
For any business dealing with a high volume of documents, the process of manually extracting key information is a significant operational bottleneck. More so in sectors like finance, healthcare, and logistics, where speed and accuracy are critical. Zonal Optical Character Recognition (OCR) is a foundational technology that directly addresses this problem, providing a powerful method for capturing specific data from structured documents and paving the way for workflow automation.
This guide provides a comprehensive overview of Zonal OCR, explaining how it works, how it compares to the more advanced Intelligent Document Processing platforms (IDP), and where it delivers the most value for businesses.
What is Zonal OCR?
Zonal OCR is a specialized data extraction technology that identifies and captures text from specific, predefined zones within a document, such as a scanned image or PDF.
Unlike traditional OCR, which extracts all text from a page without any bounds, Zonal OCR provides a targeted, laser-focused approach, converting the captured text into a structured format like JSON, CSV, or a database entry. This method is ideal for processing structured documents where key information consistently appears in the same exact location each time. Think of invoice numbers, patient names on forms, or shipping details on a bill of lading.
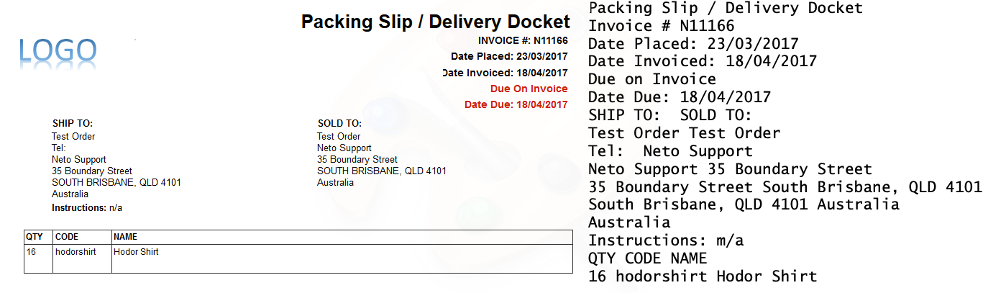
The primary function of Zonal OCR is to serve as a bridge between simple document digitization and intelligent automation. While full-page OCR creates a searchable but fundamentally unstructured block of text, Zonal OCR imposes a layer of structure by isolating specific data points and assigning them labels (e.g., "Invoice Number" = "INV-12345").
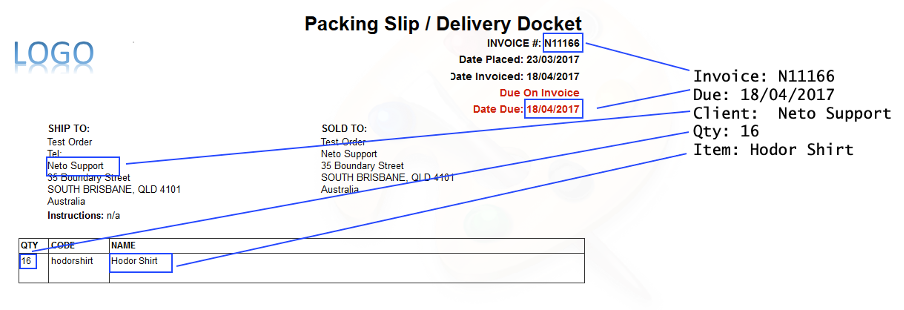
This creation of structured, key-value pair data is what enables the automation of downstream business processes. Without this structure, the output of basic OCR is not directly usable for tasks like populating an accounting system or a patient database. Therefore, Zonal OCR represents a critical evolutionary step that made OCR output machine-usable, paving the way for automated data entry and workflow optimization in controlled, predictable environments.
How does Zonal OCR work
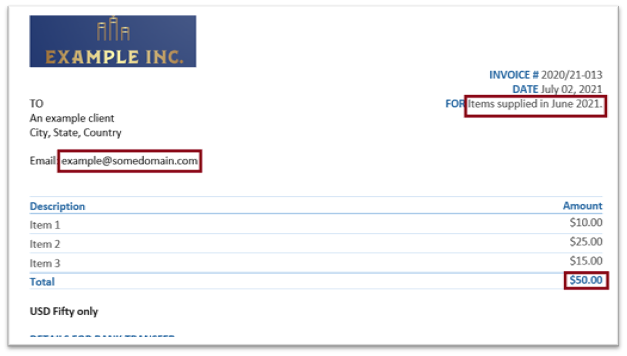
The implementation of Zonal OCR follows a systematic, multi-stage process that turns a static document image into actionable, structured data. The quality of the final output is determined by how well each step in the process was executed.
