
An invoice parser automatically extracts critical data from invoices. If you've ever had to process one manually, you know just how time-consuming and tedious the process can be. Not to mention, there's a risk of human error.
Invoice parser streamlines this process, saving time and improving accuracy. Optical character recognition (OCR) technology enables these tools to extract data from digital PDFs and scanned paper invoices. Businesses can quickly capture financial and vendor information like invoice number, date, total amount, line items, and payment terms.
Advanced invoice parsers now use AI, ML, and workflow automation to streamline accounts payable processing further. They handle complex layouts, formats, and multiple languages and automatically export extracted data to accounting systems, databases, or spreadsheets for further analysis and processing.
With advancements like AI invoice processing, this workflow can be significantly optimized, reducing manual effort and increasing accuracy.
In this article, we'll explore what exactly is an invoice parser? How does it function? And most crucially, how can it benefit your business? Whether you're dealing with PDF invoices or scanned documents, an effective invoice parser can transform your AP workflows. Let’s get started.
What is an invoice parser?
An invoice parser is a type of software that is designed to read and interpret invoice documents. This can include PDFs, images and other types of files.
The purpose of an invoice parser is to extract key information from an invoice, such as the invoice id, total amount due, the invoice date, the customer name, and so on. Invoice parsers can help ensure accuracy by avoiding mistakes that can occur from manual data extraction.
This information can then be used for various purposes, such as AP automation, month-end close process in accounting, and invoice management.
Invoice parsers can be standalone programs or be integrated into larger business systems. These tools make it easier for teams to generate reports or export the data to other applications, such as Excel and are often used alongside other business management applications.
There are many different invoice parsing solutions available, so choosing one that meets your specific needs is essential.
The benefits of effective invoice parsing include:
- Significant time savings compared to manual processing
- Improved accuracy and reduced errors in data entry
- Enhanced productivity for accounting and finance teams
- Better cash flow management through faster invoice processing
- Easier detection of duplicate or fraudulent invoices
- Streamlined auditing and compliance processes
- Improved vendor relationships due to timely payments
- Scalability to handle large volumes of invoices efficiently
- Real-time data insights for better decision-making
- Reduced storage costs by eliminating the need for physical document storage
These advantages make invoice parsing an essential tool for businesses looking to optimize their financial operations.
Looking to automate your manual AP Processes? Book a 30-min live demo to see how Nanonets can help your team implement end-to-end AP automation.
How does an invoice parser work
To understand invoice parsers, it's helpful to first grasp the concept of parsers in general. Parsers are tools used to interpret and process documents written in specific markup languages. They break down documents into smaller pieces called tokens, then analyze each token to determine its meaning and how it fits into the overall structure of the document.
.webp)
This process requires a strong understanding of the language's grammar, allowing document parser to identify individual tokens and understand the relationships between them.
Invoice parsing applies these principles to extract relevant information from invoice documents.
Here's how the process typically works:
- Document input and OCR: The process begins with Optical Character Recognition (OCR). This crucial technology converts printed or handwritten text from invoices into machine-encoded text, allowing the system to "read" both digital and scanned paper invoices.
- AI and Machine Learning analysis: Once the text is digitized, AI and machine learning algorithms take center stage. These technologies analyze the identified text, extract key-value pairs such as invoice numbers and amounts, vendor names and addresses, or purchase order numbers and dates. What sets modern parsers apart is their ability to recognize patterns and learn from previous invoices, continuously improving accuracy over time.
- Data structuring and post-processing: After extraction, the data is organized into more readable formats like XML, HTML, JSON, or CSV. This structured data can then be used in various ways, from populating databases to generating reports.
- Workflow integration: Finally, businesses can build processes and workflows using the parsed invoice data, automating various aspects of their financial operations.
The power of invoice parsers lies in their ability to handle both digital and scanned invoices, learn from each document processed, and enable the automation of previously manual tasks. By transforming unstructured invoice data into structured, usable information, these tools are revolutionizing how businesses handle their financial documents.
Looking to automate your manual AP Processes? Book a 30-min live demo to see how Nanonets can help your team implement end-to-end AP automation.
