
In the era of big data, managing and retrieving documents efficiently is crucial for businesses of all sizes. Many corporations that have shifted from paper to computer-based filing procedures have understood that digital files can be as disorganized and messy as analog ones. However, digitizing documents saves a lot of effort and time in the long run; it only functions if done correctly. That is where document indexing arrives.
Document indexing is an excellent way to enable your corporation to get your digital files organized and save future files organized. It also pertains to files involved in procedures across your institution, from accounts receivable and accounts payable to procure-to-pay.
What Is Document Indexing?

Document Indexing ensures quick document retrieval without sifting through vast unstructured data. For instance, a firm might index documents by customer number, client name, employee name, date, or other key details. This forms the core of an organization's document management system.
Consider a dictionary: finding a word by flipping through every page would be time-consuming. The index of documents allows you to locate a word in seconds. Similarly, indexing document attaches tags to a digital document enabling swift searches eliminating the need to manually sift through numerous files.
How to Index Documents?
Document indexing transforms a unorganised collection of documents into a structured, searchable database.
Imagine you have three invoices from different vendors, as shown in the image below. Let's deep dive into how to index these documents:
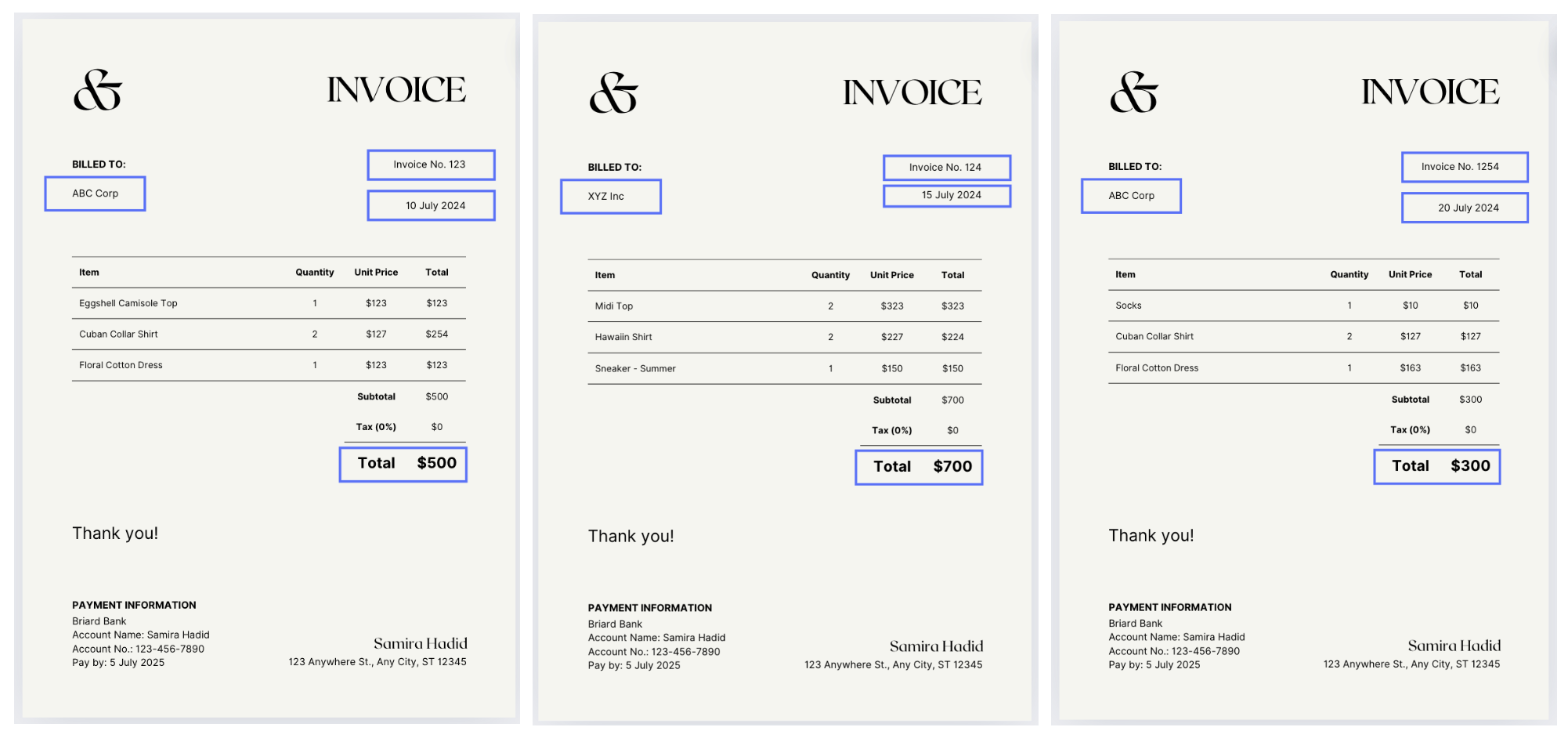
1. Define Indexing Requirements and Purpose
Identify key fields in the document, like invoice number, dates, client name, or total amount (highlighted in blue boxes). These create unique “addresses” for efficient retrieval. Consider who will access these documents and their purposes, whether for reference by employees or analysis by specific teams, to shape your indexing document strategy.
2. Add Metadata
Incorporate metadata to provide additional information about each document, such as the scanning date, the operator, or departmental details. Metadata enhances the search-ability and contextual understanding of documents.