1. Template definition
The process begins with the manual creation of a template, which serves as a blueprint for the OCR engine. As a user, you need to take a representative sample of a specific document type (e.g., an invoice from Vendor A) and use the software's interface to draw rectangular zones around the exact locations of the data fields that need to be extracted.
Each zone is then mapped to a specific data field, like Invoice_Number, Due_Date, or Total_Amount. These actions become the fixed map that the system will apply to all subsequent documents of the same layout.
2. Document pre-processing
Before any text recognition occurs, the software performs a series of image enhancement steps to optimize the document for accuracy. This is a critical stage, as the quality of the input image directly impacts the quality of the OCR output.
Deskewing: Correcting the alignment of a document that was scanned at a slight angle.
Noise reduction: Removing random speckles or "salt-and-pepper" noise that can be mistaken for characters.
Binarization: Converting a grayscale image into a black-and-white image to create a sharper contrast between text and background.
Resolution enhancement: Sharpening the image to make character edges more distinct.
3. Zone detection and text recognition
When a new document enters the workflow, the system first identifies it and aligns it with the corresponding predefined template. It then locates the specified zones based on their coordinates.
The OCR engine focuses its character recognition algorithms exclusively within the boundaries of these zones, ignoring all other text and graphical elements on the page. This targeted approach is what gives Zonal OCR its speed and precision in controlled environments.
4. Data extraction and structuring
After the text within each zone is recognized, it is extracted and converted into a machine-readable format. The system then populates a structured data object, such as a JSON file or XML output, using the predefined field labels from the template.
The final output is a clean, organized set of key-value pairs that can be seamlessly exported to other business systems, such as an ERP platform, a CRM system, or accounting software, for further processing.
Differentiating Zonal OCR, template-based OCR, and full-page OCR
Understanding the distinctions between different OCR terminologies is essential for making an informed technology decision.
Full-page OCR: This is the most basic form of OCR. It processes an entire document and attempts to convert all recognized text into a digital format, typically as a hidden text layer on top of the original image in a PDF.
The output is a single, unstructured block of text. While this makes the document searchable for keywords, it does not distinguish between different data fields. Its primary use case is for digital archiving and basic information retrieval, not for automated data extraction into structured systems.
Zonal OCR refers to the technique of confining the OCR process to a specific, demarcated region of a document.
Template-based OCR refers to the system or framework that uses a predefined map (the template) to apply one or more of these zones to a document with a specific layout.
For all practical purposes, a system that uses Zonal OCR is template-based. It operates on a fixed set of rules that are entirely dependent on the spatial location of data.
Zonal OCR in practice: Industry use cases and quantifiable ROI
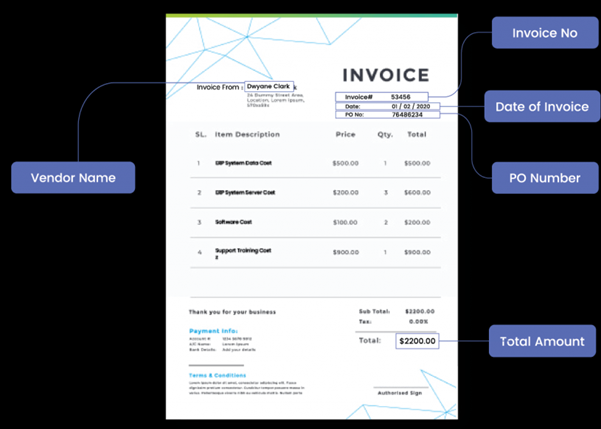
Zonal OCR, when deployed in the appropriate context, can enhance efficiency, reduce costs, and improve data accuracy across several key industries. This section examines specific use cases in finance, healthcare, and logistics, supported by quantitative data and case study analysis.
a. Finance and accounts payable automation
Zonal OCR is widely applied to automate the extraction of key data fields from supplier invoices. For businesses that work with a manageable number of vendors or can enforce a standardized invoicing format, Zonal OCR can reliably capture critical information such as Invoice Number, Vendor Name, PO Number, Line Items, Total Amount, and Due Date.
