ABBYY FineReader is a document processing tool that helps businesses turn paper documents into digital files. It uses OCR technology to read text from scanned documents, edit PDFs, and convert files between different formats. While it's been a popular choice for many years, businesses are finding that it doesn't always meet their current needs.
Our analysis shows that ABBYY FineReader falls short in five key areas:
2. Processing multiple documents is slow and needs manual work
3. Working with complex document layouts reduces accuracy
4. Connecting to modern business tools requires extra development
5. Costs increase quickly when processing more documents
Let's look at the top alternatives that can help you solve these problems.
A quick comparison of ABBYY FineReader alternatives
| Tool | Best For | Starting Price | Free Trial | G2 Rating | Key Strength | Total Score* |
|---|---|---|---|---|---|---|
| ABBYY FineReader | Document conversion | $16/month | No | 4.7 | OCR accuracy | 44.3 |
| Readiris Pro | Multilingual OCR | Custom | Yes | NA | Language support | N/A |
| OmniPage Ultimate | Batch processing | $499 one-time | Yes | NA | Enterprise OCR | N/A |
| Adobe Acrobat | PDF management | $22.19/month | Yes | 4.7 | Integration ecosystem | 43.4 |
| Nitro Pro | Enterprise PDF | $14.99/month | Yes | 4.3 | E-signatures | 43.8 |
| Foxit PDF Editor | Cost-effective PDF | $129.99/year | Yes | 4.6 | Office-like interface | 44.9 |
| PDFelement | User-friendly PDF | $9.08/month | Yes | 4.4 | Easy adoption | 44.9 |
| Nanonets | AI automation | Free - 500 pages | Yes | 4.8 | No templates needed | 46.5 |
| Rossum | Invoice processing | Custom | Yes | 4.4 | AP automation | 44.0 |
| Veryfi | Receipt processing | $500/month | Yes | 4.3 | Mobile capture | 46.6 |
| Square 9 | Workflow automation | $50/user/month | No | 4.7 | Process automation | 44.9 |
(*Total score combines ease of use, setup time, support quality, feature completeness, and user satisfaction based on real implementation data)
Now, let’s explore each alternative in detail.
1. Readiris Pro
Readiris is a powerful and accurate OCR engine that can be used to convert scanned documents and images into editable and searchable text. It offers a wide range of features and options, making it a versatile and powerful OCR solution for various needs.
1. Multilingual OCR (130+ languages)
2. Table recognition engine
3. Cloud service integration (Google Drive, OneDrive)
4. Built-in PDF editor
5. Barcode and QR code reading
6. Vector graphics recognition
7. Batch processing capabilities
8. Document format conversion
| Pros of Readiris | Cons of Readiris |
|---|---|
| Strong multilingual OCR | Poor support response |
| Good table recognition | Struggles with complex layouts |
| Cloud integration | Resource-intensive |
| Batch processing | Limited PDF editing |
| Accurate with clear scans | Requires high-quality input |
| Easy language switching | Occasional crashes |
Pricing: Custom pricing based on features needed. Multiple tiers available.
Best suited for: Organizations working with multilingual documents, particularly those needing multi-language support and table extraction capabilities.
How does Readiris compare to ABBYY FineReader?
Note: Unlike other tools in our comparison, we don't have sufficient data to provide standardized scoring metrics for Readiris. However, based on available user stories, we know Readiris excels is fairly easy-to-use and users consistently praise its accuracy with clear scans.
While ABBYY FineReader offers more comprehensive features and better support, Readiris provides a viable alternative specifically for multilingual document processing needs.
2. Tungsten OmniPage
OmniPage (formerly Kofax Omnipage) is one of the oldest and most established OCR solutions in the market. While ABBYY focuses on continuous cloud-based innovation, OmniPage specializes in high-accuracy desktop OCR with extensive batch processing capabilities.
1. 99% accurate OCR technology
2. Support for 120+ languages
3. Custom workflow automation
4. Batch document processing
5. Multiple format conversion
6. Form data extraction
7. Document archiving
8. Enterprise deployment options
| Pros of OmniPage | Cons of OmniPage |
|---|---|
| High OCR accuracy | No updates since 2013 |
| Strong batch processing | Dated user interface |
| Custom workflow creation | Resource-intensive |
| One-time purchase | Limited cloud features |
| Good with structured docs | Steep learning curve |
| Enterprise deployment | Requires local installation |
Pricing: Two tiers: standard: $149 (one-time) and ultimate: $499 (one-time).