3. Choose Indexing Method:
- Manual Indexing: Involves detailed tagging by humans, ideal for complex documents requiring careful judgment. It ensures high accuracy and is crucial for precise fields.
- Automated Indexing: Uses OCR technology to quickly scan and categorize documents based on rules. Best for large volumes of standard documents, reducing human error, but works best with clear, well-structured content.
Example of index creation from the above documents:
- "Invoice Number 123": Invoice A
- "Date July 10, 2024": Invoice A
- "Vendor ABC Corp": Invoice A, Invoice C
- "Amount $500": Invoice A
4. Validate Indexing Accuracy
Implement a validation process where multiple operators tag documents based on identified fields. Compare results to detect and correct discrepancies, ensuring the accuracy and reliability of the indexed data.
5. Store and Manage Documents
Store indexed documents in electronic records management systems or digital repositories. These systems feature advanced search functions that leverage the indexes and metadata to enable quick and efficient retrieval. Regularly maintain the system to update indexes, add new documents, and manage document lifecycle according to organizational policies.
Example of search and retrieval:
- Search "Vendor ABC Corp" returns Invoice A and Invoice C.
- Search "Amount $500" returns Invoice A.
By following these steps, you can optimize your document indexing process, making information retrieval faster and more effective.
Indexing of documents enhances the management of documents (here invoices) by creating an organized system for retrieving and sorting them. With effective indexing of documents, you can easily locate and manage your documents, improving overall efficiency and accuracy.
Types of Document Indexing
There are many different indexing approaches, so you can choose whatever one (or a combination of ways) best suits your document workflow. These strategies consist of the following:
Full-Text Indexing
Full-text indexing scans the entire document, enabling searches for any phrase or keyword, much like the "Find" tool (Ctrl+F or Cmd+F) in word processors and browsers. It's user-friendly and efficient, though it does require substantial storage space.