This extracted data is then used to automate the 3-way matching process (comparing the invoice to the purchase order and the goods receipt note) and to populate the company's accounting or ERP system.
How does it help
- Cost reduction: Manual invoice processing is estimated to cost between $15 and $40 per invoice, factoring in labor, error correction, and delays. Automated solutions using OCR can reduce this cost by up to 80-90%, bringing the per-invoice cost down to under $5. For a company processing thousands of invoices per month, this translates into hundreds of thousands of dollars in annual savings.
- Time Savings: The time required to process a single invoice can be reduced from days or weeks in a manual system to just minutes or seconds with automation. This acceleration allows companies to take advantage of early payment discounts and improve relationships with vendors.
b. Healthcare document management
Zonal OCR is highly effective for processing the vast number of structured forms used in healthcare. This includes patient intake forms, insurance claim forms and patient consent letters.
How does it help
- Seamless data flow: The technology can automatically extract patient demographic information, insurance policy numbers, diagnosis codes (ICD-10), and procedure codes (CPT), and populate this data directly into an Electronic Health Record (EHR) or a hospital's billing system.
- Accuracy: For standardized, machine-printed forms, Zonal OCR can deliver the required level of precision.
- Efficiency gains: By automating the data collection process, Zonal OCR reduces the administrative burden on clinical staff, minimizes the risk of manual entry errors, and allows healthcare professionals to dedicate more time to direct patient care.
c. Logistics and supply chain optimization
Zonal OCR is used to automate data extraction from critical logistics documents like the Bill of Lading (BOL), commercial invoices, and packing lists. Key data fields, including shipper and consignee names and addresses, BOL numbers, container numbers, shipment dates, and freight charges, can be automatically captured.
How does it help
- Faster processing: The extracted data can be fed into a Warehouse Management System (WMS) or Transportation Management System (TMS) to facilitate faster goods receiving, customs clearance, and shipment tracking.
- Efficiency gains: The speed of logistics operations is a key competitive differentiator. Automation of document processing directly contributes to this speed.
The following matrix evaluates the suitability of Zonal OCR for specific document types across key industries. This tool helps organizations quickly assess whether their primary document workflows are a good fit for a template-based automation strategy.
The available zonal OCR tools and options in the market
While the concept of Zonal OCR is straightforward, its implementation can range from do-it-yourself (DIY) developer projects to user-friendly, off-the-shelf software. Understanding this landscape is key to finding the right-fit solution.
The market can be broken down into three main categories: open-source libraries, freemium/entry-level tools, and commercial enterprise platforms.
1. Open-source libraries
For organizations with in-house development talent, open-source libraries offer maximum flexibility and zero licensing cost. However, they require significant technical expertise to implement and maintain.
Tesseract OCR + OpenCV: Tesseract was initially developed by HP and is now maintained by Google. By default, this OCR engine performs full-page OCR. OpenCV, a computer vision library, is used for the crucial pre-processing and zone detection steps.
Developers use OpenCV for tasks like deskewing images, reducing noise, and, most importantly, implementing template matching algorithms to locate the predefined zones on new documents before passing their coordinates to Tesseract.
Pros: Completely free, highly customizable, and gives total control over the workflow.
Cons: Requires programming skills, lacks a graphical user interface (GUI), and demands manual effort for image pre-processing and maintenance.
2. Basic data extraction tools
This category is ideal for small to medium-sized businesses (SMBs) or for teams wanting to automate workflows without writing code. These tools provide an intuitive, visual interface for creating templates.
Parseur/DocParser: These tools do template-based extraction. It allows a user to upload a sample document (like a PDF or an email) and draw boxes around the data fields they want to capture. This visual point-and-click process creates a template that the system then applies to all future documents with the same layout. They offers both Zonal OCR for fixed-position data and Dynamic OCR for data that might shift vertically (like line items in a table).
Pros: No-code and easy to use, affordable subscription plans, and offers a free tier for low-volume testing.
Cons: Still fundamentally template-based, so it will fail if layouts change. It may be less scalable for very high-volume enterprise needs.
