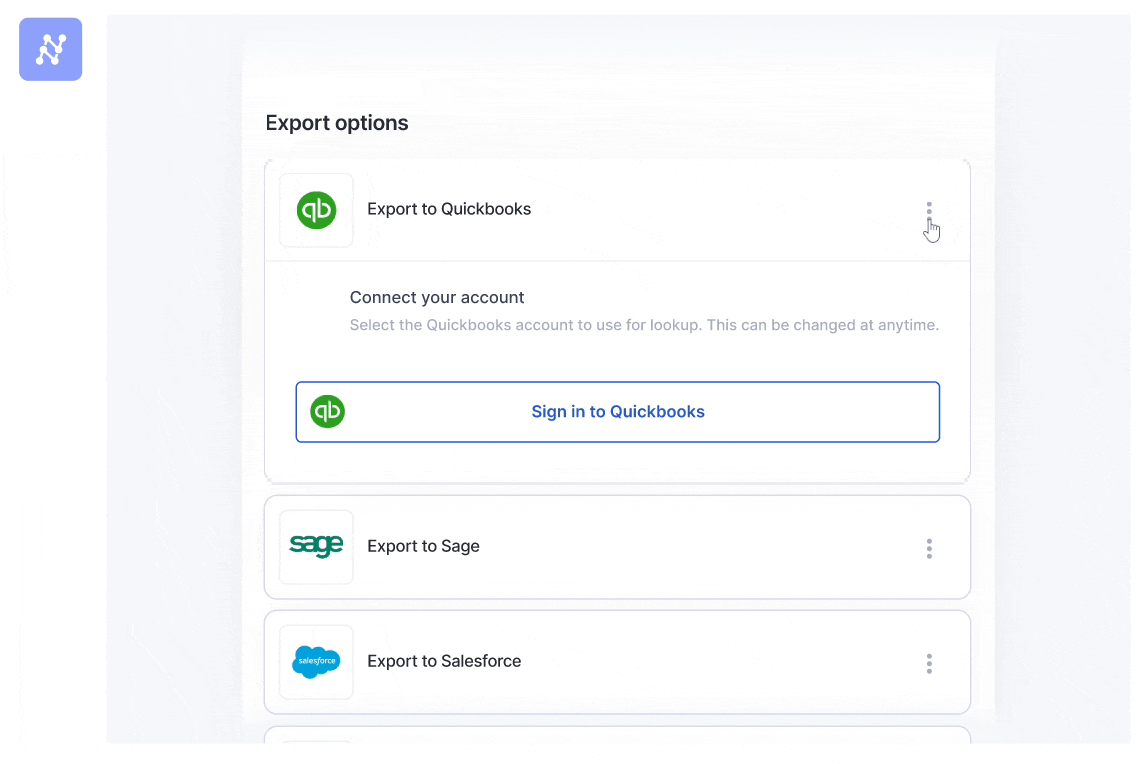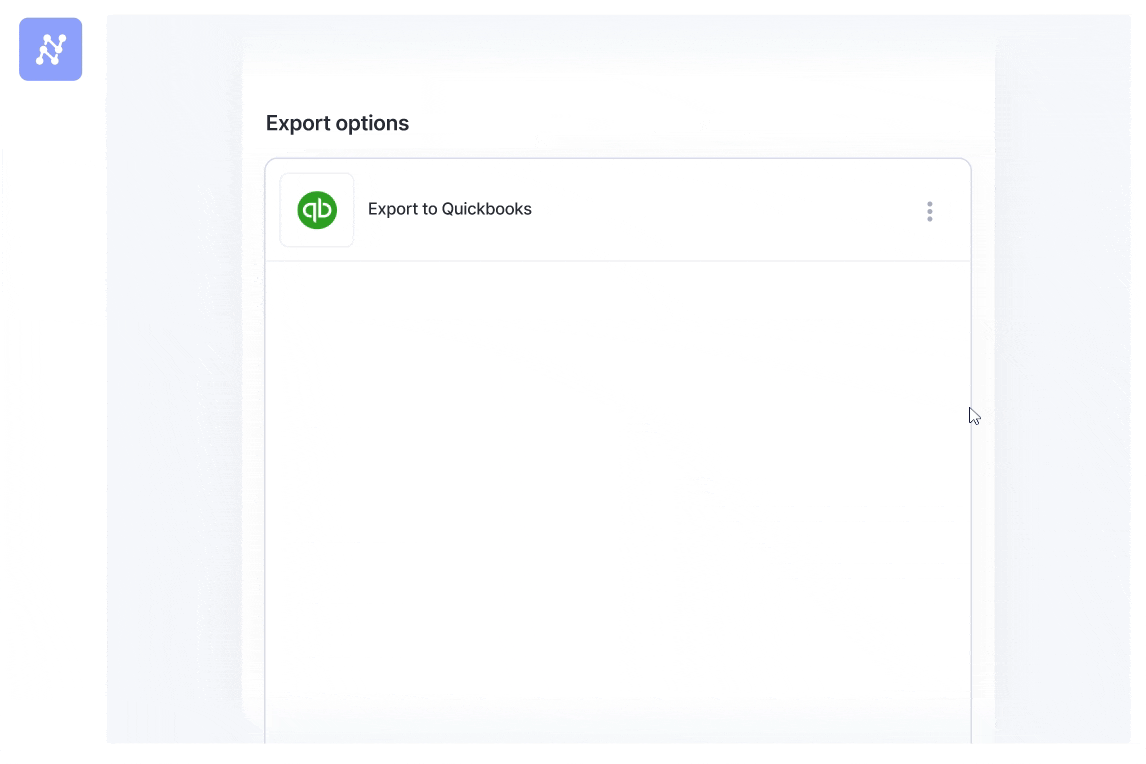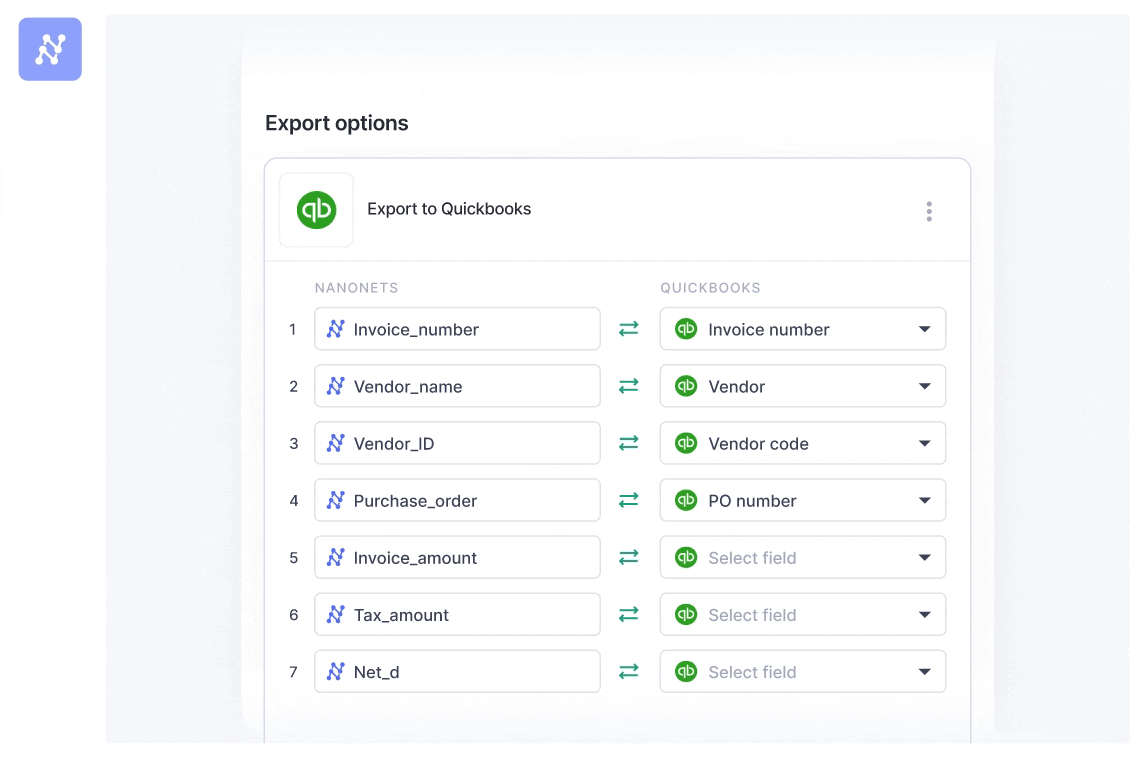
It also supports document storage services like Google Drive, Dropbox, and SharePoint, allowing you to access and manage your documents easily.