Best suited for: Organizations needing high-accuracy OCR with batch processing capabilities, particularly enterprises processing large volumes of structured documents.
How does OmniPage compare to ABBYY FineReader?
Note: Unlike other tools in our comparison, we don't have sufficient data to provide standardized scoring metrics for OmniPage. However, based on available reviews, OmniPage matches ABBYY's OCR accuracy but falls behind in modern features and updates.
While it offers powerful batch processing and workflow automation, its last major update was in 2013, making ABBYY the more current solution for cloud and mobile needs.
Read About: Tungsten Automation Alternative
3. Adobe Acrobat
Adobe Acrobat is a comprehensive PDF and document management tool used by businesses of all sizes. While ABBYY FineReader specializes in OCR and document scanning, Adobe Acrobat offers broader document creation and e-signature capabilities.
1. E-signature collection and tracking
2. PDF creation and editing
3. Document generation tools
4. File format conversion
5. Document protection and security
6. Form creation and management
7. Cloud-based collaboration
| Pros of Adobe Acrobat | Cons of Adobe Acrobat |
|---|---|
| Strong PDF editing features | Higher price than ABBYY |
| Unlimited e-signatures | More complex to learn |
| Good file conversion | Accessibility tools need work |
| Reliable performance | Resource-intensive |
| Wide format support | Setup can be challenging |
| Strong market presence | Some features hard to find |
Pricing: Starts at $22.19/month for teams with annual commitment.
Best for: Organizations that need comprehensive PDF management with e-signature capabilities, especially mid-market and enterprise companies.
How does Adobe Acrobat compare to ABBYY FineReader?
| What We Measure | Adobe Acrobat | ABBYY FineReader |
|---|---|---|
| Ease of Use | 8.7 | 8.9 |
| Setup Time | 8.8 | 9.3 |
| Support Quality | 8.4 | 8.4 |
| Meets Requirements | 9.2 | 8.9 |
| Product Direction | 8.3 | 8.8 |
4. Nitro Pro
Nitro Pro is a comprehensive PDF software that combines document editing, e-signatures, and collaboration features in one platform. The software lets you edit PDFs, convert documents between formats, collect signatures, and manage document workflows across teams. While ABBYY FineReader focuses on accurate OCR and document conversion, Nitro Pro aims to handle all aspects of daily PDF work - from simple edits to complex approval processes.
1. PDF creation and editing
2. Real-time collaboration
3. Document security tools
4. Microsoft Office integration
5. Cloud document sharing
6. Basic OCR capabilities
7. Form automation
| Pros of Nitro Pro | Cons of Nitro Pro |
|---|---|
| Cost-effective licensing | OCR accuracy issues |
| Quick implementation | Crashes with large files |
| Strong e-signature tools | Some compatibility issues |
| Familiar Office interface | Requires frequent saving |
| Good for daily PDF tasks | Limited advanced features |
| Active development | Basic template options |
Pricing: Starting at $14.99/user/month. Volume discounts available for 20+ users.
Best for: Mid-market and enterprise organizations hat need a cost-effective PDF solution with strong e-signature capabilities, particularly in IT and financial services. The platform works especially well for Microsoft Office-centric teams.
How does Nitro Pro compare to ABBYY FineReader?
| What We Measure | Nitro Pro | ABBYY FineReader |
|---|---|---|
| Ease of Use | 8.8 | 8.9 |
| Setup Time | 9.1 | 9.3 |
| Support Quality | 8.0 | 8.4 |
| Meets Requirements | 8.8 | 8.9 |
| Product Direction | 8.0 | 8.8 |
5. Foxit PDF Editor
Foxit PDF Editor is a cost-effective alternative to both ABBYY and Adobe, offering PDF editing capabilities with an interface similar to Microsoft Office. While ABBYY focuses on OCR and document processing, Foxit emphasizes PDF management with additional features like AI-powered redaction and mobile accessibility.
1. Advanced PDF editing tools
2. E-signature capabilities
3. File format conversion
4. Document generation
5. Desktop publishing features
6. Cloud storage (130GB)
7. Admin console for teams
8.Security and encryption
| Pros of Foxit PDF | Cons of Foxit PDF |
|---|---|
| Better value than ABBYY | Less OCR functionality |
| Microsoft-style interface | Font handling issues |
| Fast performance | Limited scanning features |
| Strong customer support | Some saving problems |
| Good for construction/accounting | Learning curve for new users |
| Enterprise security features | Print formatting issues |
Pricing: $129.99/user/year for PDF Editor with Admin Console.