3. Advanced data extraction solutions
Like we discussed earlier, if you need to integrate extracted data to external solutions or setup complex automated workflows, you'd need platforms that offer superior accuracy, scalability, and support.
ABBYY FineReader: ABBYY is a long-standing player in this market, renowned for its OCR engine. It allows developers to integrate its engine into custom applications and programmatically define zones for extraction, offering far greater performance and reliability than open-source alternatives. FineReader is designed for high-volume, centralized processing of documents based on defined workflows.
Tungsten Automation: Kofax is another giant in the document capture industry. Its platforms, like TotalAgility, have historically been built around the concept of document classification and template-based extraction. These systems are robust, highly scalable, and designed for processing millions of documents in complex enterprise environments.
Pros: Extremely high accuracy, professional support, and built for high-volume, secure processing.
Cons: Significantly higher cost (enterprise-level pricing), and implementation can be more complex than entry-level tools.
When Zonal OCR hits its limits: The case for Intelligent Document Processing
So, Zonal OCR operates on a rigid, location-dependent system. The user must manually define a template for each unique document layout, and the software is programmed to extract data from those exact coordinates.
In contrast, IDP moves beyond fixed rules and locations by incorporating a suite of advanced technologies, including OCR, Artificial Intelligence (AI), Machine Learning (ML), and Natural Language Processing (NLP). Instead of relying on the data's location, IDP is trained to understand the context of the data.
It can identify a field labeled Invoice Number regardless of its position on the page because its ML models have been trained on thousands of document examples to recognize the linguistic and visual patterns associated with that specific field. As a result, IDP systems are often described as template-free and have the ability to improve their accuracy and adapt over time as they are exposed to more documents.
When to choose what – Zonal OCR vs IDP
Zonal OCR: When the document processing workflow involves a high volume of structured documents with fixed, unchanging layouts.
- Examples: Standardized internal forms, specific vendor invoices where the format is consistent, or government-issued documents.
- Reasoning: In predictable environments, Zonal OCR is a highly accurate and cost-effective solution for automation.
IDP solution: When the workflow involves semi-structured or unstructured documents with variable layouts.
- Examples: Processing invoices from hundreds of different vendors, extracting data from contracts, or interpreting customer emails.
- Reasoning: In these dynamic environments, a template-based approach is impractical and will fail, while the adaptive capabilities of IDP make it scalable and automation-friendly.
Zonal OCR vs. IDP: A head-to-head comparison
How Zonal OCR and IDP handle document variability
Zonal OCR: The primary and most critical limitation of Zonal OCR is its inability to handle variations in document layout. Because Zonal OCR is fundamentally tied to the coordinates of a predefined template, any deviation from that template can break the entire automation process.
Common sources of failure include a vendor redesigning their invoice format, a different printer causing slight shifts in text alignment, or a page being skewed during scanning. When a failure occurs, the process requires manual intervention to correct the data and, in the case of a new layout, the creation of an entirely new template. This makes Zonal OCR a brittle and unscalable solution for any business that deals with a diverse and evolving set of document sources.
IDP: IDP was developed specifically to solve this problem. Its ability to understand content and context makes it inherently resilient to layout variations. An IDP system can correctly process invoices from thousands of different suppliers without needing a unique template for each one.
This adaptability makes IDP a far more robust, scalable, and practical solution for automating document processing in most modern business environments.
Which document processing software provides the best value?
Nanonets demo
The market has evolved. Today, pure Zonal OCR tools are less common. Most modern software vendors offer comprehensive IDP platforms that often include Zonal OCR as a feature but lead with their AI-powered, template-free capabilities. This shift acknowledges that most businesses deal with a mix of structured and semi-structured documents and require a more flexible solution.
The choice between a simple Zonal tool and an IDP platform depends on your documents. Do you operate in a controlled environment with fixed formats or a dynamic one with constant variation?
The following analysis examines leading vendors in the space. While most are IDP platforms, we will frame them in the context of their capabilities, starting from simple template-based extraction and moving towards full AI-driven automation.
A buyer's guide: Selecting your document processing solution
Choosing the right software requires a clear understanding of your own processes. Use this guide to make an informed decision.