Types of parsers
Invoice parsers come in various types, each designed to meet specific business needs. But broadly, we can categorize invoice parsers into two main types:
Rule-based parsers: These traditional systems rely on predefined rules to extract data. While effective for standardized invoices, they struggle with format variations.
AI-powered parsers: Leveraging machine learning, these advanced systems can handle diverse invoice layouts and adapt to new formats without manual intervention.
Now that we understand the basic principles, let's see how we can implement a simple invoice parser using Python. This practical example should help you build a simple rule-based invoice parser.
Invoice parsing with Python
Python is a programming language for various data extraction tasks, including invoice parsing. This section will teach you invoice data extraction using Python libraries.
Building a generic state-of-the-art invoice parser that can run on all data types is difficult, as it includes various tasks such as reading text, handling languages, fonts, document alignment, and extracting key-value pairs. However, with help from open-source projects and some ingenuity, we could at least solve a few of these problems and get started.
For example, we’ll use a tool called tabula on a sample invoice — a python library to extract tables for invoice parsing. To run the below code snippet, make sure both Python and tabula/tabulate are installed on the local machine.
from tabula import read_pdf
from tabulate import tabulate
# PDF file to extract tables from
file = "sample-invoice.pdf"
# extract all the tables in the PDF file
#reads table from pdf file
df = read_pdf(file ,pages="all") #address of pdf file
print(tabulate(df[0]))
print(tabulate(df[1]))
Output
- ------------ ----------------
0 Order Number 12345
1 Invoice Date January 25, 2016
2 Due Date January 31, 2016
3 Total Due $93.50
- ------------ ----------------
- - ------------------------------- ------ ----- ------
0 1 Web Design $85.00 0.00% $85.00
This is a sample description...
- - ------------------------------- ------ ----- ------This invoice recognition Python code can certainly extract the tables from a PDF file. But the PDF file you get may not always be so well-formatted, aligned, or electronically created. If the document had been captured by a camera instead of being digitally created, it would have been much harder for these algorithms to extract the data—this is where optical character recognition comes into play.
Let's use Tesseract, a popular OCR engine for Python, to parse through an invoice.
import cv2
import pytesseract
from pytesseract import Output
img = cv2.imread('sample-invoice.jpg')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
print(d.keys())
This should give you the following output -
dict_keys(['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text'])
Using this dictionary, we can get each word detected, their bounding box information, the text in them, and their confidence scores.