Best for: Small to mid-sized businesses (66% of users) that need strong PDF editing capabilities with basic document processing.
How does Foxit PDF Editor compare to ABBYY FineReader?
| What We Measure | Foxit PDF | ABBYY FineReader |
|---|---|---|
| Ease of Use | 9.0 | 8.9 |
| Setup Time | 9.1 | 9.3 |
| Support Quality | 8.9 | 8.4 |
| Meets Requirements | 9.3 | 8.9 |
| Product Direction | 8.8 | 8.8 |
6. Wondershare PDFelement
Wondershare PDFelement is a PDF management tool that aims to simplify document workflows. It combines traditional PDF editing with AI-powered features, positioning itself as a more affordable alternative to both Adobe Acrobat and ABBYY FineReader PDF.
1. AI-powered PDF editing and summarization
2. Document conversion and batch processing
3. OCR text recognition
4. Electronic signatures
5. Form creation and handling
6. Cloud storage integration
7. Multi-language support
8. Annotation tools
| Pros of PDFelement | Cons of PDFelement |
|---|---|
| Modern, intuitive interface | Slower with large files |
| Affordable pricing | OCR less accurate than ABBYY |
| One-time purchase option | Limited cloud features |
| Good batch processing | Some formatting issues |
| AI-powered features | Basic template options |
| Easy learning curve | Limited third-party integrations |
Pricing: Monthly: $9.08/license (paid yearly), Yearly: $109/license, Perpetual: $139 one-time fee per license. Enterprise pricing available.
Best for: Small businesses and teams that need a straightforward way to convert paper documents to digital formats without complex setups.
How does PDFelement compare to ABBYY FineReader?
| What We Measure | PDFelement | ABBYY FineReader |
|---|---|---|
| Ease of Use | 9.0 | 8.9 |
| Setup Time | 9.2 | 9.3 |
| Support Quality | 8.6 | 8.4 |
| Meets Requirements | 9.0 | 8.9 |
| Product Direction | 9.1 | 8.8 |
7. Nanonets
Nanonets takes a different approach to document digitization. Instead of making you create templates for each document type, it uses AI to understand and process documents automatically. This means you can start digitizing documents right away, without spending time on setup.
1. Automatic document type detection
2. Built-in image cleanup tools
3. Text extraction without templates
4. Quality checks for scanned documents
5. Direct export to business systems
6. Multi-page document handling
7. Bulk document processing
8. Support for poor-quality scans
| Pros of Nanonets | Cons of Nanonets |
|---|---|
| Works without templates | Higher starting price |
| Handles messy documents well | Takes time to learn all features |
| Processes multiple pages quickly | Minimum volume requirements |
| Connects easily with other tools | |
| Improves over time | |
| Good customer support |
Pricing: Free for the first 500 pages. Business plans start at $999/month.
Best suited for: Companies that need to digitize different types of documents quickly without creating templates for each one.
How does Nanonets compare to ABBYY FineReader?