Data security should be a top priority when using any PDF extraction tools. Nanonets ensures this with encryption to safeguard your data and process it securely. GDPR, SOC 2, and HIPAA compliance also ensure your data remains private and protected.
Want a custom OCR model to ramp up manual data extraction processes and increase efficiency? If yes, Click below to Schedule a Free Demo with Nanonets' Automation Experts
3. Extract pages from PDFs using Adobe Acrobat
Now, if you’d like to extract pages from a PDF on a more professional scale, you might want to try Adobe’s Acrobat Pro. This software is not free but offers a 7-day free trial.
The Acrobat Pro plan starts at $19.99/month and includes a suite of features that can help you optimize your document-handling process.
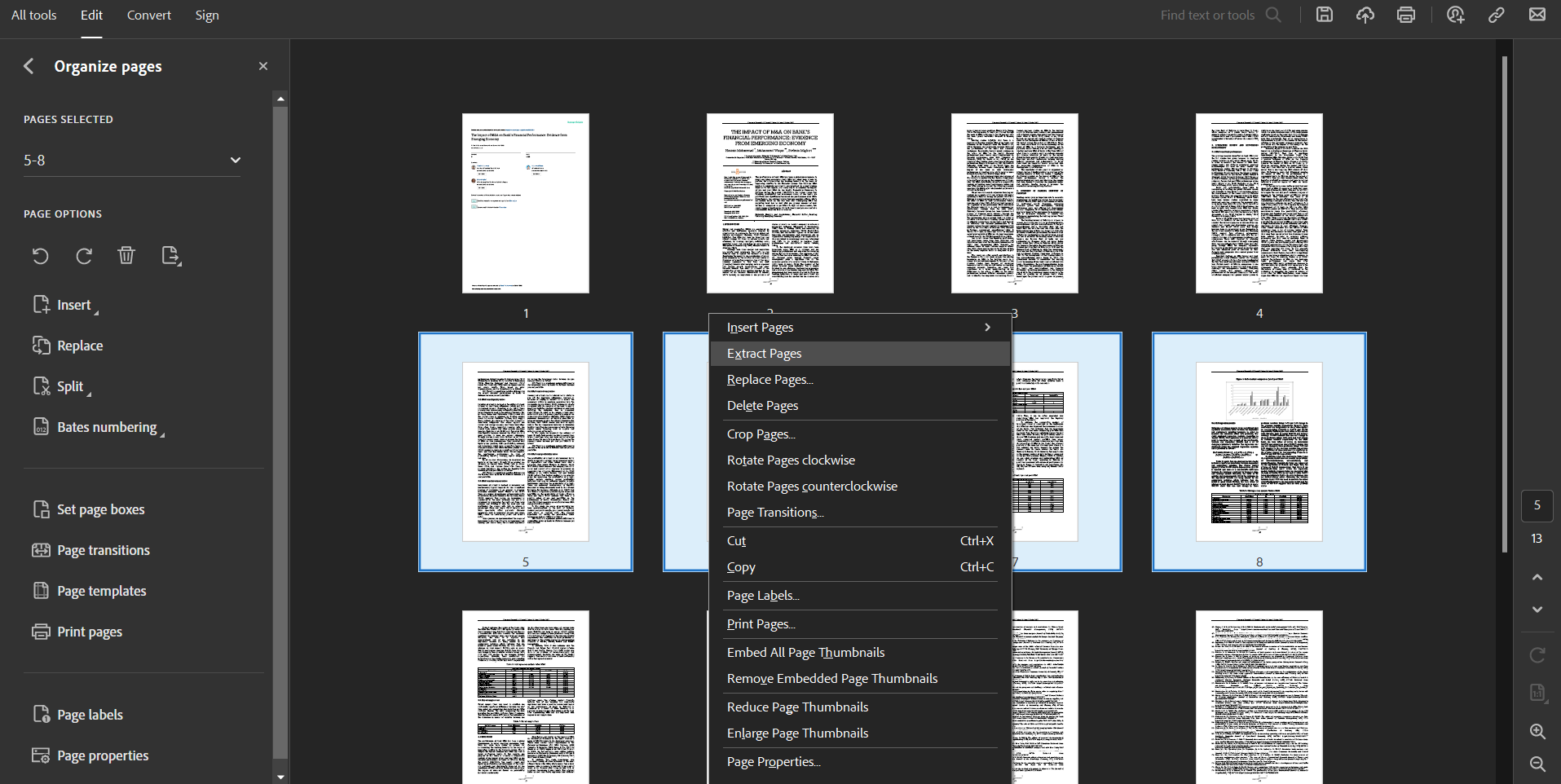
Here is how you can extract pages using Adobe Acrobat:
- Open the PDF file you want to extract pages from in Adobe Acrobat.
- Click on the ‘Edit’ menu
- Choose 'Organize Pages'
- Press Control (on Windows) or Command (on Mac) and click on the pages you want to extract
- Right-click on the selected pages
- Choose 'Extract Pages'
- In the new dialog box, check 'Extract Pages As Separate Files' if you want each page as a separate PDF
- Choose the location where you want to save the extracted pages
- Click 'Extract'
This method works well because it retains all interactive components of the PDF, such as hyperlinks, comments, and forms. It also allows you to extract as many pages as you want and save them as separate files or even split the PDF into multiple PDFs.
However, after the trial period, you have to buy the software, and it can be pretty expensive if you only need it for simple tasks. It also does not provide an option to convert the extracted pages into other file formats besides PDF.

Simplify PDF data extraction with Nanonets' intuitive tools!
Go beyond basic OCR and opt for a user-friendly, affordable alternative that makes it easy to extract data from PDFs. Discover a smarter way to work with PDFs and boost your productivity. Ensure your PDF data seamlessly integrates with your ERP, CRM, and accounting software.
4. Use online splitters for separating PDF pages
Online PDF splitters work great for separating specific pages from a PDF. You don't have to install any software. Just head over to the website, upload the PDF, enter the page numbers, and voila.
The key here is to select the right one that is secure, easy to use, and offers the features you need.