You can plot the boxes by using the code below -
n_boxes = len(d['text'])
for i in range(n_boxes):
if float(d['conf'][i]) > 60:
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
You’ll see the following output:

This invoice recognition Python code demonstrates how we can use and recognize the regions of an invoice. Effective invoice data extraction Python scripts like this can handle various document formats, from PDFs to scanned images. However, custom algorithms must be built for key-value pair extraction. We’ll learn more about this in the following sections.
Set up touchless AP workflows and streamline the Accounts Payable process in seconds. Book a 30-min live demo now.
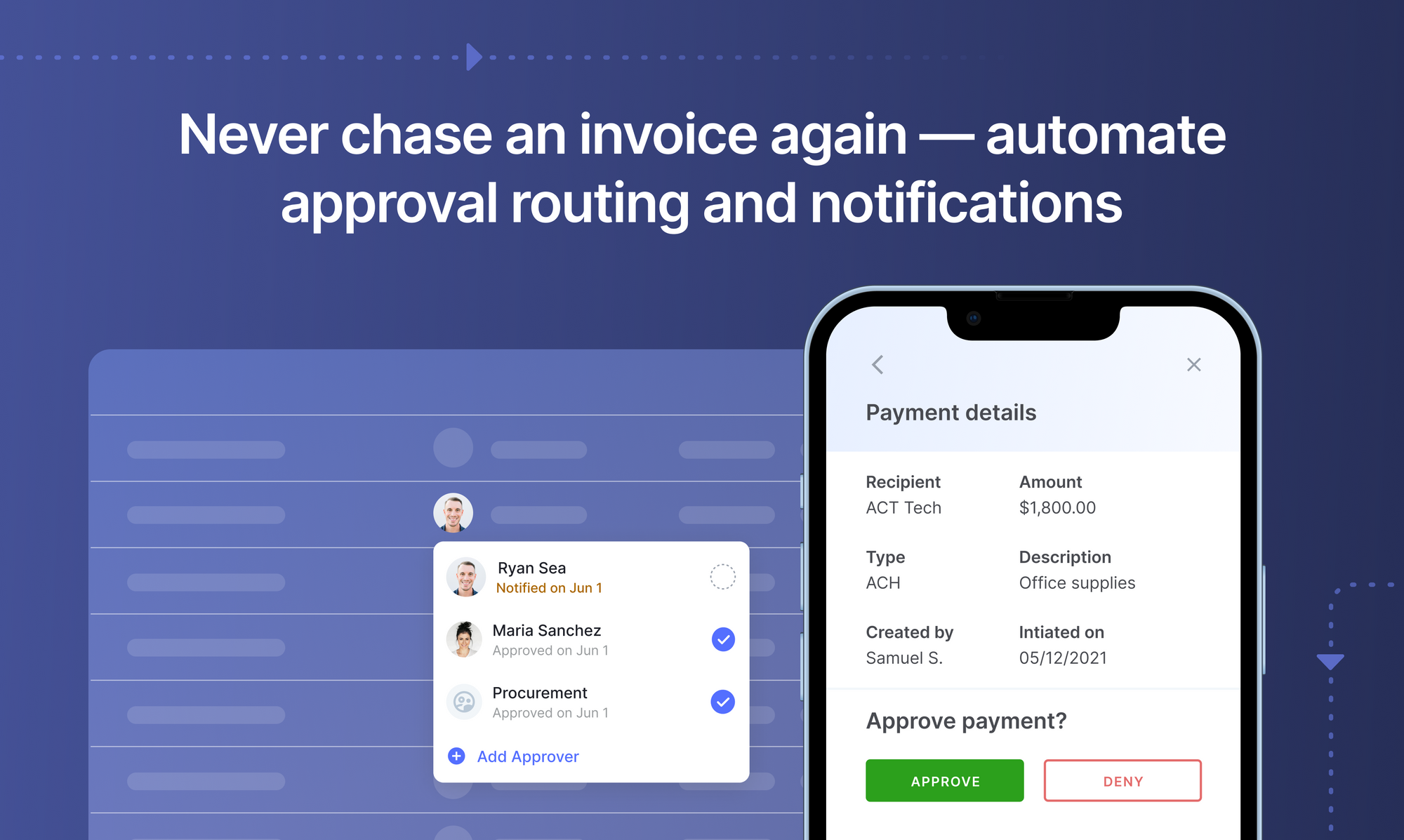
Challenges with legacy rule-based invoice parsers
Many organizations still rely on legacy systems for invoice data extraction. These rule-based" systems parse each line item on invoices and compare them against predefined rules to determine what information should be added to their database.
While this method has been used for a long time, it has several drawbacks:
- Page tilt while scanning: Rule-based invoice parsers struggle with "page tilt," where fields aren't positioned in a straight line. This makes it difficult to accurately identify and extract data, often caused by uneven printing or misaligned manual data input.
- Format change: Invoices that don't follow a standard format pose significant challenges. Different fonts, changing layouts, and new fields can confuse rule-based parsers, making it difficult to determine what each column represents.
- Table Extraction: Rule-based table extractors have limitations when dealing with tables lacking headers or containing null values. This can lead to processing loops and inaccurate data extraction, especially when tables span multiple pages.
Build an AI-based invoice parser with Nanonets
Invoice parsers with optical character recognition (OCR) and deep learning can extract data from invoices that have been scanned or converted to PDFs. This data can then populate accounting software, track expenses, and generate reports.
Deep learning algorithms can learn how to identify specific elements in an invoice, such as the customer's name, address, and product information. This allows for more accurate data extraction and can reduce the time needed to manually input data into a system. However, building such algorithms requires a lot of time and expertise, but don’t worry; Nanonets has your back!
Nanonets is an OCR software that uses artificial intelligence to automate the extraction of tables from PDF documents, images, and scanned files. Unlike other solutions, it doesn’t require separate rules and templates for each new document type. Instead, it relies on cognitive intelligence to handle semi-structured and unseen documents while improving over time. You can also customize the output to only extract tables or data entries of your interest.