| What We Measure | Nanonets | ABBYY FineReader |
|---|---|---|
| Ease of Use | 9.3 | 8.9 |
| Setup Time | 9.2 | 9.3 |
| Support Quality | 9.4 | 8.4 |
| Meets Requirements | 9.2 | 8.9 |
| Product Direction | 9.4 | 8.8 |
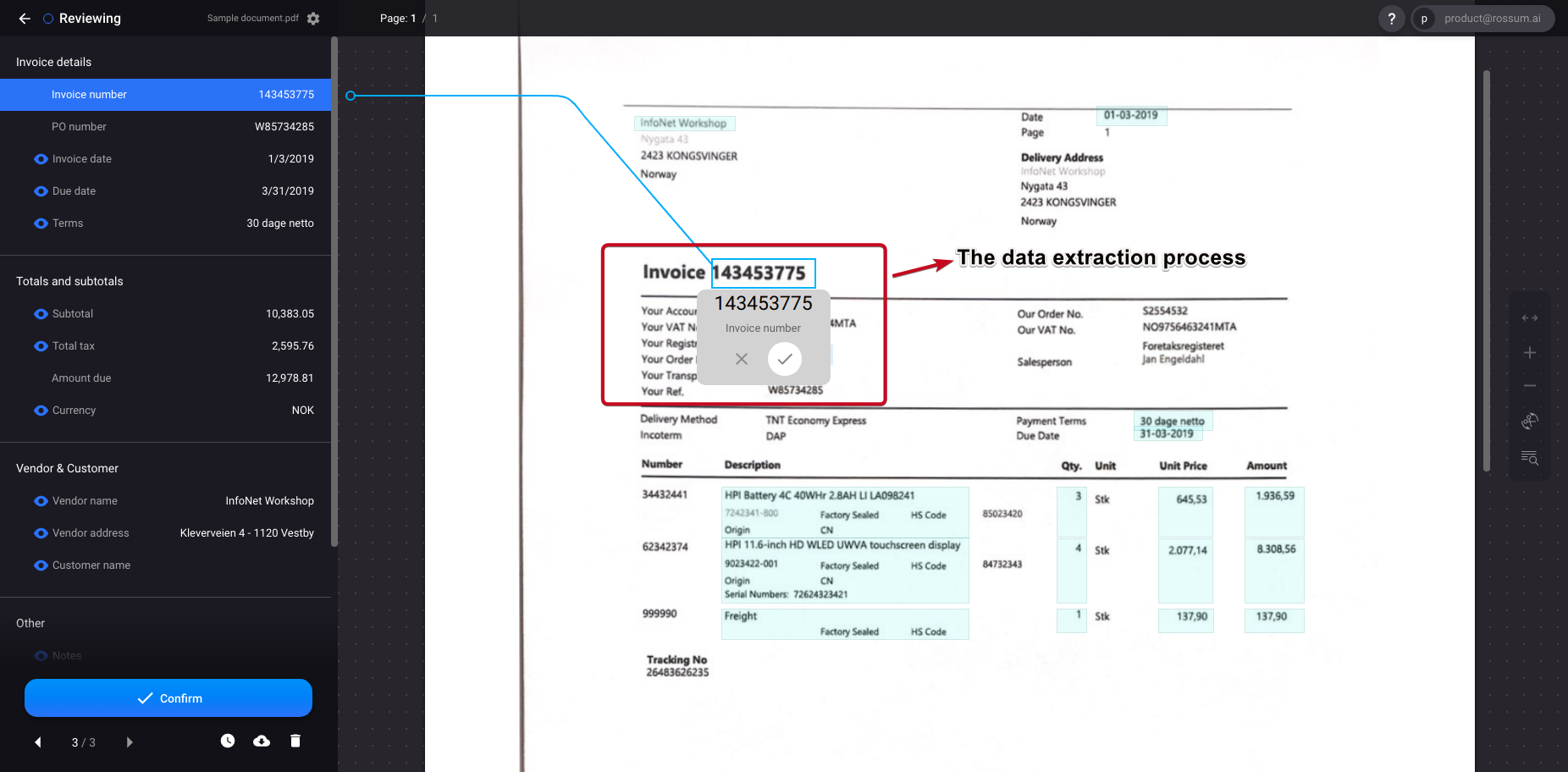
8. Rossum
{kind=link}
Rossum is an intelligent document processing (IDP) platform that focuses on automating document workflows. The software uses AI to extract data from documents, with particular strength in processing invoices and purchase orders.
1. AI-powered data extraction
2. Custom document processing workflows
3. Two-way communication for exceptions
4. Multi-language support
5. API integration capabilities
6. Automated learning system
7. Cloud-based platform
8. Enterprise security features
| Pros of Rossum | Cons of Rossum |
|---|---|
| Strong customer support | Issues with large PDF files |
| Good accuracy for invoices | Expensive pricing model |
| Easy API integration | Slow processing times |
| Flexible customization | Update-related glitches |
| Quick implementation | Learning curve for users |
| Cloud-based solution | Limited Excel support |
Pricing: Custom pricing based on volume and needs. Enterprise-focused pricing.
Best suited for: Medium to large organizations processing high volumes of invoices and financial documents. It's particularly valuable for companies that need to automate accounts payable processes and want a cloud-based solution with strong API capabilities.