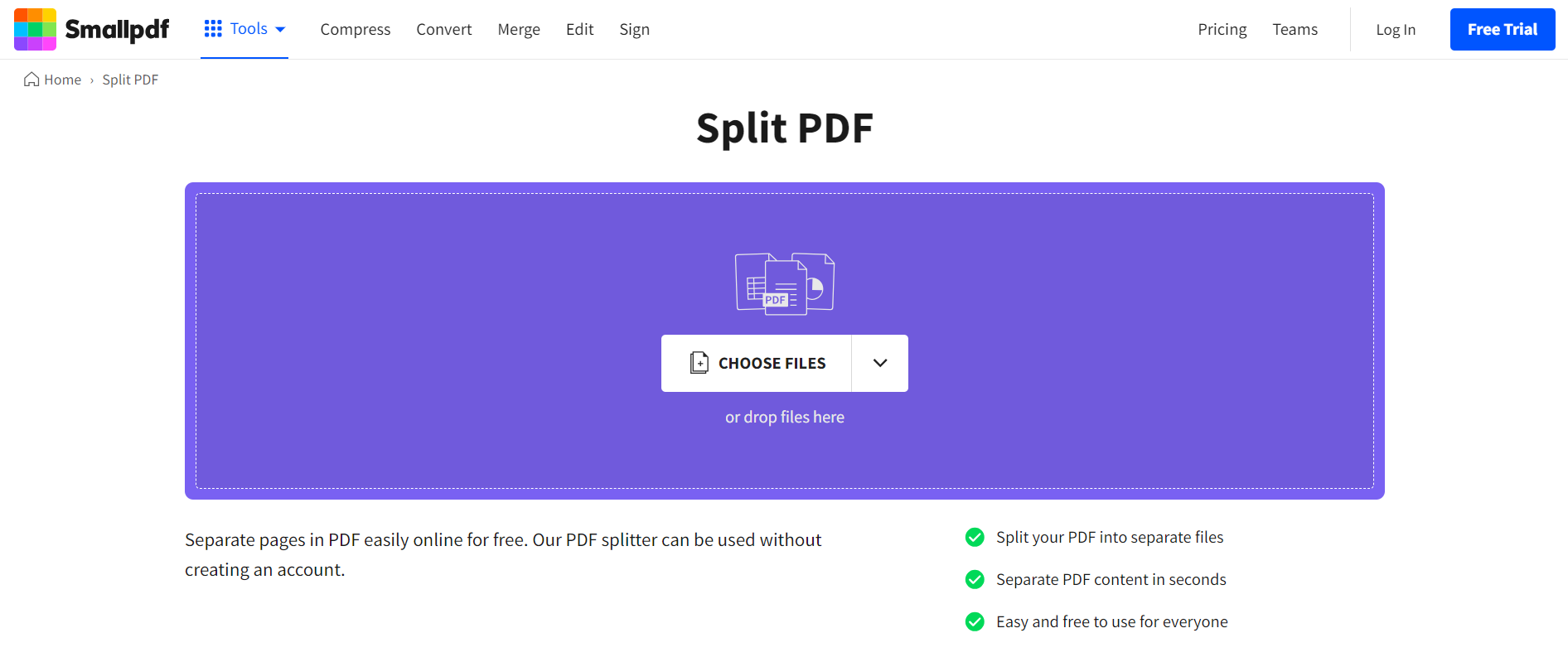
Some of the popular online PDF splitter tools include:
Here's a general guide on how to use these online PDF splitters to extract a page from a PDF:
- Go to the website of the online tool you have chosen
- Click on 'Select PDF file' or a similar option to upload your PDF
- Once the PDF is uploaded, select the pages you want to extract
- Click 'Extract pages' or a similar option
- Download the new PDF file with the extracted pages
These online tools are simple to use, and most are free. Many of these tools come with additional features, such as merging PDFs, converting between different file formats, compressing PDFs, and more. But be prepared to explore a bit, as each component usually has its page or tab.
One major downside of online tools is the risk of uploading confidential or sensitive documents to a third-party server. If the website's security is compromised, your file could end up in the wrong hands. So, if you're handling confidential data, quickly check the website's privacy policy.
Speed can be another hiccup. Server or network congestion can slow things down, especially with large files. While many online PDF splitters offer free services to extract pages from a PDF, some may have limitations on the number of pages or the size of the file you can process. They may also bombard you with ads or nudge you to upgrade for speedier processing. Take SmallPDF, for example; you can't rename your extracted file without paying up.
The quality of your output can also vary depending on the tool, and there might be a cap on how many pages you can extract in one go.

Extract pages securely with our free PDF splitter.
Uploading sensitive PDFs to online splitters can put your data at risk. Nanonets provides a secure, GDPR-compliant platform for extracting pages and data from PDFs. You can keep your business data safe and confidently automate document processing workflows.
5. Use an open-source PDF extraction software
Another way to extract pages from a PDF without Acrobat is using open-source software. These tools provide robust features for splitting, merging, and extracting pages, making them ideal for processing confidential documents or handling large volumes of files.