1. Analyze your documents:
- Structure: Are your document layouts fixed and unchanging? (If yes, Zonal OCR is viable). Or do they vary? (If yes, you need an IDP.)
- Volume: How many documents do you process monthly? This determines whether a free tier, an SMB plan, or an enterprise solution is appropriate.
- Source: Do documents arrive as email attachments, scans, or via an API? Ensure the solution handles your primary sources.
2. Define your requirements:
- Internal resources: Do you have developers to build a solution with Tesseract or an SDK? Or do you need a no-code tool like Parseur?
- Integration: What other software (ERP, accounting, cloud storage) must this tool connect with? Check for pre-built integrations or a robust API.
- Accuracy threshold: What level of accuracy is acceptable? For financial or medical data, the high precision of an enterprise engine like ABBYY might be non-negotiable.
3. Evaluate future needs:
- Scalability: Will your document volume or the number of different layouts grow over time? An IDP solution is far more scalable for handling increasing diversity.
- Workflow complexity: Do you just need data extraction, or do you require more advanced workflow capabilities like multi-step approvals, data validation against external databases, and exception handling?
Final recommendations
- For DIY and developers: Start with Tesseract and OpenCV. It's free and provides complete control if you have the technical skills.
- For SMBs with fixed formats: Choose something like Parseur or Docparser. It's the most direct, user-friendly, and cost-effective path to automating Zonal OCR for structured documents and emails.
- For mid-market companies and enterprises with mixed documents: Evaluate a flexible IDP platform like Nanonets. It provides a balance of AI-powered flexibility and user-friendly workflow automation.
Frequently asked questions
1. What is the difference between Zonal OCR and traditional OCR?
Traditional OCR processes entire documents sequentially, converting all text into unstructured plain text without differentiation. Zonal OCR targets specific predefined areas or "zones" within documents, extracting only relevant data fields and converting them into structured formats like JSON or XML.
Key differences:
- Processing scope: Traditional OCR reads everything; Zonal OCR reads only designated zones
- Output format: Traditional OCR produces plain text; Zonal OCR creates structured data
- Accuracy: Zonal OCR achieves 90-99% accuracy for specific fields vs. traditional OCR's 70-85%
- Use case: Traditional OCR for full document digitization; Zonal OCR for targeted data extraction
2. How accurate is Zonal OCR compared to manual data entry?
Modern Zonal OCR systems achieve 95-99% accuracy rates for structured documents, which matches or exceeds typical manual data entry accuracy (95-98%). However, Zonal OCR processes documents 100x faster than manual entry.
Accuracy factors:
- Document quality: High-resolution scans (300+ DPI) yield best results
- Document structure: Consistent layouts produce higher accuracy
- Field complexity: Simple numeric fields more accurate than complex text
- Template quality: Well-designed zones improve extraction precision
The combination of high accuracy and dramatically faster processing makes Zonal OCR significantly more cost-effective than manual data entry for high-volume document processing.
3. What types of documents work best with Zonal OCR?
Zonal OCR excels with structured and semi-structured documents where data fields appear in predictable locations:
Optimal document types:
- Invoices and bills: Invoice numbers, dates, totals, vendor information
- Forms and applications: Insurance forms, loan applications, surveys
- Financial documents: Bank statements, receipts, purchase orders
- ID documents: Driver's licenses, passports, employee badges
- Healthcare records: Patient forms, insurance claims, lab results
Best characteristics:
- Consistent layout across document batches
- Clear field labels and boundaries
- Machine-printed text (though handprint is possible with ICR)
- High image quality and contrast
- Standard paper sizes and orientations
4. Can Zonal OCR handle documents with varying layouts?
Basic Zonal OCR struggles with layout variations, as it relies on fixed zone positions. However, advanced AI-powered solutions can adapt to layout changes through:
Adaptive capabilities:
- Dynamic zone detection: AI identifies field locations based on labels and context
- Template learning: Machine learning adapts to new layouts automatically
- Flexible positioning: Zones can accommodate slight positional shifts
- Multi-template support: Different templates for various document formats
Limitations remain for:
- Completely unstructured documents
- Fields that move significantly between document versions
- Documents with no consistent labeling patterns
Modern solutions like Nanonets use AI to overcome traditional Zonal OCR limitations, handling varied layouts without requiring separate templates for each format.