Nanonets is equally adept at parsing receipts, making it a versatile solution for all your financial document needs. It's fast, accurate, and user-friendly. Plus, you can build custom OCR models from scratch if you want to get hands-on.
With Zapier integrations and a simple API, Nanonets fits right into your existing workflow. Digitize documents, extract data, and connect with your apps — all from one intuitive interface.
Why is Nanonets the best PDF parser?
.png)
- Nanonets can extract on-page data while command line PDF parsers only extract objects, headers & metadata such as (title, #pages, encryption status, etc.)
- Nanonets PDF parsing technology isn't template-based. Apart from offering pre-trained models for popular use cases, Nanonets PDF parsing algorithm can also handle unseen document types!
- Apart from handling native PDF documents, Nanonet's in-built OCR capabilities allow it to handle scanned documents and images as well!
- Robust automation features with AI and ML capabilities.
- Nanonets handle unstructured data, common data constraints, multi-page PDF documents, tables, and multi-line items with ease.
- Nanonets is a no-code tool that can continuously learn and re-train itself on custom data to provide outputs requiring no post-processing.
Book this 30-min live demo to make this the last time that you'll ever have to manually key in data from invoices or receipts into ERP software.
How businesses can use Nanonets to optimize their AP workflows
Let's explore how companies across various industries can leverage Nanonets invoice parsing to streamline their AP workflows:
.png)
1. Manufacturing company: For a mid-sized manufacturer, Nanonets invoice parser can help automatically extract data from incoming invoices, regardless of format, and match them against purchase orders and receipts.
This automated three-way matching significantly reduces manual intervention. The AP team needs to handle only exceptions flagged by the system, allowing them to focus on vendor relationships and financial strategy rather than data entry.
2. Retail chain: In a retail setting, Nanonets invoice parsing solution can integrate directly with inventory management systems, creating a seamless flow from invoice receipt to payment. The system can automatically categorize expenses, update inventory levels, and provide real-time spending insights.
This integration can transform vendor management, enabling data-driven decisions on supplier performance and optimizing the procurement process.
3. Global consulting firm: For international consulting firms, Nanonets can streamline expense management. The system can process receipts and invoices in various languages, automatically categorizing expenses and checking for policy compliance.
Integration with travel management and accounting software can create a smooth workflow from expense submission to reimbursement, significantly reducing processing time and improving accuracy in international expense reporting.