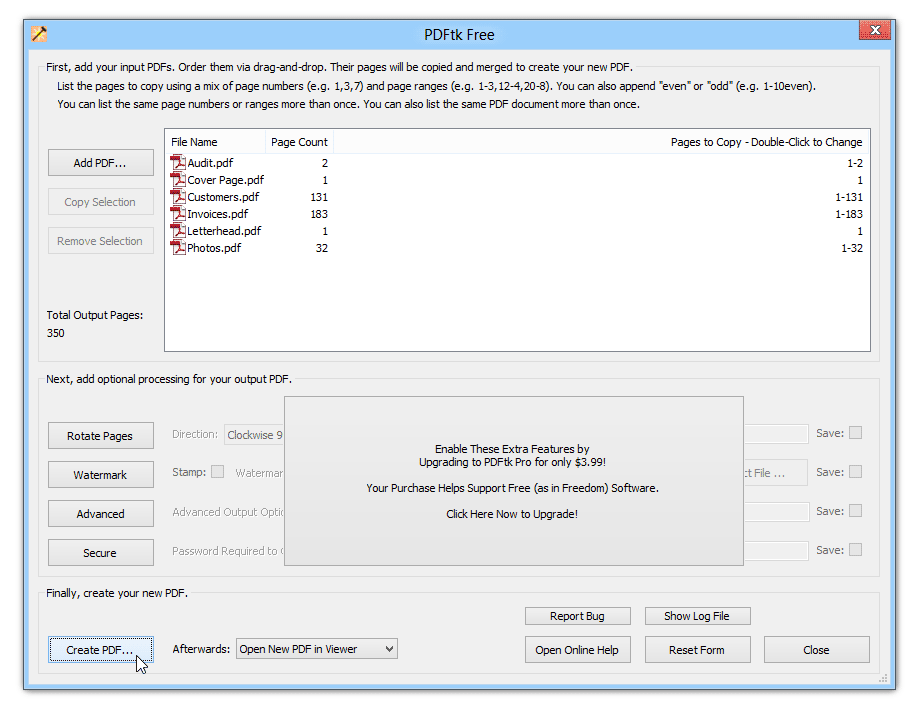
As open-source software runs locally on your machine, it eliminates the security risks associated with online tools while providing greater flexibility and customization options for managing your PDF files.
Some open-source PDF extraction tools include:
Here's a general guide to extracting pages using open-source software:
- Download and install the open-source software of your choice
- Open the software and load your PDF file
- Choose the 'Extract' or 'Split' function (the exact wording will depend on the software)
- Specify the pages you want to extract
- Click 'Extract' or 'Split'
- Choose the location where you want to save the extracted pages
- Click 'Save' or 'OK'
With these tools, you can extract, merge, rotate, and perform many other operations on your PDF files. They also usually support batch processing so that you can extract pages from multiple PDFs simultaneously.
These tools allow you to extract pages from a PDF and save them as separate files. Using the command-line interface, you can specify the input PDF, the pages you want to extract, and the output format for each extracted page. This method is beneficial for automating the process of extracting pages as separate files for a large number of PDFs.
One potential drawback of open-source software is that it might not be as user-friendly as online tools or commercial software. You might need to read the documentation, deal with command-line interfaces, and handle occasional bugs.
Also, while these tools can handle most PDF tasks, they may not support advanced features like interactive elements, annotations, or encryption. Some may also lack a graphical user interface, making them more challenging for non-technical users to navigate.

Want a less complicated yet powerful OCR tool?
Open-source PDF extraction tools can be complex and time-consuming. Switch to a user-friendly AI-powered OCR platform that makes PDF table extraction effortless – no coding needed. Get accurate data from even the most complex PDFs and automate your workflow in minutes.
6. Alternative methods to extract pages from PDFs
In addition to the primary methods discussed earlier, there are several other ways to extract pages from PDFs, depending on your device, browser, or operating system.
a. Using your web browser
Most modern web browsers, such as Google Chrome, Mozilla Firefox, and Microsoft Edge, have built-in PDF viewers that allow you to print specific pages to a new PDF file. Here's how:
- Open the PDF file in your browser.