5. How do you set up OCR zones for document processing?
Setting up Zonal OCR zones typically follows a 4-step visual process:
Zone Setup Process:
- Upload sample document: Provide a clean template of your document type
- Draw zone boundaries: Click and drag to create rectangles around target fields
- Label and configure zones: Name each field (e.g., "invoice_number", "total_amount")
- Set field properties: Define data types (text, number, date) and validation rules
Best practices:
- Use high-quality samples: 300+ DPI resolution for optimal results
- Allow zone padding: Make zones slightly larger than text to accommodate variations
- Test with multiple samples: Validate zones work across different document instances
- Set validation rules: Use formats, ranges, or regex patterns to catch errors
Advanced features:
- Smart zones: Use regular expressions for complex pattern matching
- Conditional extraction: Set rules for optional or conditional fields
- Multi-page support: Configure zones across different page layouts
6. What happens when document quality is poor or images are blurry?
Poor document quality significantly impacts Zonal OCR accuracy, but several strategies can help:
Quality requirements:
- Minimum resolution: 300 DPI recommended for optimal results
- Contrast: Clear distinction between text and background
- Alignment: Properly oriented and straight documents
- Clarity: Minimal blur, smudging, or distortion
Impact of poor quality:
- Reduced accuracy: Can drop from 95% to 60-80% with poor images
- Increased errors: Misread characters and failed field detection
- Processing failures: Severely damaged documents may not process at all
Mitigation strategies:
- Pre-processing: Automatic image enhancement, deskewing, noise removal
- Confidence scoring: Flag low-confidence extractions for manual review
- Fallback options: Human-in-the-loop validation for unclear text
- Advanced AI: Machine learning models trained on damaged documents
Modern OCR systems include automatic image enhancement to improve results from poor-quality inputs.
7. Zonal OCR vs AI-powered document processing - which should I choose?
The choice depends on your document types and processing requirements:
Choose Zonal OCR when:
- Processing high volumes of consistent document formats
- Documents have predictable field locations
- Speed and cost-effectiveness are primary concerns
- Working with structured forms, invoices, or applications
- Need simple, reliable automation for routine documents
Choose AI-powered processing when:
- Handling diverse document types with varying layouts
- Processing unstructured or semi-structured documents
- Need contextual understanding of document content
- Documents contain complex tables or narrative text
- Flexibility and adaptability are more important than speed
Hybrid approach: Many organizations use both - Zonal OCR for routine, structured documents and AI-powered processing for complex or varied documents. This maximizes efficiency while handling edge cases effectively.
8. Can Zonal OCR process handwritten text and signatures?
Handwritten text: Zonal OCR can process hand-printed text using ICR (Intelligent Character Recognition) technology, but with important limitations:
ICR capabilities:
- Hand-printed characters: Individual, separated letters and numbers
- Structured fields: Text within defined boxes or forms
- Accuracy: 85-95% for clear handwriting in controlled formats
ICR limitations:
- Cannot read cursive writing or connected script
- Requires clear, separated characters
- Performance varies significantly with handwriting quality
- Limited language support compared to printed text OCR
Signatures: Zonal OCR can detect signature presence but cannot convert signatures to text. It can:
- Verify if a signature field is filled
- Extract signature as an image for verification
- Flag documents missing required signatures
Best practices for handwritten text:
- Design forms with individual character boxes
- Use drop-out colors for form backgrounds
- Provide clear instructions for hand-printing
- Implement validation rules and manual review workflows
9. How long does it take to process documents with Zonal OCR?
Processing speed varies based on document complexity and system configuration:
Typical processing times:
- Simple forms: 1-3 seconds per page
- Complex invoices: 3-5 seconds per page
- Multi-page documents: 2-4 seconds per page
- Batch processing: 1,000-10,000 pages per hour
Factors affecting speed:
- Number of zones: More extraction fields increase processing time
- Document resolution: Higher resolution images take longer to process
- Hardware specs: CPU power and memory significantly impact speed
- Validation complexity: Advanced rules and checks add processing time
Performance optimization:
- Batch processing: Process multiple documents simultaneously
- Parallel processing: Use multiple CPU cores or servers
- Cloud scaling: Automatically scale processing capacity
- Smart queuing: Prioritize urgent documents
Comparison to manual processing:
- Manual data entry: 15-30 minutes per invoice
- Zonal OCR: 3-5 seconds per invoice
- Speed improvement: 300-600x faster than manual processing
10. What's the typical ROI timeline for implementing Zonal OCR?
Most organizations see positive ROI within 3-6 months of implementation:
ROI factors:
- Labor cost savings: 50-80% reduction in data entry time
- Error reduction: 60-90% fewer data entry mistakes
- Processing speed: 100-500x faster than manual entry
- Scalability: Handle volume spikes without additional staff
Investment timeline:
- Month 1-2: Implementation and training
- Month 3-4: Initial productivity gains visible
- Month 6-12: Full ROI realization and optimization
- Year 2+: Compound benefits through process improvements
Typical savings:
- Small businesses (1,000 docs/month): $15,000-30,000 annually
- Medium enterprises (10,000 docs/month): $150,000-300,000 annually
- Large organizations (100,000+ docs/month): $1M+ annually
Break-even calculation:
- Software costs: $10,000-50,000 annually
- Implementation: $5,000-25,000 one-time
- Labor savings: $25-50 per hour eliminated
- Most organizations break even after processing 2,000-5,000 documents
Success factors for faster ROI:
- Start with high-volume, routine document types
- Ensure good document quality and consistent formats
- Implement proper training and change management
- Monitor and optimize extraction accuracy regularly
11. Is Zonal OCR the right fit for your business?
Zonal OCR is the right fit for your business if your primary objective is to automate high-volume data entry for documents that share a consistent, fixed layout. In these highly structured scenarios, it offers exceptional precision and processing speed, delivering a clear and immediate return on investment.
However, if your documents exhibit any significant variation in format, or if your workflow requires the extraction of data from handwritten text or unstructured paragraphs, a more advanced IDP solution is the necessary and more appropriate choice.
12. Explicit advantages of Zonal OCR
When applied to the correct use case, Zonal OCR offers several compelling benefits that make it a valuable tool for automation.
- High Precision on structured data: The core strength of Zonal OCR is its accuracy within a controlled environment. By focusing its recognition engine exclusively on predefined zones, it effectively ignores all irrelevant information on the page, such as logos, graphics, or extraneous text. This targeted approach minimizes the risk of misinterpretation and allows the technology to achieve accuracy rates of 95-99% for well-defined, structured documents.
- Increased speed and efficiency: Automating data extraction with Zonal OCR dramatically reduces the time and labor associated with manual data entry. Processes that would take several minutes per document for a human to complete can be executed in seconds by the software. This acceleration of the data capture process leads to shorter overall cycle times for business workflows like invoice approval or patient onboarding.
- Cost-effectiveness for simple workflows: For businesses whose operations are dominated by predictable and standardized document formats, Zonal OCR solutions often present a more cost-effective option than full-fledged IDP platforms. The technology is more mature, and the software licensing can be less expensive, providing a lower barrier to entry for automation.
- User control and simplicity: The template-based nature of Zonal OCR provides users with complete and granular control over the data extraction process. The setup, which often involves a visual point-and-click or draw-a-box interface, is highly intuitive and can typically be managed by non-technical business users without the need for developer intervention. This simplicity allows for rapid deployment in suitable environments.
13. Tradeoffs and limitations of Zonal OCR to consider
- Dependency on fixed layouts: This is the technology's most critical weakness. The entire system is built on the assumption that data will always appear in the same location. It is fundamentally brittle and cannot adapt to any changes in document format, however minor.
- Inability to process semi-structured/unstructured data: Zonal OCR is incapable of extracting information from documents where data fields do not have a fixed position. This includes most real-world invoices, purchase orders from diverse suppliers, contracts, and correspondence, which are classified as semi-structured or unstructured documents.
- Significant scalability issues: The manual, template-based setup creates a major scalability bottleneck. Every new document layout requires a user to create and configure a new template. For a business that deals with hundreds or thousands of vendors, this becomes an unmanageable and cost-prohibitive task.
- Sensitivity to image quality: The accuracy of Zonal OCR is highly dependent on the quality of the scanned image. Common issues like skewed pages, low resolution, or distortions can cause the predefined zones to misalign with the text on the page, resulting in failed or incorrect data extraction.