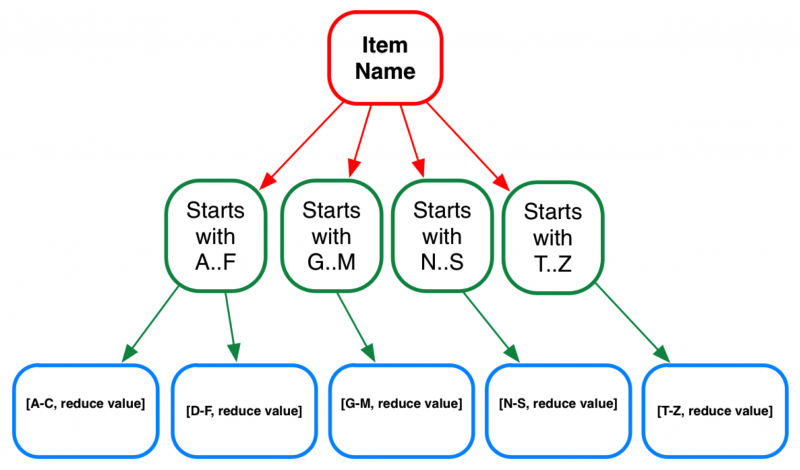
Automated Indexing using Data Variables Lookup Indexing
Automated indexing, or variable lookup indexing, targets key sections of a document—like customer numbers or names—rather than the whole page. Using specialized software, this approach is especially useful for businesses dealing with documents like bills, where fields consistently match database entries.
Metadata Indexing
"Data about data" is a term that's frequently used to refer to metadata, but it's very detailed. For example, when capturing images for a PDF, metadata includes details like the timestamp and allows you to add tags. These tags help in organizing and quickly retrieving documents later by scanning metadata instead of the entire content.
Geospatial Indexing
Geospatial indexing arranges data by geographical attributes, making it essential for location-based applications like GIS and mapping services. It streamlines querying and retrieving location-specific information, helping you find nearby services and analyze spatial patterns quickly.
Keyword Indexing
Keyword indexing involves extracting and indexing specific keywords from documents for quick retrieval. Commonly used in search engines, this method allows for rapid identification of documents containing particular words or phrases, supporting various search functionalities like exact match and Boolean searches.
Field-Based Indexing
Field-based indexing indexes data based on specific fields within a document or database, such as customer names or dates. This method enables precise querying based on field values, making it beneficial for structured data where specific attributes are regularly queried.
Conceptual Indexing
Conceptual indexing of documents uses advanced algorithms to understand the underlying concepts and relationships within the content, going beyond keyword matching. It captures the meaning and context of the content, providing more accurate and relevant search results, especially useful for academic research and knowledge management systems.
Why Document Indexing Is Important?
Document indexing enables more than just quick document retrieval. There are many advantages to document indexing, including the following:
Enhanced Document Organization
Employees can save time searching for the right document with the right document indexing system.
Easier audit compliance
You may easily dispense with the scramble to gather papers in time for an audit if the documents are already indexed and organized according to the fiscal year and other pertinent metrics.
Saves time
Nanonets - The best Document Indexing Software
When it comes to document indexing, Nanonets stands out as a premier solution for optimizing enterprise content management. Leveraging advanced OCR technology, Nanonets transforms file chaos into organized, easily accessible information across departments such as accounts payable, accounts receivable, and customer support. Its robust document indexing capabilities streamline business processes, ensuring that every document is efficiently indexed and retrievable with minimal effort.
Nanonets' user-friendly interface and powerful features make it an indispensable tool for enhancing productivity and improving document management. Discover how Nanonets can revolutionize your document indexing by requesting a demo today and see firsthand how it can simplify and elevate your business operations.
See how you can automate your Document indexing process with Nanonets in 15 minutes.
Get a free product tour or try it yourself.
Conclusion
In conclusion, document indexing is a vital process that enhances data management efficiency and retrieval speed. By understanding the fundamentals of document indexing, including its various types and implementation methods, you can significantly improve your organization's data handling capabilities. Effective document indexing not only simplifies access to critical information but also supports better compliance, productivity, and cost savings. As we've explored, integrating robust indexing strategies into your document management system is essential for optimizing information flow and maximizing operational efficiency. Embrace document indexing to streamline your processes, enhance searchability, and stay ahead in today's data-driven landscape.