- Click the 'Print' button or use the keyboard shortcut (Ctrl+P on Windows or Cmd+P on Mac).
- Select the pages you want to extract in the print dialog under the 'Pages' section.
- Choose 'Save as PDF' as the destination.
- Click 'Save' and choose a location for your new PDF file containing the extracted pages.
b. Extracting pages on different operating systems
1. Windows
On Windows, you can use the built-in Microsoft Print to PDF feature to extract pages from a PDF:
- Open the PDF file using MS Word or your preferred PDF viewer.
- Go to 'File' > 'Print' or use the Ctrl+P keyboard shortcut.
- Select 'Microsoft Print to PDF' as the printer.
- Under 'Pages,' choose the pages you want to extract.
- Click 'Print' and choose a location to save the new PDF file.
2. macOS
On macOS, you can use the built-in Preview app to extract pages from a PDF:
- Open the PDF file in Preview.
- Minimize the window.
- Go to 'View' > 'Thumbnails' to display page thumbnails.
- Select the thumbnails of the pages you want to extract. Press down the Command key if you want to extract multiple pages.
- Drag the selected thumbnails out of the window to the desktop or a folder of your liking.
3. Linux
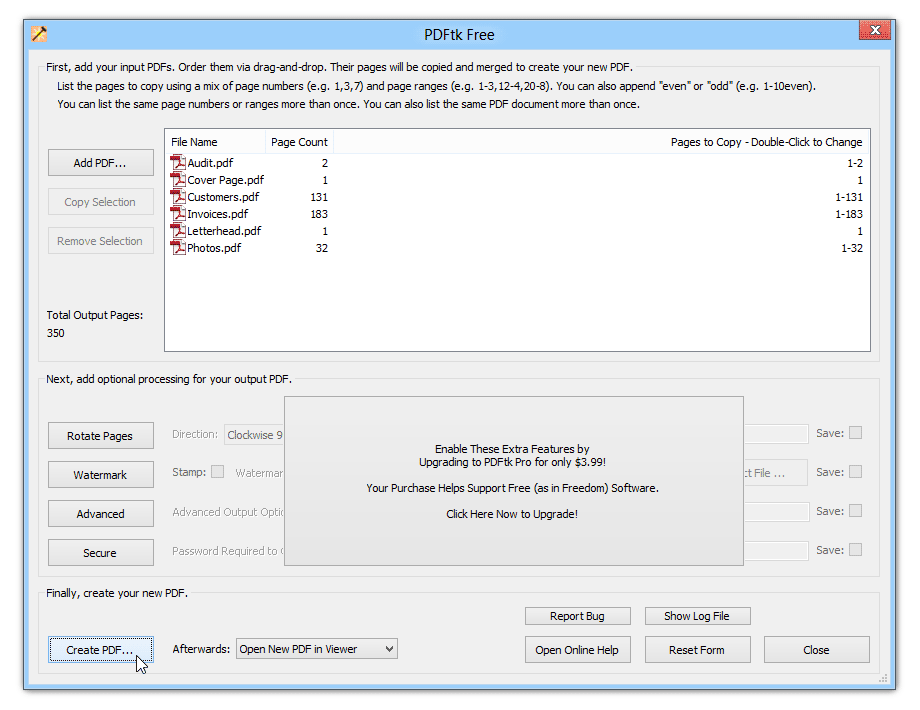
On Linux distributions, you can use different packages, such as QPDF, pdfly, or PDFtk, to extract pages from a PDF file.
If you are using PDFly, you can follow these steps:
- Install pdfly using pip: pip install -U pdfly.
- To extract specific pages from a PDF, use the cat command followed by the input file, the --pages option, and the output file: ppdfcat input.pdf --pages 1-3 output.pdf.
- This command extracts pages 1 to 3 from input.pdf and saves them as output.pdf.
- You can also extract non-consecutive pages by separating the page numbers with commas: pdfly cat input.pdf --pages 1,3,5 output.pdf.