How does Rossum compare to ABBYY FineReader?
| What We Measure | Rossum | ABBYY FineReader |
|---|---|---|
| Ease of Use | 8.6 | 8.9 |
| Setup Time | 8.1 | 9.3 |
| Support Quality | 9.2 | 8.4 |
| Meets Requirements | 8.3 | 8.9 |
| Product Direction | 9.8 | 8.8 |
9. Veryfi

Veryfi is an AI-powered document processing platform that specializes in receipt and expense management. Unlike ABBYY's broad document processing approach, Veryfi focuses specifically on helping small businesses automate their expense tracking and management.
1. Real-time receipt capture and processing
2. Multi-document detection technology
3. Line-item extraction for receipts
4. Expense tracking automation
5. Mobile SDK for developers
6. API-first approach
7. Multi-language support
| Pros of Veryfi | Cons of Veryfi |
|---|---|
| Excellent mobile experience | Limited to expense documents |
| Product-level data extraction | Some upload inconsistencies |
| Quick setup process | Occasional glitches |
| Strong customer support | Limited document types |
| Real-time processing | Basic automation options |
| Store location tracking | Some receipts disappear |
Pricing: Base pricing starts at $500/month with a minimum commitment of 6,250 documents monthly. Enterprise pricing available for larger volumes. Free trial available for testing.
Best suited for: Businesses that need immediate, mobile-first document processing. It's particularly valuable for companies handling large volumes of receipts and invoices, especially those in retail, expense management, and financial services who need real-time data extraction.
How does Veryfi compare to ABBYY FineReader?
| What We Measure | Veryfi | ABBYY FineReader |
|---|---|---|
| Ease of Use | 9.3 | 8.9 |
| Setup Time | 9.6 | 9.3 |
| Support Quality | 9.3 | 8.4 |
| Meets Requirements | 9.2 | 8.9 |
| Product Direction | 9.2 | 8.8 |
10. Square 9 Softworks
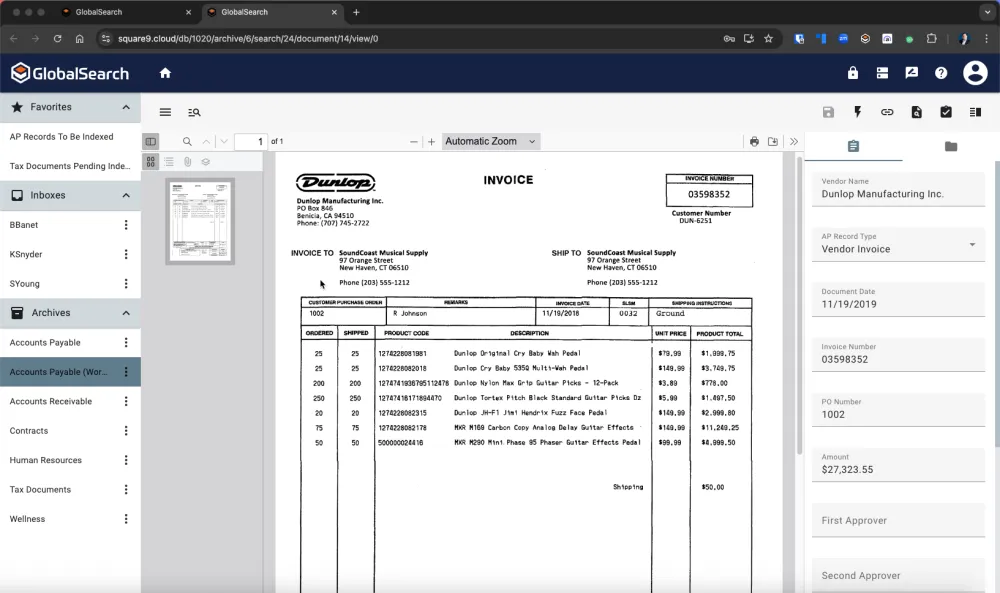
Square 9 Softworks is an AI-powered enterprise content management platform that focuses on complete document lifecycle management. Unlike ABBYY's focus on document processing, Square 9 aims to eliminate paper-based processes entirely through comprehensive workflow automation.
1. Intelligent document capture
2. Business process automation
3. Enterprise content management
4. AP automation workflows
5. Online form building
6. Advanced search capabilities
7. Cloud or on-premise deployment
8. SOC 2 and HIPAA-certified storage
| Pros of Square 9 | Cons of Square 9 |
|---|---|
| End-to-end document management | Complex setup process |
| Strong workflow automation | Steeper learning curve |
| Excellent customer support | Password recovery issues |
| Multiple deployment options | Higher initial costs |
| Good ERP integration | Requires IT expertise |
| Powerful search capabilities | Some performance limitations |
Pricing: Three subscription levels from starting $50/user/month to $75/user/month. Custom pricing available for large deployments.