4. Healthcare provider: In a healthcare setting, Nanonets can optimize the billing workflow. The parser can extract detailed information from complex medical invoices and automatically code expenses to the correct departments and cost centers.
Integration with Electronic Health Record (EHR) systems can create a direct link between patient care and financial data. This streamlined process can provide real-time financial insights, enabling more informed decision-making and improved resource allocation across the board.
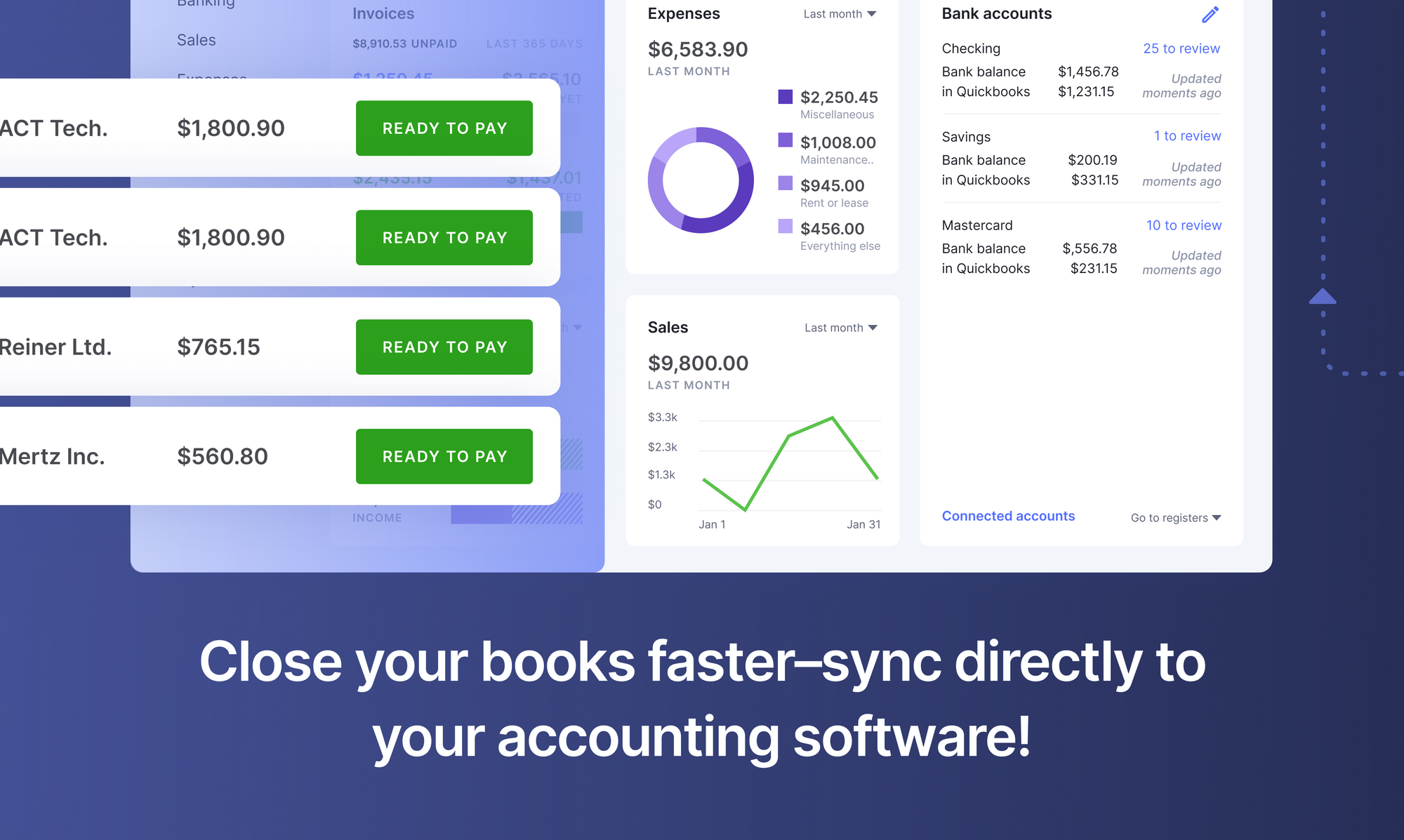
Automated invoice parsing with Nanonets
Integrate your existing tools with Nanonets and automate data collection, export storage, and bookkeeping.
.png)
Create completely touchless invoice processing workflows.
Nanonets can also help in automating invoice parsing workflows by:
- Importing and consolidating invoice data from multiple sources - email, scanned documents, digital files/images, cloud storage, ERP, API, etc.
- Capturing and extracting invoice data intelligently from invoices, receipts, bills, and other financial documents.
- Extracting data from barcodes or QR codes
- Categorizing and coding transactions based on business rules.
- Setting up automated approval workflows to get internal approvals and manage exceptions.
- Reconciling all transactions
- Integrating seamlessly with ERPs or accounting software such as Quickbooks, Sage, Xero, Netsuite, and more.
FAQs
What is an invoice parser?
An invoice parser is a tool that automatically extracts critical data from invoices. It uses OCR and AI technologies to read and interpret invoice numbers, dates, amounts, and vendor details from various invoice formats, eliminating manual data entry.
How do I extract data from an invoice?
To extract data from an invoice, use an invoice parser or API. These tools automatically read the invoice, identify important fields, and extract the relevant data. For a DIY approach, you can use Python libraries like Pytesseract OCR, combined with regular expressions to locate specific data points
How to automate invoice processing?
Automate invoice processing by implementing an invoice parsing solution. Start by choosing software that integrates with your existing systems. Set up automated workflows for receiving invoices, extracting data, matching with purchase orders, and approving payments. Finally, integrate the parsed data with your accounting or ERP system for seamless processing.
What is invoice processing software?
Invoice processing software is a tool that automates the entire invoice management workflow. It typically includes features for receiving invoices, data extraction, validation, approval routing, and payment processing. Advanced solutions offer AI-powered data capture, three-way matching, and integration with accounting systems to streamline accounts payable operations.