- This command extracts pages 1, 3, and 5 from input.pdf and saves them as output.pdf.
c. Extracting pages on mobile devices
1. iOS
On iOS devices, you can use the built-in Files app to extract pages from a PDF:
- Open the PDF file in the Files app.
- Tap the 'Share' icon (square with an upward arrow).
- Scroll down and select 'Print.'
- Use the page range selector in the print preview to choose the pages you want to extract.
- Tap on 'Share' and choose a location to save the new PDF file containing the extracted pages.
2. Android
The process may vary on Android mobile devices depending on the PDF viewer app you're using. However, most PDF viewer apps, such as Adobe Acrobat Reader, have a 'Print' option to save specific pages as a new PDF file.
While these methods are straightforward and convenient, they may not be great for bulk processing or complex extraction requirements. Tools like Nanonets or other specialized software may be more suitable for context-based extraction or advanced features like OCR.
Wrapping up
There you have it — so many different ways to extract pages from a PDF. Hopefully, this guide has given you a clearer idea of how to approach your PDF extraction tasks.
Always evaluate the complexity of your documents, the time and effort you can afford to spend, and the accuracy required before choosing a method. The right tool can be a real game-changer. It can save you hours of manual work, prevent errors, streamline your workflow, and help you focus on more critical tasks.

Learn more about AI-powered PDF extraction.
See how Nanonets can help you effortlessly scale your PDF data extraction processes and handle growing volumes with ease. Schedule a demo with our experts to learn how our AI-powered platform can automate your PDF workflows, saving you time and resources.
Frequently asked questions
How can I separate specific pages from a PDF?
- Upload the PDF to Nanonets' Free Online PDF Splitter
- Enter the pages you want to separate
- Separate them with a comma if more than one
- Click on 'Split PDF'
- Download your new PDF(s)
Can I use AI for data extraction from PDFs?
Yes, AI-based tools like Nanonets offer a robust solution for data extraction from PDFs. These tools remove pages from a PDF and convert and organize the extracted data in a structured format. They can integrate with your existing systems like ERP, CRM, and accounting software, feeding the extracted data directly into these systems. They also support document storage services like Google Drive, Dropbox, and SharePoint and comply with data privacy regulations like GDPR and CCPA.
Can I extract pages from a PDF using C#?
Yes, C# users can extract pages from a PDF using libraries like iTextSharp or PdfSharp. These libraries provide comprehensive tools for creating, manipulating, and extracting content from PDF files within a C# application.
To extract pages from a PDF using C#, you'll need to add a PDF library like iTextSharp to your project. Then, you can use the library's classes and methods to load the PDF document, specify the pages you want to extract and save the extracted pages as a new PDF file. This approach is handy for integrating PDF page extraction functionality into a more extensive C# application or automating the extraction process for multiple PDFs.
How can I extract pages from a PDF using Python?
In Python, you can extract pages from a PDF using libraries like PyPDF2 or PDFminer. These libraries provide functions and classes that allow you to read, write, and manipulate PDF files programmatically, enabling you to automate the process of extracting pages from PDFs.
You'll first need to install a PDF library like PyPDF2 to extract pages from a PDF using Python. Once installed, you can use the library's functions to open the PDF file, specify the pages you want to extract and save the extracted pages as a new PDF document. This method is handy for automating the extraction process for large numbers of PDFs or integrating PDF page extraction into a larger Python project.
Is it possible to extract pages from a secured or password-protected PDF?
It is possible to extract pages from a secured or password-protected PDF, but it can be more challenging than working with a standard PDF. To extract pages from a secured PDF, you'll first need to remove the password or encryption using a tool like Smallpdf or Adobe Acrobat. Once the security is removed, you can extract the desired pages using any methods discussed in this article.
Some online PDF splitters, such as ILovePDF, can extract pages from secured PDFs directly. These tools prompt you to enter the password for the encrypted PDF and then allow you to select the pages you want to extract. However, it's crucial to ensure that you trust the online tool with your sensitive data before uploading a secured PDF.


{kind=link}