Best suited for: Mid-market and enterprise organizations looking to transform their entire document management process. It's particularly valuable for companies in manufacturing, healthcare, and government sectors that need to automate complex workflows while maintaining compliance requirements.
How does Square 9 compare to ABBYY FineReader?
| What We Measure | Square 9 | ABBYY FineReader |
|---|---|---|
| Ease of Use | 9.0 | 8.9 |
| Setup Time | 8.4 | 9.3 |
| Support Quality | 9.2 | 8.4 |
| Meets Requirements | 9.1 | 8.9 |
| Product Direction | 9.2 | 8.8 |
How to choose the best ABBYY FineReader alternative?
Based on analyzing hundreds of user migrations from ABBYY FineReader, your choice will depend on several key factors:
Scoring methodology*
We've evaluated each alternative across five key parameters that matter most when switching from ABBYY:
- Ease of use: How quickly teams can start using the tool without extensive training
- Setup time: Implementation effort and template creation needs
- Support quality: Availability and responsiveness of customer support
- Meets requirements: Ability to handle your specific document processing needs
- Product direction: Continuous improvement and feature development pace
| Product | Ease of Use | Setup Time | Support Quality | Meets Requirements | Product Direction | Total Score |
|---|---|---|---|---|---|---|
| ABBYY FineReader | 8.9 | 9.3 | 8.4 | 8.9 | 8.8 | 44.3 |
| Readiris Pro | NA | NA | NA | NA | NA | N/A |
| OmniPage | NA | NA | NA | NA | NA | N/A |
| Adobe Acrobat | 8.7 | 8.8 | 8.4 | 9.2 | 8.3 | 43.4 |
| Nitro Pro | 8.8 | 9.1 | 8.0 | 8.8 | 8.0 | 43.8 |
| Foxit PDF Editor | 9.0 | 9.1 | 8.9 | 9.3 | 8.8 | 44.9 |
| PDFelement | 9.0 | 9.2 | 8.6 | 9.0 | 9.1 | 44.9 |
| Nanonets | 9.3 | 9.1 | 9.4 | 9.1 | 9.6 | 46.5 |
| Rossum | 8.6 | 8.1 | 9.2 | 8.3 | 9.8 | 44.0 |
| Veryfi | 9.3 | 9.6 | 9.3 | 9.2 | 9.2 | 46.6 |
| Square 9 | 9.0 | 8.4 | 9.2 | 9.1 | 9.2 | 44.9 |
Key decision factors
Consider these aspects when choosing an alternative:
Document complexity requirements
- What types of documents do you process most?
- Do you need handwriting recognition?
- How important is multi-language support?
Integration needs
- Which business systems need connection?
- Do you need API access?
- What file formats do you work with?
Cost considerations
- What's your monthly document volume?
- Do you prefer subscription or one-time payment?
- What's your per-page cost target?
Automation requirements
- Do you need workflow automation?
- How important is batch processing?
- Do you need human verification steps?
*Disclaimer: This analysis uses data from independent user reviews, technical documentation, and implementation case studies available as of March 2024. Since document processing technologies evolve rapidly:
- Feature sets and capabilities may change
- Pricing models might differ
- Performance metrics could vary
- Integration options may expand
- New features may be added
We recommend reaching out to vendors directly for current information and testing any solution with your actual documents before deciding.
FAQs
What is better than ABBYY FineReader?
For modern cloud-based document processing, Nanonets offers faster implementation with zero training. For PDF management, Adobe Acrobat provides better integration with creative tools. For cost-effective solutions, Foxit PDF Editor offers similar features at a lower price point. For enterprise document management, Square 9 provides more comprehensive workflow automation.
What is ABBYY software used for?
ABBYY software primarily handles document processing and data extraction. Its main products include FineReader PDF for OCR and PDF editing, FlexiCapture for enterprise document capture, Vantage for intelligent document processing, and Timeline for process intelligence. Organizations use ABBYY to convert scanned documents into editable formats, automate data entry, and streamline document workflows.
Is ABBYY open source?
No, ABBYY is not open source. It's proprietary commercial software. For open-source alternatives, consider Tesseract (supported by Google), OCRmyPDF, or gImageReader, though these require technical expertise to implement and maintain.